 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting the Market? A Large-Scale Meta-Analysis of GenAI in Finance NLP (2022-2025)
Sep 11, 2025



Large Language Models (LLMs) have rapidly reshaped financial NLP, enabling new tasks and driving a proliferation of datasets and diversification of data sources. Yet, this transformation has outpaced traditional surveys. In this paper, we present MetaGraph, a generalizable methodology for extracting knowledge graphs from scientific literature and analyzing them to obtain a structured, queryable view of research trends. We define an ontology for financial NLP research and apply an LLM-based extraction pipeline to 681 papers (2022-2025), enabling large-scale, data-driven analysis. MetaGraph reveals three key phases: early LLM adoption and task/dataset innovation; critical reflection on LLM limitations; and growing integration of peripheral techniques into modular systems. This structured view offers both practitioners and researchers a clear understanding of how financial NLP has evolved - highlighting emerging trends, shifting priorities, and methodological shifts-while also demonstrating a reusable approach for mapping scientific progress in other domains.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Extensive Evaluation of Transformer-based Architectures for Adverse Drug Events Extraction
Jun 08, 2023



Adverse Event (ADE) extraction is one of the core tasks in digital pharmacovigilance, especially when applied to informal texts. This task has been addressed by the Natural Language Processing community using large pre-trained language models, such as BERT. Despite the great number of Transformer-based architectures used in the literature, it is unclear which of them has better performances and why. Therefore, in this paper we perform an extensive evaluation and analysis of 19 Transformer-based models for ADE extraction on informal texts. We compare the performance of all the considered models on two datasets with increasing levels of informality (forums posts and tweets). We also combine the purely Transformer-based models with two commonly-used additional processing layers (CRF and LSTM), and analyze their effect on the models performance. Furthermore, we use a well-established feature importance technique (SHAP) to correlate the performance of the models with a set of features that describe them: model category (AutoEncoding, AutoRegressive, Text-to-Text), pretraining domain, training from scratch, and model size in number of parameters. At the end of our analyses, we identify a list of take-home messages that can be derived from the experimental data.
AILAB-Udine@SMM4H 22: Limits of Transformers and BERT Ensembles
Sep 07, 2022

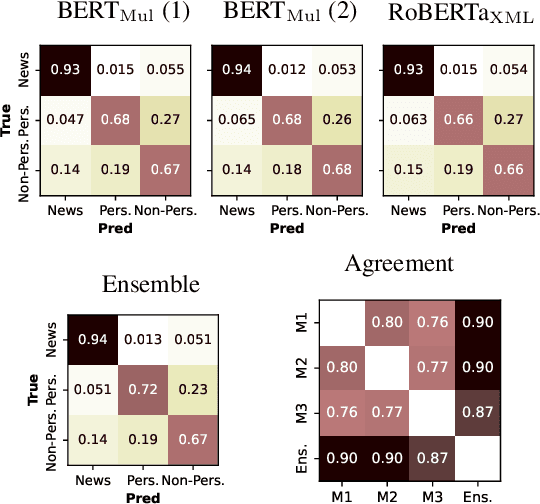

This paper describes the models developed by the AILAB-Udine team for the SMM4H 22 Shared Task. We explored the limits of Transformer based models on text classification, entity extraction and entity normalization, tackling Tasks 1, 2, 5, 6 and 10. The main take-aways we got from participating in different tasks are: the overwhelming positive effects of combining different architectures when using ensemble learning, and the great potential of generative models for term normalization.
Increasing Adverse Drug Events extraction robustness on social media: case study on negation and speculation
Sep 06, 2022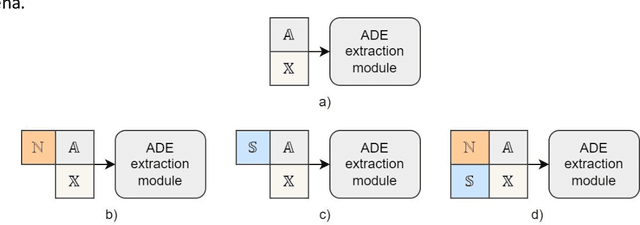
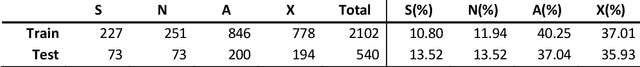
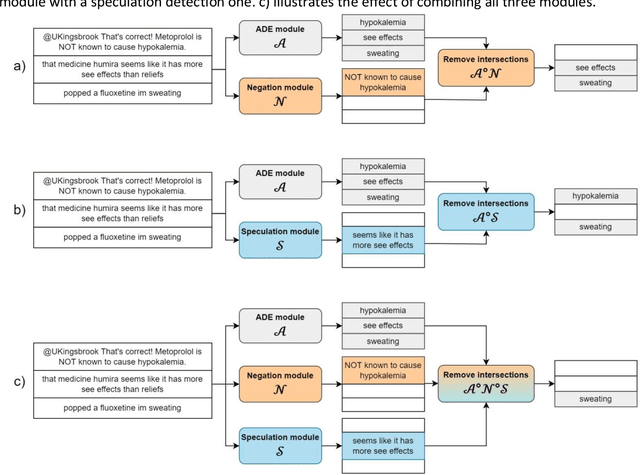
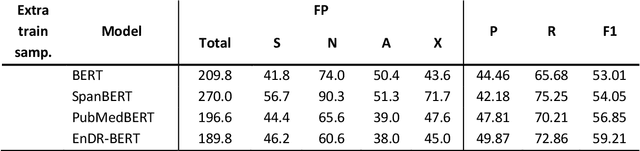
In the last decade, an increasing number of users have started reporting Adverse Drug Events (ADE) on social media platforms, blogs, and health forums. Given the large volume of reports, pharmacovigilance has focused on ways to use Natural Language Processing (NLP) techniques to rapidly examine these large collections of text, detecting mentions of drug-related adverse reactions to trigger medical investigations. However, despite the growing interest in the task and the advances in NLP, the robustness of these models in face of linguistic phenomena such as negations and speculations is an open research question. Negations and speculations are pervasive phenomena in natural language, and can severely hamper the ability of an automated system to discriminate between factual and nonfactual statements in text. In this paper we take into consideration four state-of-the-art systems for ADE detection on social media texts. We introduce SNAX, a benchmark to test their performance against samples containing negated and speculated ADEs, showing their fragility against these phenomena. We then introduce two possible strategies to increase the robustness of these models, showing that both of them bring significant increases in performance, lowering the number of spurious entities predicted by the models by 60% for negation and 80% for speculations.
NADE: A Benchmark for Robust Adverse Drug Events Extraction in Face of Negations
Sep 24, 2021
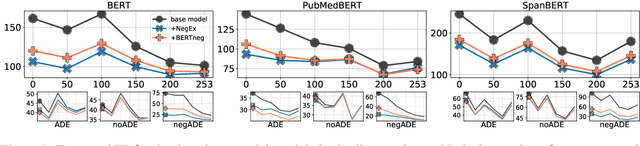
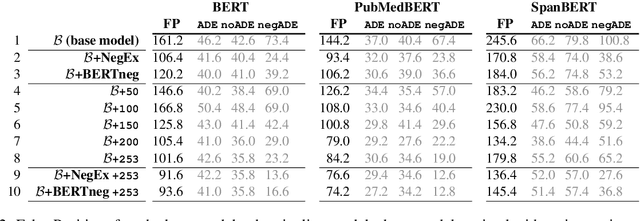
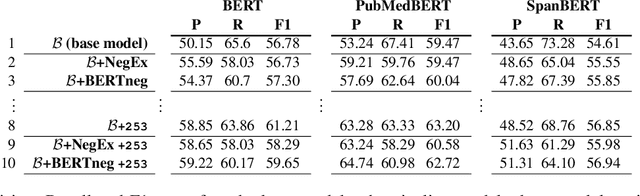
Adverse Drug Event (ADE) extraction models can rapidly examine large collections of social media texts, detecting mentions of drug-related adverse reactions and trigger medical investigations. However, despite the recent advances in NLP, it is currently unknown if such models are robust in face of negation, which is pervasive across language varieties. In this paper we evaluate three state-of-the-art systems, showing their fragility against negation, and then we introduce two possible strategies to increase the robustness of these models: a pipeline approach, relying on a specific component for negation detection; an augmentation of an ADE extraction dataset to artificially create negated samples and further train the models. We show that both strategies bring significant increases in performance, lowering the number of spurious entities predicted by the models. Our dataset and code will be publicly released to encourage research on the topic.
SupCL-Seq: Supervised Contrastive Learning for Downstream Optimized Sequence Representations
Sep 15, 2021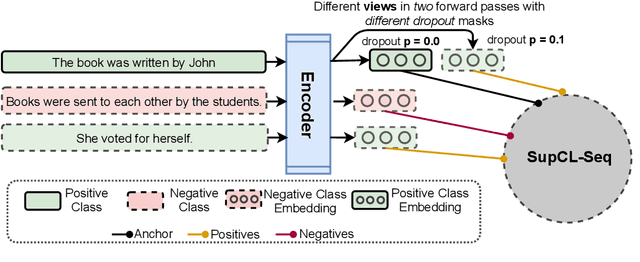
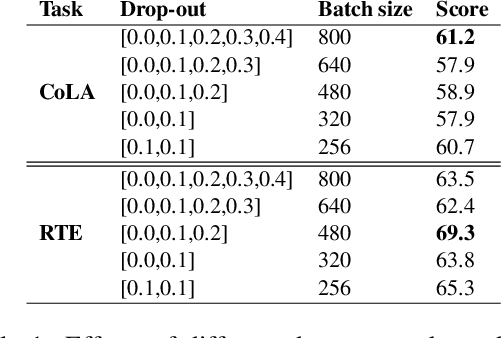


While contrastive learning is proven to be an effective training strategy in computer vision, Natural Language Processing (NLP) is only recently adopting it as a self-supervised alternative to Masked Language Modeling (MLM) for improving sequence representations. This paper introduces SupCL-Seq, which extends the supervised contrastive learning from computer vision to the optimization of sequence representations in NLP. By altering the dropout mask probability in standard Transformer architectures, for every representation (anchor), we generate augmented altered views. A supervised contrastive loss is then utilized to maximize the system's capability of pulling together similar samples (e.g., anchors and their altered views) and pushing apart the samples belonging to the other classes. Despite its simplicity, SupCLSeq leads to large gains in many sequence classification tasks on the GLUE benchmark compared to a standard BERTbase, including 6% absolute improvement on CoLA, 5.4% on MRPC, 4.7% on RTE and 2.6% on STSB. We also show consistent gains over self supervised contrastively learned representations, especially in non-semantic tasks. Finally we show that these gains are not solely due to augmentation, but rather to a downstream optimized sequence representation. Code: https://github.com/hooman650/SupCL-Seq
Exploring a Unified Sequence-To-Sequence Transformer for Medical Product Safety Monitoring in Social Media
Sep 13, 2021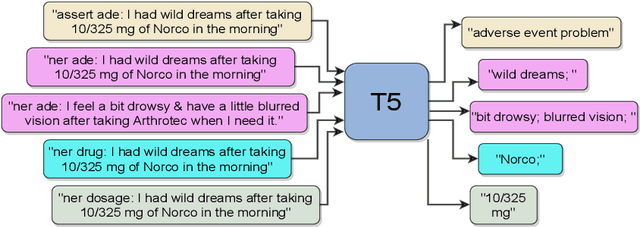

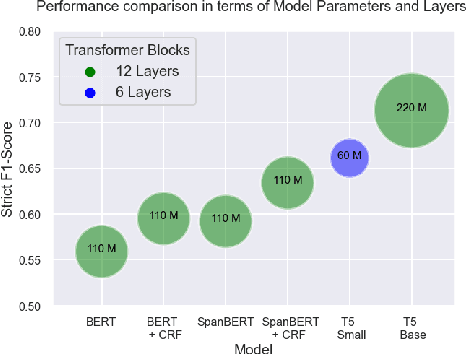
Adverse Events (AE) are harmful events resulting from the use of medical products. Although social media may be crucial for early AE detection, the sheer scale of this data makes it logistically intractable to analyze using human agents, with NLP representing the only low-cost and scalable alternative. In this paper, we frame AE Detection and Extraction as a sequence-to-sequence problem using the T5 model architecture and achieve strong performance improvements over competitive baselines on several English benchmarks (F1 = 0.71, 12.7% relative improvement for AE Detection; Strict F1 = 0.713, 12.4% relative improvement for AE Extraction). Motivated by the strong commonalities between AE-related tasks, the class imbalance in AE benchmarks and the linguistic and structural variety typical of social media posts, we propose a new strategy for multi-task training that accounts, at the same time, for task and dataset characteristics. Our multi-task approach increases model robustness, leading to further performance gains. Finally, our framework shows some language transfer capabilities, obtaining higher performance than Multilingual BERT in zero-shot learning on French data.
Did the Cat Drink the Coffee? Challenging Transformers with Generalized Event Knowledge
Jul 22, 2021
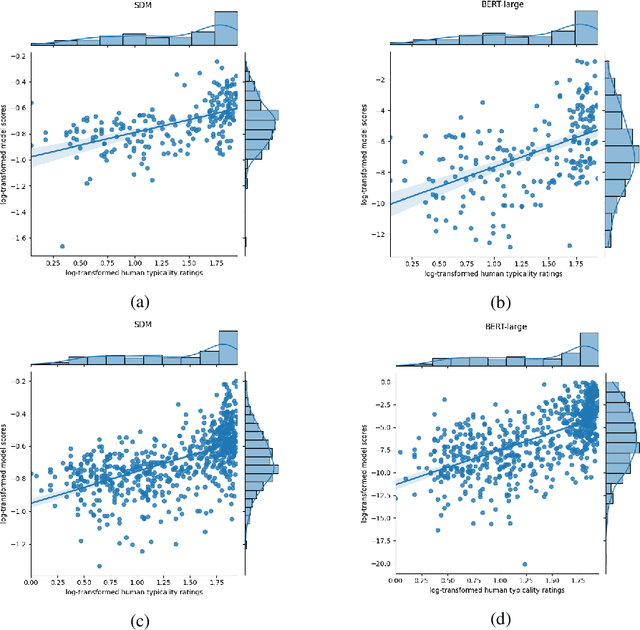

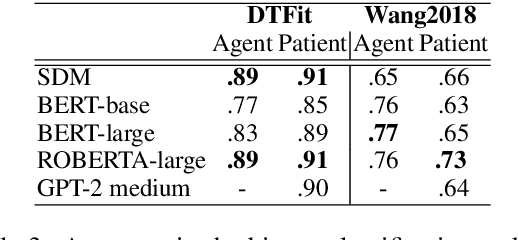
Prior research has explored the ability of computational models to predict a word semantic fit with a given predicate. While much work has been devoted to modeling the typicality relation between verbs and arguments in isolation, in this paper we take a broader perspective by assessing whether and to what extent computational approaches have access to the information about the typicality of entire events and situations described in language (Generalized Event Knowledge). Given the recent success of Transformers Language Models (TLMs), we decided to test them on a benchmark for the \textit{dynamic estimation of thematic fit}. The evaluation of these models was performed in comparison with SDM, a framework specifically designed to integrate events in sentence meaning representations, and we conducted a detailed error analysis to investigate which factors affect their behavior. Our results show that TLMs can reach performances that are comparable to those achieved by SDM. However, additional analysis consistently suggests that TLMs do not capture important aspects of event knowledge, and their predictions often depend on surface linguistic features, such as frequent words, collocations and syntactic patterns, thereby showing sub-optimal generalization abilities.
Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies
May 19, 2021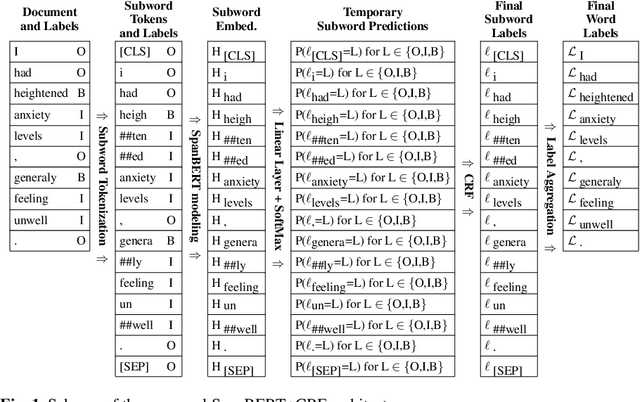
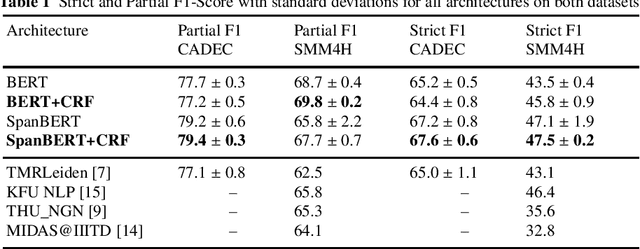
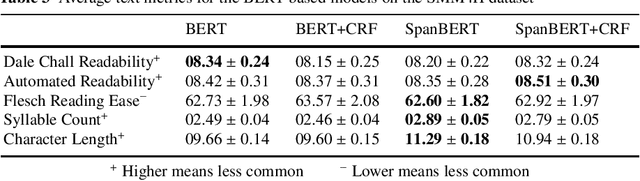
In recent years, Internet users are reporting Adverse Drug Events (ADE) on social media, blogs and health forums. Because of the large volume of reports, pharmacovigilance is seeking to resort to NLP to monitor these outlets. We propose for the first time the use of the SpanBERT architecture for the task of ADE extraction: this new version of the popular BERT transformer showed improved capabilities with multi-token text spans. We validate our hypothesis with experiments on two datasets (SMM4H and CADEC) with different text typologies (tweets and blog posts), finding that SpanBERT combined with a CRF outperforms all the competitors on both of them.