 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Measuring Diversity and Quality in Text Generation Models
Paper and Code

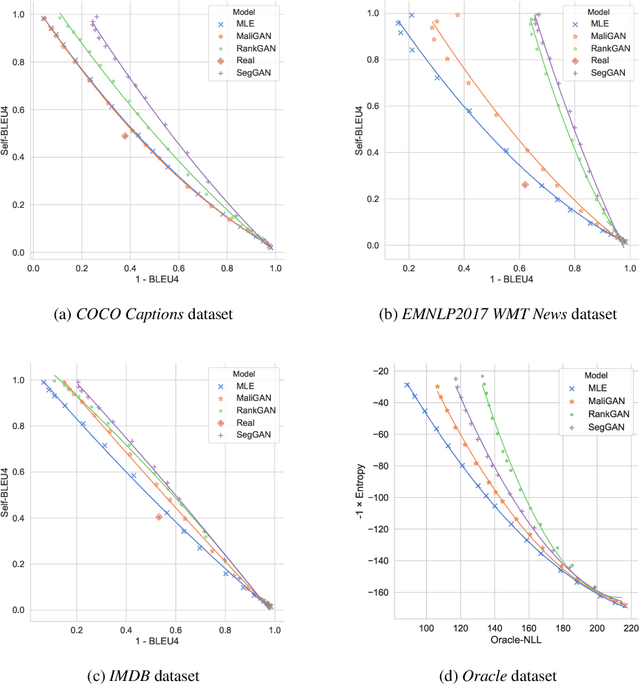

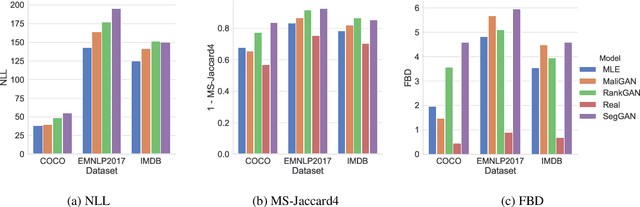
Text generation is an important Natural Language Processing task with various applications. Although several metrics have already been introduced to evaluate the text generation methods, each of them has its own shortcomings. The most widely used metrics such as BLEU only consider the quality of generated sentences and neglect their diversity. For example, repeatedly generation of only one high quality sentence would result in a high BLEU score. On the other hand, the more recent metric introduced to evaluate the diversity of generated texts known as Self-BLEU ignores the quality of generated texts. In this paper, we propose metrics to evaluate both the quality and diversity simultaneously by approximating the distance of the learned generative model and the real data distribution. For this purpose, we first introduce a metric that approximates this distance using n-gram based measures. Then, a feature-based measure which is based on a recent highly deep model trained on a large text corpus called BERT is introduced. Finally, for oracle training mode in which the generator's density can also be calculated, we propose to use the distance measures between the corresponding explicit distributions. Eventually, the most popular and recent text generation models are evaluated using both the existing and the proposed metrics and the preferences of the proposed metrics are determined.