 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model-Aided Hierarchical Deep Reinforcement Learning for Blockage-Aware Link in RIS-Assisted Networks
Feb 09, 2026Reconfigurable intelligent surface (RIS) technology has the potential to significantly enhance the spectral efficiency (SE) of 6G wireless networks. However, practical deployment remains constrained by challenges in accurate channel estimation and control optimization under dynamic conditions. This paper presents a foundation model-aided hierarchical deep reinforcement learning (FM-HDRL) framework designed for joint beamforming and phase-shift optimization in RIS-assisted wireless networks. To implement this, we first fine-tune a pre-trained large wireless model (LWM) to translate raw channel data into low-dimensional, context-aware channel state information (CSI) embeddings. Next, these embeddings are combined with user location information and blockage status to select the optimal communication path. The resulting features are then fed into an HDRL model, assumed to be implemented at a centralized controller, which jointly optimizes the base station (BS) beamforming vectors and the RIS phase-shift configurations to maximize SE. Simulation results demonstrate that the proposed FM-HDRL framework consistently outperforms baseline methods in terms of convergence speed, spectral efficiency, and scalability. According to the simulation results, our proposed method improves 7.82% SE compared to the FM-aided deep reinforcement learning (FM-DRL) approach and a substantial enhancement of about 48.66% relative to the beam sweeping approach.
Multi-Modal Data-Enhanced Foundation Models for Prediction and Control in Wireless Networks: A Survey
Jan 06, 2026Foundation models (FMs) are recognized as a transformative breakthrough that has started to reshape the future of artificial intelligence (AI) across both academia and industry. The integration of FMs into wireless networks is expected to enable the development of general-purpose AI agents capable of handling diverse network management requests and highly complex wireless-related tasks involving multi-modal data. Inspired by these ideas, this work discusses the utilization of FMs, especially multi-modal FMs in wireless networks. We focus on two important types of tasks in wireless network management: prediction tasks and control tasks. In particular, we first discuss FMs-enabled multi-modal contextual information understanding in wireless networks. Then, we explain how FMs can be applied to prediction and control tasks, respectively. Following this, we introduce the development of wireless-specific FMs from two perspectives: available datasets for development and the methodologies used. Finally, we conclude with a discussion of the challenges and future directions for FM-enhanced wireless networks.
Foundation Model-Aided Hierarchical Control for Robust RIS-Assisted Near-Field Communications
Jan 06, 2026The deployment of extremely large aperture arrays (ELAAs) in sixth-generation (6G) networks could shift communication into the near-field communication (NFC) regime. In this regime, signals exhibit spherical wave propagation, unlike the planar waves in conventional far-field systems. Reconfigurable intelligent surfaces (RISs) can dynamically adjust phase shifts to support NFC beamfocusing, concentrating signal energy at specific spatial coordinates. However, effective RIS utilization depends on both rapid channel state information (CSI) estimation and proactive blockage mitigation, which occur on inherently different timescales. CSI varies at millisecond intervals due to small-scale fading, while blockage events evolve over seconds, posing challenges for conventional single-level control algorithms. To address this issue, we propose a dual-transformer (DT) hierarchical framework that integrates two specialized transformer models within a hierarchical deep reinforcement learning (HDRL) architecture, referred to as the DT-HDRL framework. A fast-timescale transformer processes ray-tracing data for rapid CSI estimation, while a vision transformer (ViT) analyzes visual data to predict impending blockages. In HDRL, the high-level controller selects line-of-sight (LoS) or RIS-assisted non-line-of-sight (NLoS) transmission paths and sets goals, while the low-level controller optimizes base station (BS) beamfocusing and RIS phase shifts using instantaneous CSI. This dual-timescale coordination maximizes spectral efficiency (SE) while ensuring robust performance under dynamic conditions. Simulation results demonstrate that our approach improves SE by approximately 18% compared to single-timescale baselines, while the proposed blockage predictor achieves an F1-score of 0.92, providing a 769 ms advance warning window in dynamic scenarios.
Automated stereotactic radiosurgery planning using a human-in-the-loop reasoning large language model agent
Dec 23, 2025


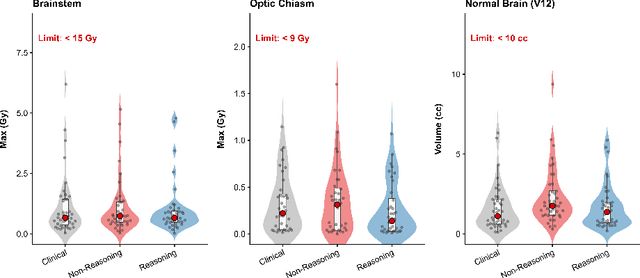
Stereotactic radiosurgery (SRS) demands precise dose shaping around critical structures, yet black-box AI systems have limited clinical adoption due to opacity concerns. We tested whether chain-of-thought reasoning improves agentic planning in a retrospective cohort of 41 patients with brain metastases treated with 18 Gy single-fraction SRS. We developed SAGE (Secure Agent for Generative Dose Expertise), an LLM-based planning agent for automated SRS treatment planning. Two variants generated plans for each case: one using a non-reasoning model, one using a reasoning model. The reasoning variant showed comparable plan dosimetry relative to human planners on primary endpoints (PTV coverage, maximum dose, conformity index, gradient index; all p > 0.21) while reducing cochlear dose below human baselines (p = 0.022). When prompted to improve conformity, the reasoning model demonstrated systematic planning behaviors including prospective constraint verification (457 instances) and trade-off deliberation (609 instances), while the standard model exhibited none of these deliberative processes (0 and 7 instances, respectively). Content analysis revealed that constraint verification and causal explanation concentrated in the reasoning agent. The optimization traces serve as auditable logs, offering a path toward transparent automated planning.
Foundation Model-Aided Deep Reinforcement Learning for RIS-Assisted Wireless Communication
Jun 11, 2025Reconfigurable intelligent surfaces (RIS) have emerged as a promising technology for enhancing wireless communication by dynamically controlling signal propagation in the environment. However, their efficient deployment relies on accurate channel state information (CSI), which leads to high channel estimation overhead due to their passive nature and the large number of reflective elements. In this work, we solve this challenge by proposing a novel framework that leverages a pre-trained open-source foundation model (FM) named large wireless model (LWM) to process wireless channels and generate versatile and contextualized channel embeddings. These embeddings are then used for the joint optimization of the BS beamforming and RIS configurations. To be more specific, for joint optimization, we design a deep reinforcement learning (DRL) model to automatically select the BS beamforming vector and RIS phase-shift matrix, aiming to maximize the spectral efficiency (SE). This work shows that a pre-trained FM for radio signal understanding can be fine-tuned and integrated with DRL for effective decision-making in wireless networks. It highlights the potential of modality-specific FMs in real-world network optimization. According to the simulation results, the proposed method outperforms the DRL-based approach and beam sweeping-based approach, achieving 9.89% and 43.66% higher SE, respectively.
Generative AI-enabled Blockage Prediction for Robust Dual-Band mmWave Communication
Jan 20, 2025



In mmWave wireless networks, signal blockages present a significant challenge due to the susceptibility to environmental moving obstructions. Recently, the availability of visual data has been leveraged to enhance blockage prediction accuracy in mmWave networks. In this work, we propose a Vision Transformer (ViT)-based approach for visual-aided blockage prediction that intelligently switches between mmWave and Sub-6 GHz frequencies to maximize network throughput and maintain reliable connectivity. Given the computational demands of processing visual data, we implement our solution within a hierarchical fog-cloud computing architecture, where fog nodes collaborate with cloud servers to efficiently manage computational tasks. This structure incorporates a generative AI-based compression technique that significantly reduces the volume of visual data transmitted between fog nodes and cloud centers. Our proposed method is tested with the real-world DeepSense 6G dataset, and according to the simulation results, it achieves a blockage prediction accuracy of 92.78% while reducing bandwidth usage by 70.31%.
Bridging the Gap: Enhancing LLM Performance for Low-Resource African Languages with New Benchmarks, Fine-Tuning, and Cultural Adjustments
Dec 16, 2024Large Language Models (LLMs) have shown remarkable performance across various tasks, yet significant disparities remain for non-English languages, and especially native African languages. This paper addresses these disparities by creating approximately 1 million human-translated words of new benchmark data in 8 low-resource African languages, covering a population of over 160 million speakers of: Amharic, Bambara, Igbo, Sepedi (Northern Sotho), Shona, Sesotho (Southern Sotho), Setswana, and Tsonga. Our benchmarks are translations of Winogrande and three sections of MMLU: college medicine, clinical knowledge, and virology. Using the translated benchmarks, we report previously unknown performance gaps between state-of-the-art (SOTA) LLMs in English and African languages. Finally, using results from over 400 fine-tuned models, we explore several methods to reduce the LLM performance gap, including high-quality dataset fine-tuning (using an LLM-as-an-Annotator), cross-lingual transfer, and cultural appropriateness adjustments. Key findings include average mono-lingual improvements of 5.6% with fine-tuning (with 5.4% average mono-lingual improvements when using high-quality data over low-quality data), 2.9% average gains from cross-lingual transfer, and a 3.0% out-of-the-box performance boost on culturally appropriate questions. The publicly available benchmarks, translations, and code from this study support further research and development aimed at creating more inclusive and effective language technologies.
Multi-Modal Transformer and Reinforcement Learning-based Beam Management
Oct 22, 2024


Beam management is an important technique to improve signal strength and reduce interference in wireless communication systems. Recently, there has been increasing interest in using diverse sensing modalities for beam management. However, it remains a big challenge to process multi-modal data efficiently and extract useful information. On the other hand, the recently emerging multi-modal transformer (MMT) is a promising technique that can process multi-modal data by capturing long-range dependencies. While MMT is highly effective in handling multi-modal data and providing robust beam management, integrating reinforcement learning (RL) further enhances their adaptability in dynamic environments. In this work, we propose a two-step beam management method by combining MMT with RL for dynamic beam index prediction. In the first step, we divide available beam indices into several groups and leverage MMT to process diverse data modalities to predict the optimal beam group. In the second step, we employ RL for fast beam decision-making within each group, which in return maximizes throughput. Our proposed framework is tested on a 6G dataset. In this testing scenario, it achieves higher beam prediction accuracy and system throughput compared to both the MMT-only based method and the RL-only based method.
Temporal Link Prediction Using Graph Embedding Dynamics
Jan 15, 2024



Graphs are a powerful representation tool in machine learning applications, with link prediction being a key task in graph learning. Temporal link prediction in dynamic networks is of particular interest due to its potential for solving complex scientific and real-world problems. Traditional approaches to temporal link prediction have focused on finding the aggregation of dynamics of the network as a unified output. In this study, we propose a novel perspective on temporal link prediction by defining nodes as Newtonian objects and incorporating the concept of velocity to predict network dynamics. By computing more specific dynamics of each node, rather than overall dynamics, we improve both accuracy and explainability in predicting future connections. We demonstrate the effectiveness of our approach using two datasets, including 17 years of co-authorship data from PubMed. Experimental results show that our temporal graph embedding dynamics approach improves downstream classification models' ability to predict future collaboration efficacy in co-authorship networks by 17.34% (AUROC improvement relative to the baseline model). Furthermore, our approach offers an interpretable layer over traditional approaches to address the temporal link prediction problem.
Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach
May 10, 2022
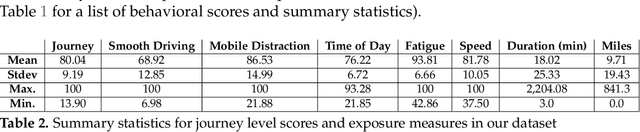
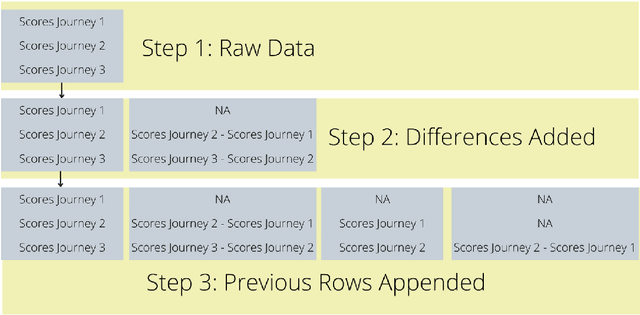
In recent years it has become possible to collect GPS data from drivers and to incorporate this data into automobile insurance pricing for the driver. This data is continuously collected and processed nightly into metadata consisting of mileage and time summaries of each discrete trip taken, and a set of behavioral scores describing attributes of the trip (e.g, driver fatigue or driver distraction) so we examine whether it can be used to identify periods of increased risk by successfully classifying trips that occur immediately before a trip in which there was an incident leading to a claim for that driver. Identification of periods of increased risk for a driver is valuable because it creates an opportunity for intervention and, potentially, avoidance of a claim. We examine metadata for each trip a driver takes and train a classifier to predict whether \textit{the following trip} is one in which a claim occurs for that driver. By achieving a area under the receiver-operator characteristic above 0.6, we show that it is possible to predict claims in advance. Additionally, we compare the predictive power, as measured by the area under the receiver-operator characteristic of XGBoost classifiers trained to predict whether a driver will have a claim using exposure features such as driven miles, and those trained using behavioral features such as a computed speed score.