 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Encoding and Quantization to Enhance Quanvolutional Neural Networks
Oct 08, 2024
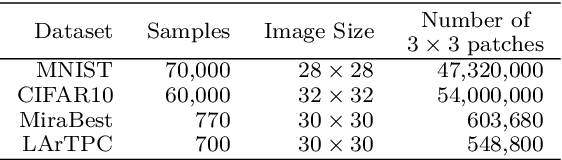


Image processing is one of the most promising applications for quantum machine learning (QML). Quanvolutional Neural Networks with non-trainable parameters are the preferred solution to run on current and near future quantum devices. The typical input preprocessing pipeline for quanvolutional layers comprises of four steps: optional input binary quantization, encoding classical data into quantum states, processing the data to obtain the final quantum states, decoding quantum states back to classical outputs. In this paper we propose two ways to enhance the efficiency of quanvolutional models. First, we propose a flexible data quantization approach with memoization, applicable to any encoding method. This allows us to increase the number of quantization levels to retain more information or lower them to reduce the amount of circuit executions. Second, we introduce a new integrated encoding strategy, which combines the encoding and processing steps in a single circuit. This method allows great flexibility on several architectural parameters (e.g., number of qubits, filter size, and circuit depth) making them adjustable to quantum hardware requirements. We compare our proposed integrated model with a classical convolutional neural network and the well-known rotational encoding method, on two different classification tasks. The results demonstrate that our proposed model encoding exhibits a comparable or superior performance to the other models while requiring fewer quantum resources.
Boosting Adverse Drug Event Normalization on Social Media: General-Purpose Model Initialization and Biomedical Semantic Text Similarity Benefit Zero-Shot Linking in Informal Contexts
Jul 31, 2023


Biomedical entity linking, also known as biomedical concept normalization, has recently witnessed the rise to prominence of zero-shot contrastive models. However, the pre-training material used for these models has, until now, largely consisted of specialist biomedical content such as MIMIC-III clinical notes (Johnson et al., 2016) and PubMed papers (Sayers et al., 2021; Gao et al., 2020). While the resulting in-domain models have shown promising results for many biomedical tasks, adverse drug event normalization on social media texts has so far remained challenging for them (Portelli et al., 2022). In this paper, we propose a new approach for adverse drug event normalization on social media relying on general-purpose model initialization via BioLORD (Remy et al., 2022) and a semantic-text-similarity fine-tuning named STS. Our experimental results on several social media datasets demonstrate the effectiveness of our proposed approach, by achieving state-of-the-art performance. Based on its strong performance across all the tested datasets, we believe this work could emerge as a turning point for the task of adverse drug event normalization on social media and has the potential to serve as a benchmark for future research in the field.
AILAB-Udine@SMM4H 22: Limits of Transformers and BERT Ensembles
Sep 07, 2022

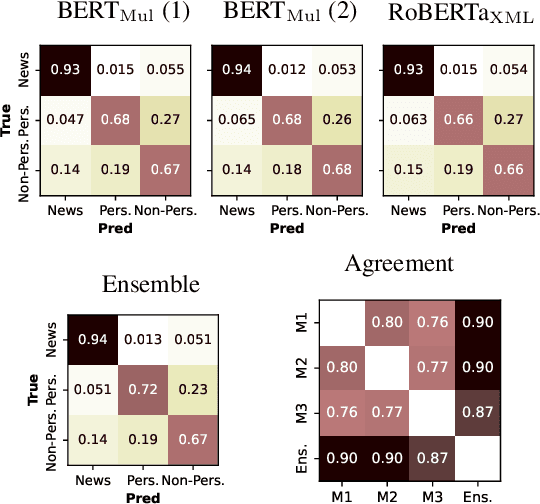

This paper describes the models developed by the AILAB-Udine team for the SMM4H 22 Shared Task. We explored the limits of Transformer based models on text classification, entity extraction and entity normalization, tackling Tasks 1, 2, 5, 6 and 10. The main take-aways we got from participating in different tasks are: the overwhelming positive effects of combining different architectures when using ensemble learning, and the great potential of generative models for term normalization.
Increasing Adverse Drug Events extraction robustness on social media: case study on negation and speculation
Sep 06, 2022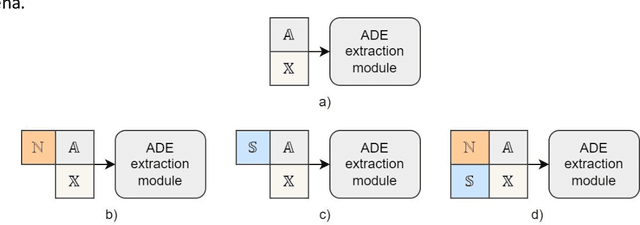
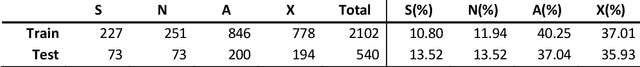
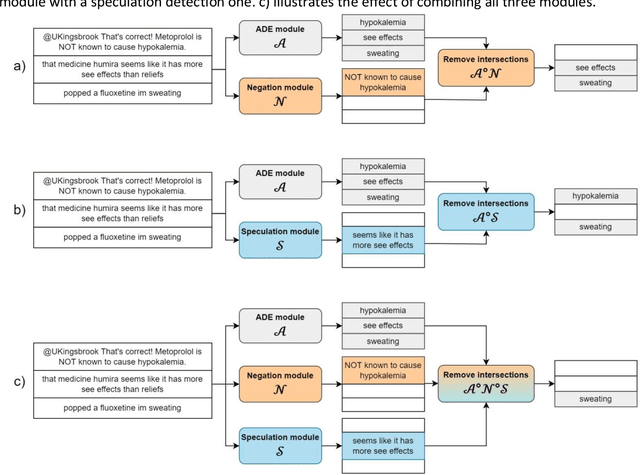
In the last decade, an increasing number of users have started reporting Adverse Drug Events (ADE) on social media platforms, blogs, and health forums. Given the large volume of reports, pharmacovigilance has focused on ways to use Natural Language Processing (NLP) techniques to rapidly examine these large collections of text, detecting mentions of drug-related adverse reactions to trigger medical investigations. However, despite the growing interest in the task and the advances in NLP, the robustness of these models in face of linguistic phenomena such as negations and speculations is an open research question. Negations and speculations are pervasive phenomena in natural language, and can severely hamper the ability of an automated system to discriminate between factual and nonfactual statements in text. In this paper we take into consideration four state-of-the-art systems for ADE detection on social media texts. We introduce SNAX, a benchmark to test their performance against samples containing negated and speculated ADEs, showing their fragility against these phenomena. We then introduce two possible strategies to increase the robustness of these models, showing that both of them bring significant increases in performance, lowering the number of spurious entities predicted by the models by 60% for negation and 80% for speculations.
NADE: A Benchmark for Robust Adverse Drug Events Extraction in Face of Negations
Sep 24, 2021
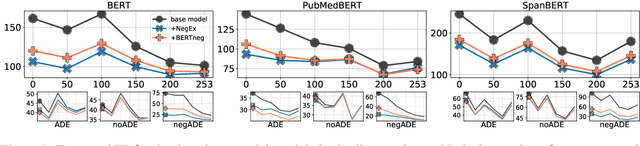
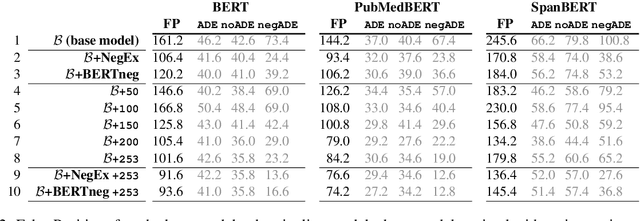
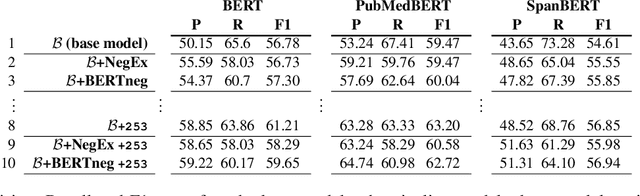
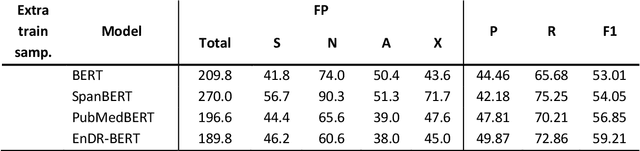
Adverse Drug Event (ADE) extraction models can rapidly examine large collections of social media texts, detecting mentions of drug-related adverse reactions and trigger medical investigations. However, despite the recent advances in NLP, it is currently unknown if such models are robust in face of negation, which is pervasive across language varieties. In this paper we evaluate three state-of-the-art systems, showing their fragility against negation, and then we introduce two possible strategies to increase the robustness of these models: a pipeline approach, relying on a specific component for negation detection; an augmentation of an ADE extraction dataset to artificially create negated samples and further train the models. We show that both strategies bring significant increases in performance, lowering the number of spurious entities predicted by the models. Our dataset and code will be publicly released to encourage research on the topic.
Can the Crowd Judge Truthfulness? A Longitudinal Study on Recent Misinformation about COVID-19
Jul 25, 2021
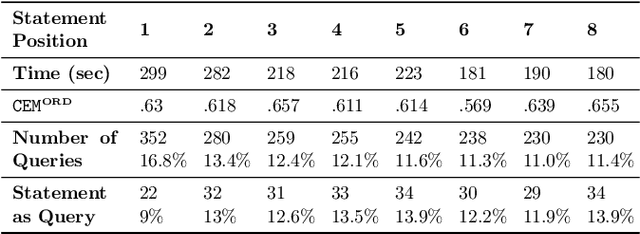
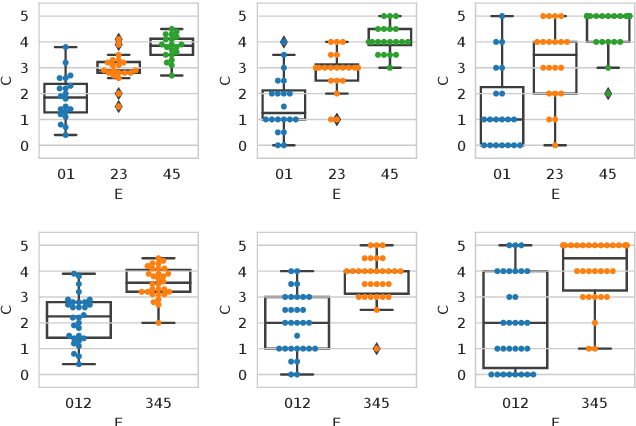
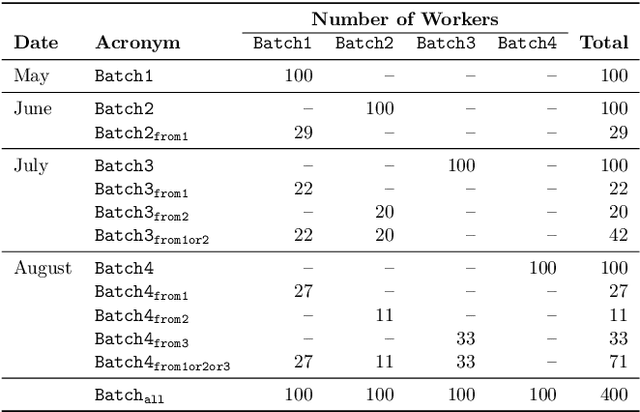
Recently, the misinformation problem has been addressed with a crowdsourcing-based approach: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of non-expert is exploited. We study whether crowdsourcing is an effective and reliable method to assess truthfulness during a pandemic, targeting statements related to COVID-19, thus addressing (mis)information that is both related to a sensitive and personal issue and very recent as compared to when the judgment is done. In our experiments, crowd workers are asked to assess the truthfulness of statements, and to provide evidence for the assessments. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we report results on workers behavior, agreement among workers, effect of aggregation functions, of scales transformations, and of workers background and bias. We perform a longitudinal study by re-launching the task multiple times with both novice and experienced workers, deriving important insights on how the behavior and quality change over time. Our results show that: workers are able to detect and objectively categorize online (mis)information related to COVID-19; both crowdsourced and expert judgments can be transformed and aggregated to improve quality; worker background and other signals (e.g., source of information, behavior) impact the quality of the data. The longitudinal study demonstrates that the time-span has a major effect on the quality of the judgments, for both novice and experienced workers. Finally, we provide an extensive failure analysis of the statements misjudged by the crowd-workers.
Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies
May 19, 2021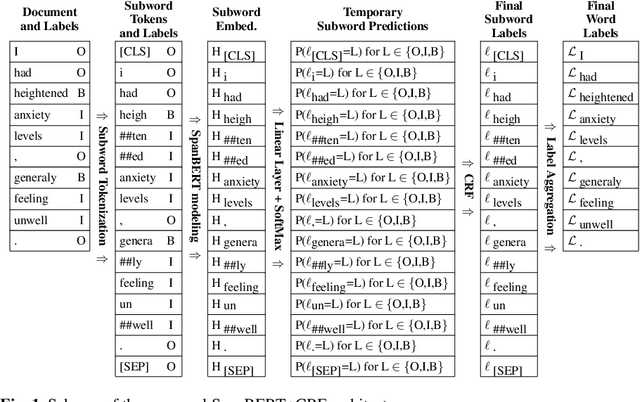
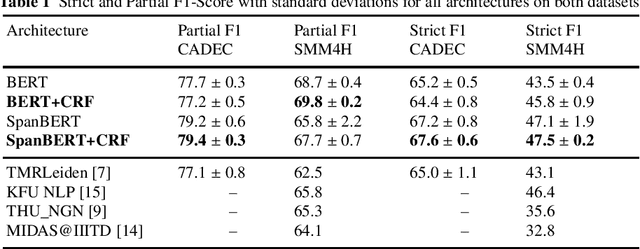
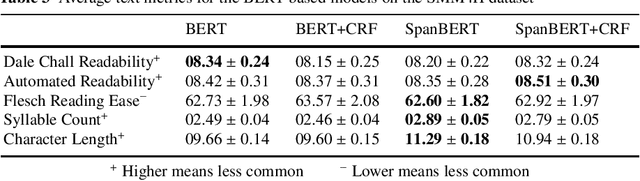
In recent years, Internet users are reporting Adverse Drug Events (ADE) on social media, blogs and health forums. Because of the large volume of reports, pharmacovigilance is seeking to resort to NLP to monitor these outlets. We propose for the first time the use of the SpanBERT architecture for the task of ADE extraction: this new version of the popular BERT transformer showed improved capabilities with multi-token text spans. We validate our hypothesis with experiments on two datasets (SMM4H and CADEC) with different text typologies (tweets and blog posts), finding that SpanBERT combined with a CRF outperforms all the competitors on both of them.
The COVID-19 Infodemic: Can the Crowd Judge Recent Misinformation Objectively?
Aug 13, 2020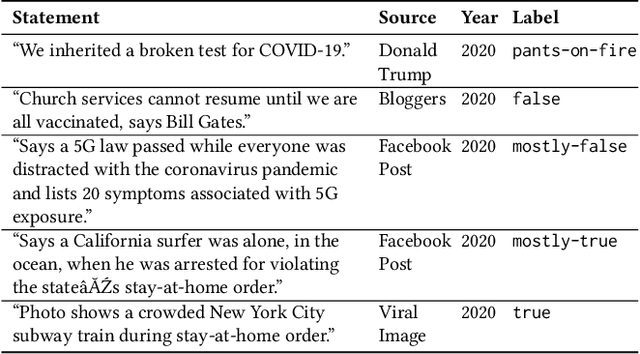

Misinformation is an ever increasing problem that is difficult to solve for the research community and has a negative impact on the society at large. Very recently, the problem has been addressed with a crowdsourcing-based approach to scale up labeling efforts: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of (non-expert) judges is exploited. We follow the same approach to study whether crowdsourcing is an effective and reliable method to assess statements truthfulness during a pandemic. We specifically target statements related to the COVID-19 health emergency, that is still ongoing at the time of the study and has arguably caused an increase of the amount of misinformation that is spreading online (a phenomenon for which the term "infodemic" has been used). By doing so, we are able to address (mis)information that is both related to a sensitive and personal issue like health and very recent as compared to when the judgment is done: two issues that have not been analyzed in related work. In our experiment, crowd workers are asked to assess the truthfulness of statements, as well as to provide evidence for the assessments as a URL and a text justification. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we also report results on many different aspects, including: agreement among workers, the effect of different aggregation functions, of scales transformations, and of workers background / bias. We also analyze workers behavior, in terms of queries submitted, URLs found / selected, text justifications, and other behavioral data like clicks and mouse actions collected by means of an ad hoc logger.