 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Adverse Drug Events extraction robustness on social media: case study on negation and speculation
Paper and Code
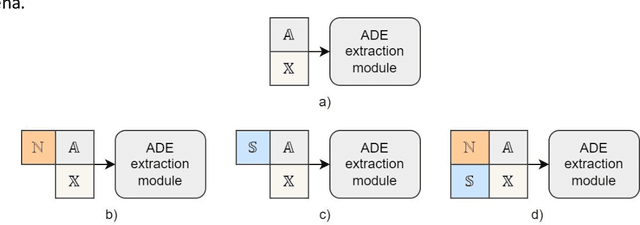
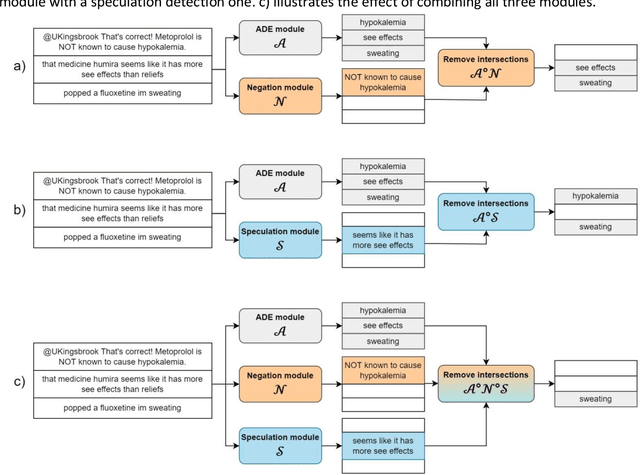
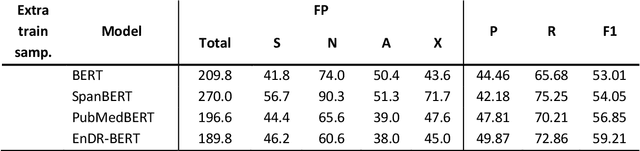
In the last decade, an increasing number of users have started reporting Adverse Drug Events (ADE) on social media platforms, blogs, and health forums. Given the large volume of reports, pharmacovigilance has focused on ways to use Natural Language Processing (NLP) techniques to rapidly examine these large collections of text, detecting mentions of drug-related adverse reactions to trigger medical investigations. However, despite the growing interest in the task and the advances in NLP, the robustness of these models in face of linguistic phenomena such as negations and speculations is an open research question. Negations and speculations are pervasive phenomena in natural language, and can severely hamper the ability of an automated system to discriminate between factual and nonfactual statements in text. In this paper we take into consideration four state-of-the-art systems for ADE detection on social media texts. We introduce SNAX, a benchmark to test their performance against samples containing negated and speculated ADEs, showing their fragility against these phenomena. We then introduce two possible strategies to increase the robustness of these models, showing that both of them bring significant increases in performance, lowering the number of spurious entities predicted by the models by 60% for negation and 80% for speculations.