 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robustness and Reliability of Benchmark-Based Evaluation of LLMs
Sep 04, 2025Large Language Models (LLMs) effectiveness is usually evaluated by means of benchmarks such as MMLU, ARC-C, or HellaSwag, where questions are presented in their original wording, thus in a fixed, standardized format. However, real-world applications involve linguistic variability, requiring models to maintain their effectiveness across diverse rewordings of the same question or query. In this study, we systematically assess the robustness of LLMs to paraphrased benchmark questions and investigate whether benchmark-based evaluations provide a reliable measure of model capabilities. We systematically generate various paraphrases of all the questions across six different common benchmarks, and measure the resulting variations in effectiveness of 34 state-of-the-art LLMs, of different size and effectiveness. Our findings reveal that while LLM rankings remain relatively stable across paraphrased inputs, absolute effectiveness scores change, and decline significantly. This suggests that LLMs struggle with linguistic variability, raising concerns about their generalization abilities and evaluation methodologies. Furthermore, the observed performance drop challenges the reliability of benchmark-based evaluations, indicating that high benchmark scores may not fully capture a model's robustness to real-world input variations. We discuss the implications of these findings for LLM evaluation methodologies, emphasizing the need for robustness-aware benchmarks that better reflect practical deployment scenarios.
HEROHE Challenge: assessing HER2 status in breast cancer without immunohistochemistry or in situ hybridization
Nov 08, 2021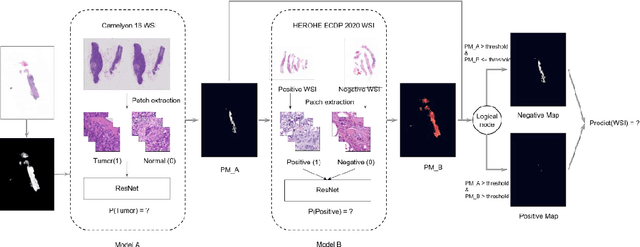
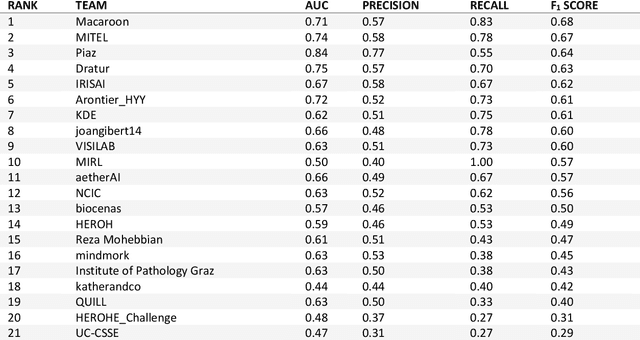
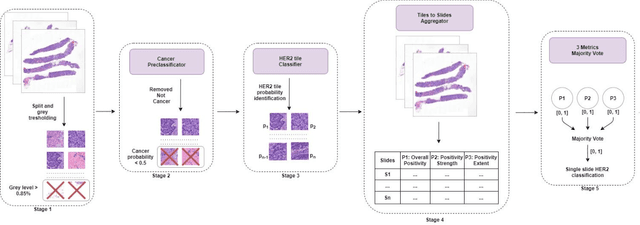
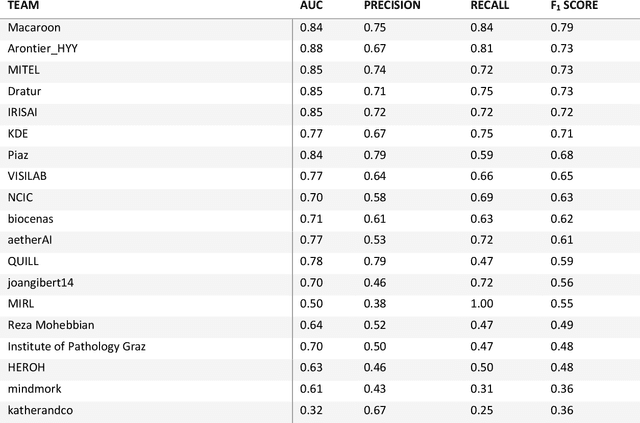
Breast cancer is the most common malignancy in women, being responsible for more than half a million deaths every year. As such, early and accurate diagnosis is of paramount importance. Human expertise is required to diagnose and correctly classify breast cancer and define appropriate therapy, which depends on the evaluation of the expression of different biomarkers such as the transmembrane protein receptor HER2. This evaluation requires several steps, including special techniques such as immunohistochemistry or in situ hybridization to assess HER2 status. With the goal of reducing the number of steps and human bias in diagnosis, the HEROHE Challenge was organized, as a parallel event of the 16th European Congress on Digital Pathology, aiming to automate the assessment of the HER2 status based only on hematoxylin and eosin stained tissue sample of invasive breast cancer. Methods to assess HER2 status were presented by 21 teams worldwide and the results achieved by some of the proposed methods open potential perspectives to advance the state-of-the-art.
Can the Crowd Judge Truthfulness? A Longitudinal Study on Recent Misinformation about COVID-19
Jul 25, 2021
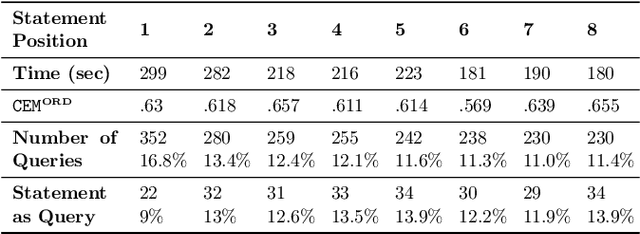
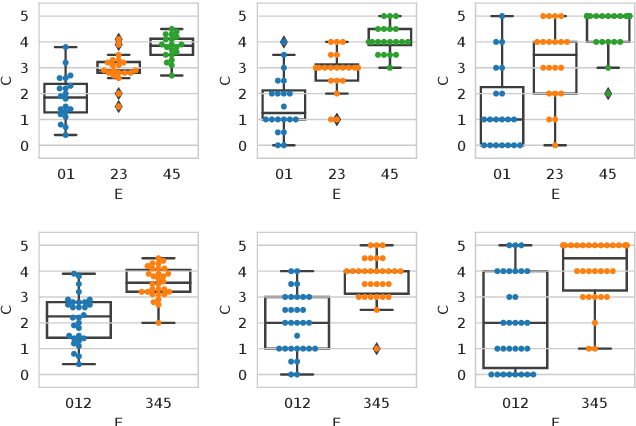
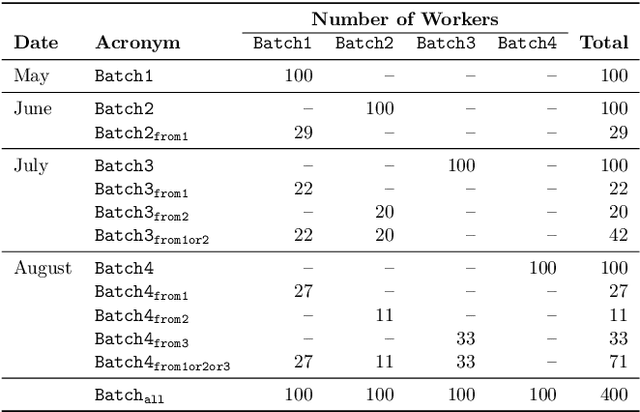
Recently, the misinformation problem has been addressed with a crowdsourcing-based approach: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of non-expert is exploited. We study whether crowdsourcing is an effective and reliable method to assess truthfulness during a pandemic, targeting statements related to COVID-19, thus addressing (mis)information that is both related to a sensitive and personal issue and very recent as compared to when the judgment is done. In our experiments, crowd workers are asked to assess the truthfulness of statements, and to provide evidence for the assessments. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we report results on workers behavior, agreement among workers, effect of aggregation functions, of scales transformations, and of workers background and bias. We perform a longitudinal study by re-launching the task multiple times with both novice and experienced workers, deriving important insights on how the behavior and quality change over time. Our results show that: workers are able to detect and objectively categorize online (mis)information related to COVID-19; both crowdsourced and expert judgments can be transformed and aggregated to improve quality; worker background and other signals (e.g., source of information, behavior) impact the quality of the data. The longitudinal study demonstrates that the time-span has a major effect on the quality of the judgments, for both novice and experienced workers. Finally, we provide an extensive failure analysis of the statements misjudged by the crowd-workers.
The COVID-19 Infodemic: Can the Crowd Judge Recent Misinformation Objectively?
Aug 13, 2020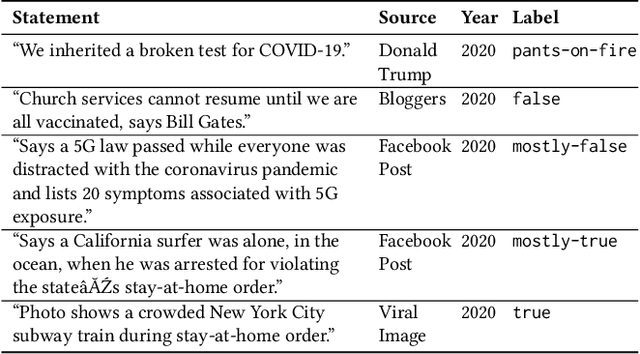

Misinformation is an ever increasing problem that is difficult to solve for the research community and has a negative impact on the society at large. Very recently, the problem has been addressed with a crowdsourcing-based approach to scale up labeling efforts: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of (non-expert) judges is exploited. We follow the same approach to study whether crowdsourcing is an effective and reliable method to assess statements truthfulness during a pandemic. We specifically target statements related to the COVID-19 health emergency, that is still ongoing at the time of the study and has arguably caused an increase of the amount of misinformation that is spreading online (a phenomenon for which the term "infodemic" has been used). By doing so, we are able to address (mis)information that is both related to a sensitive and personal issue like health and very recent as compared to when the judgment is done: two issues that have not been analyzed in related work. In our experiment, crowd workers are asked to assess the truthfulness of statements, as well as to provide evidence for the assessments as a URL and a text justification. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we also report results on many different aspects, including: agreement among workers, the effect of different aggregation functions, of scales transformations, and of workers background / bias. We also analyze workers behavior, in terms of queries submitted, URLs found / selected, text justifications, and other behavioral data like clicks and mouse actions collected by means of an ad hoc logger.