 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupCL-Seq: Supervised Contrastive Learning for Downstream Optimized Sequence Representations
Sep 15, 2021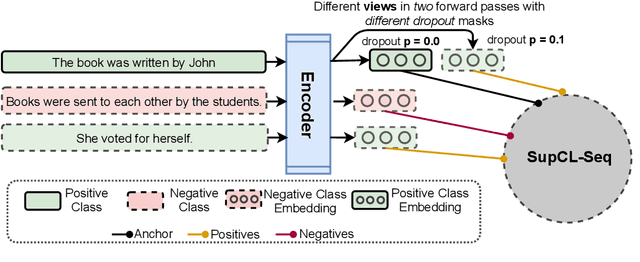
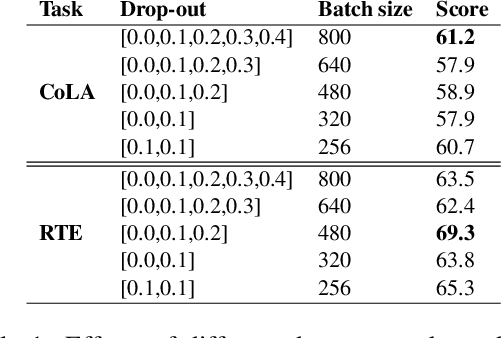


While contrastive learning is proven to be an effective training strategy in computer vision, Natural Language Processing (NLP) is only recently adopting it as a self-supervised alternative to Masked Language Modeling (MLM) for improving sequence representations. This paper introduces SupCL-Seq, which extends the supervised contrastive learning from computer vision to the optimization of sequence representations in NLP. By altering the dropout mask probability in standard Transformer architectures, for every representation (anchor), we generate augmented altered views. A supervised contrastive loss is then utilized to maximize the system's capability of pulling together similar samples (e.g., anchors and their altered views) and pushing apart the samples belonging to the other classes. Despite its simplicity, SupCLSeq leads to large gains in many sequence classification tasks on the GLUE benchmark compared to a standard BERTbase, including 6% absolute improvement on CoLA, 5.4% on MRPC, 4.7% on RTE and 2.6% on STSB. We also show consistent gains over self supervised contrastively learned representations, especially in non-semantic tasks. Finally we show that these gains are not solely due to augmentation, but rather to a downstream optimized sequence representation. Code: https://github.com/hooman650/SupCL-Seq
Exploring a Unified Sequence-To-Sequence Transformer for Medical Product Safety Monitoring in Social Media
Sep 13, 2021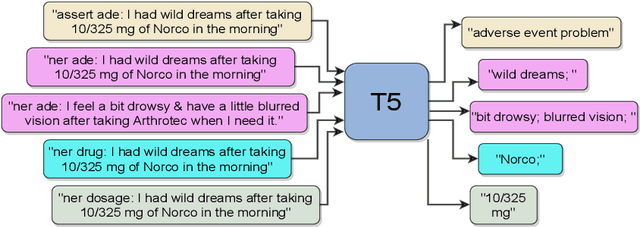

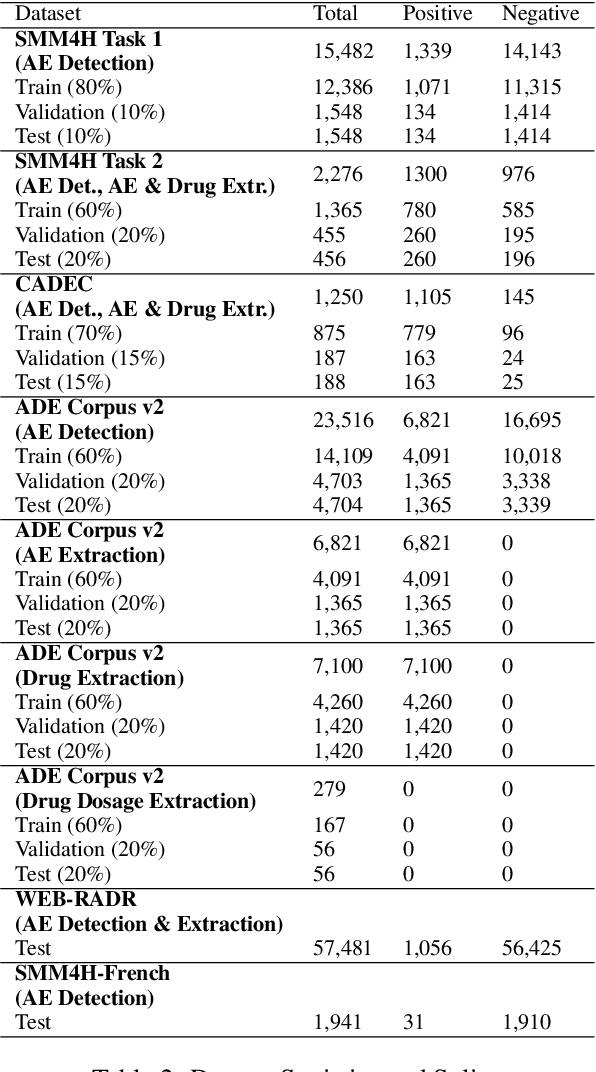
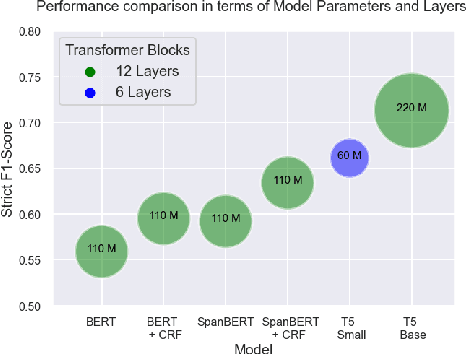
Adverse Events (AE) are harmful events resulting from the use of medical products. Although social media may be crucial for early AE detection, the sheer scale of this data makes it logistically intractable to analyze using human agents, with NLP representing the only low-cost and scalable alternative. In this paper, we frame AE Detection and Extraction as a sequence-to-sequence problem using the T5 model architecture and achieve strong performance improvements over competitive baselines on several English benchmarks (F1 = 0.71, 12.7% relative improvement for AE Detection; Strict F1 = 0.713, 12.4% relative improvement for AE Extraction). Motivated by the strong commonalities between AE-related tasks, the class imbalance in AE benchmarks and the linguistic and structural variety typical of social media posts, we propose a new strategy for multi-task training that accounts, at the same time, for task and dataset characteristics. Our multi-task approach increases model robustness, leading to further performance gains. Finally, our framework shows some language transfer capabilities, obtaining higher performance than Multilingual BERT in zero-shot learning on French data.