 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoENAS: Mixture-of-Expert based Neural Architecture Search for jointly Accurate, Fair, and Robust Edge Deep Neural Networks
Feb 11, 2025There has been a surge in optimizing edge Deep Neural Networks (DNNs) for accuracy and efficiency using traditional optimization techniques such as pruning, and more recently, employing automatic design methodologies. However, the focus of these design techniques has often overlooked critical metrics such as fairness, robustness, and generalization. As a result, when evaluating SOTA edge DNNs' performance in image classification using the FACET dataset, we found that they exhibit significant accuracy disparities (14.09%) across 10 different skin tones, alongside issues of non-robustness and poor generalizability. In response to these observations, we introduce Mixture-of-Experts-based Neural Architecture Search (MoENAS), an automatic design technique that navigates through a space of mixture of experts to discover accurate, fair, robust, and general edge DNNs. MoENAS improves the accuracy by 4.02% compared to SOTA edge DNNs and reduces the skin tone accuracy disparities from 14.09% to 5.60%, while enhancing robustness by 3.80% and minimizing overfitting to 0.21%, all while keeping model size close to state-of-the-art models average size (+0.4M). With these improvements, MoENAS establishes a new benchmark for edge DNN design, paving the way for the development of more inclusive and robust edge DNNs.
GLoG-CSUnet: Enhancing Vision Transformers with Adaptable Radiomic Features for Medical Image Segmentation
Jan 08, 2025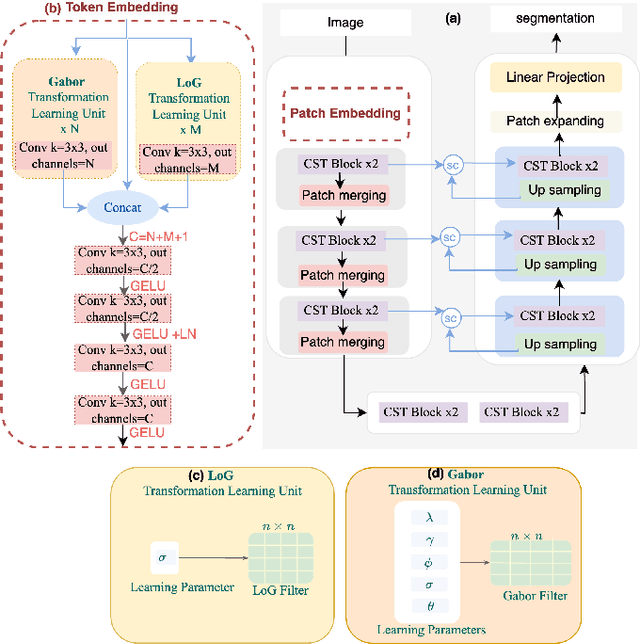
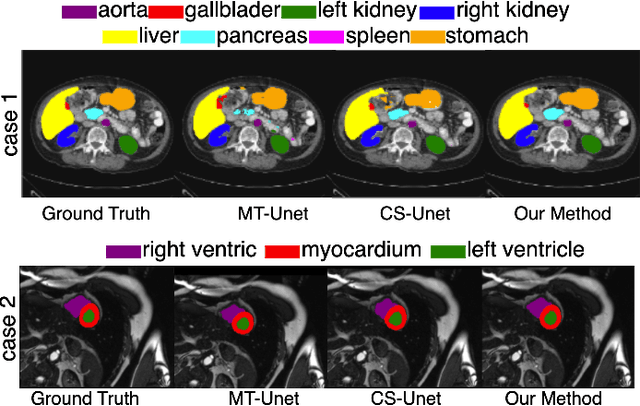
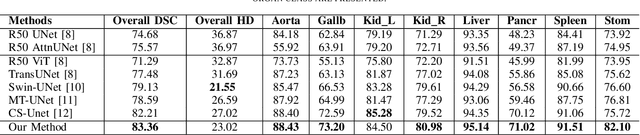
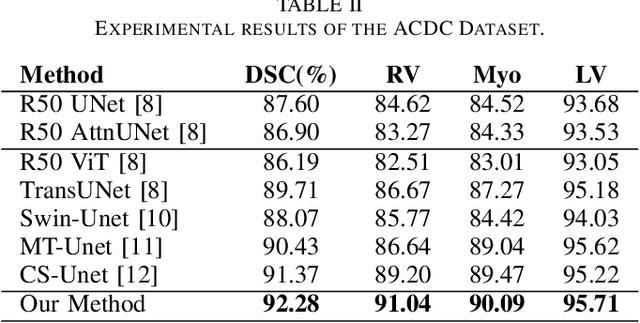
Vision Transformers (ViTs) have shown promise in medical image semantic segmentation (MISS) by capturing long-range correlations. However, ViTs often struggle to model local spatial information effectively, which is essential for accurately segmenting fine anatomical details, particularly when applied to small datasets without extensive pre-training. We introduce Gabor and Laplacian of Gaussian Convolutional Swin Network (GLoG-CSUnet), a novel architecture enhancing Transformer-based models by incorporating learnable radiomic features. This approach integrates dynamically adaptive Gabor and Laplacian of Gaussian (LoG) filters to capture texture, edge, and boundary information, enhancing the feature representation processed by the Transformer model. Our method uniquely combines the long-range dependency modeling of Transformers with the texture analysis capabilities of Gabor and LoG features. Evaluated on the Synapse multi-organ and ACDC cardiac segmentation datasets, GLoG-CSUnet demonstrates significant improvements over state-of-the-art models, achieving a 1.14% increase in Dice score for Synapse and 0.99% for ACDC, with minimal computational overhead (only 15 and 30 additional parameters, respectively). GLoG-CSUnet's flexible design allows integration with various base models, offering a promising approach for incorporating radiomics-inspired feature extraction in Transformer architectures for medical image analysis. The code implementation is available on GitHub at: https://github.com/HAAIL/GLoG-CSUnet.
Bridging the Gap: Enhancing LLM Performance for Low-Resource African Languages with New Benchmarks, Fine-Tuning, and Cultural Adjustments
Dec 16, 2024Large Language Models (LLMs) have shown remarkable performance across various tasks, yet significant disparities remain for non-English languages, and especially native African languages. This paper addresses these disparities by creating approximately 1 million human-translated words of new benchmark data in 8 low-resource African languages, covering a population of over 160 million speakers of: Amharic, Bambara, Igbo, Sepedi (Northern Sotho), Shona, Sesotho (Southern Sotho), Setswana, and Tsonga. Our benchmarks are translations of Winogrande and three sections of MMLU: college medicine, clinical knowledge, and virology. Using the translated benchmarks, we report previously unknown performance gaps between state-of-the-art (SOTA) LLMs in English and African languages. Finally, using results from over 400 fine-tuned models, we explore several methods to reduce the LLM performance gap, including high-quality dataset fine-tuning (using an LLM-as-an-Annotator), cross-lingual transfer, and cultural appropriateness adjustments. Key findings include average mono-lingual improvements of 5.6% with fine-tuning (with 5.4% average mono-lingual improvements when using high-quality data over low-quality data), 2.9% average gains from cross-lingual transfer, and a 3.0% out-of-the-box performance boost on culturally appropriate questions. The publicly available benchmarks, translations, and code from this study support further research and development aimed at creating more inclusive and effective language technologies.
Hybrid Student-Teacher Large Language Model Refinement for Cancer Toxicity Symptom Extraction
Aug 08, 2024


Large Language Models (LLMs) offer significant potential for clinical symptom extraction, but their deployment in healthcare settings is constrained by privacy concerns, computational limitations, and operational costs. This study investigates the optimization of compact LLMs for cancer toxicity symptom extraction using a novel iterative refinement approach. We employ a student-teacher architecture, utilizing Zephyr-7b-beta and Phi3-mini-128 as student models and GPT-4o as the teacher, to dynamically select between prompt refinement, Retrieval-Augmented Generation (RAG), and fine-tuning strategies. Our experiments on 294 clinical notes covering 12 post-radiotherapy toxicity symptoms demonstrate the effectiveness of this approach. The RAG method proved most efficient, improving average accuracy scores from 0.32 to 0.73 for Zephyr-7b-beta and from 0.40 to 0.87 for Phi3-mini-128 during refinement. In the test set, both models showed an approximate 0.20 increase in accuracy across symptoms. Notably, this improvement was achieved at a cost 45 times lower than GPT-4o for Zephyr and 79 times lower for Phi-3. These results highlight the potential of iterative refinement techniques in enhancing the capabilities of compact LLMs for clinical applications, offering a balance between performance, cost-effectiveness, and privacy preservation in healthcare settings.
The Role of Functional Muscle Networks in Improving Hand Gesture Perception for Human-Machine Interfaces
Aug 05, 2024Developing accurate hand gesture perception models is critical for various robotic applications, enabling effective communication between humans and machines and directly impacting neurorobotics and interactive robots. Recently, surface electromyography (sEMG) has been explored for its rich informational context and accessibility when combined with advanced machine learning approaches and wearable systems. The literature presents numerous approaches to boost performance while ensuring robustness for neurorobots using sEMG, often resulting in models requiring high processing power, large datasets, and less scalable solutions. This paper addresses this challenge by proposing the decoding of muscle synchronization rather than individual muscle activation. We study coherence-based functional muscle networks as the core of our perception model, proposing that functional synchronization between muscles and the graph-based network of muscle connectivity encode contextual information about intended hand gestures. This can be decoded using shallow machine learning approaches without the need for deep temporal networks. Our technique could impact myoelectric control of neurorobots by reducing computational burdens and enhancing efficiency. The approach is benchmarked on the Ninapro database, which contains 12 EMG signals from 40 subjects performing 17 hand gestures. It achieves an accuracy of 85.1%, demonstrating improved performance compared to existing methods while requiring much less computational power. The results support the hypothesis that a coherence-based functional muscle network encodes critical information related to gesture execution, significantly enhancing hand gesture perception with potential applications for neurorobotic systems and interactive machines.
An LSTM Feature Imitation Network for Hand Movement Recognition from sEMG Signals
May 23, 2024
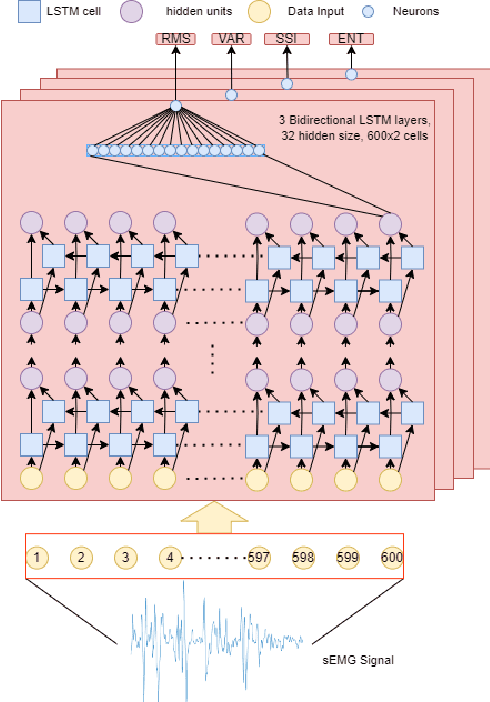
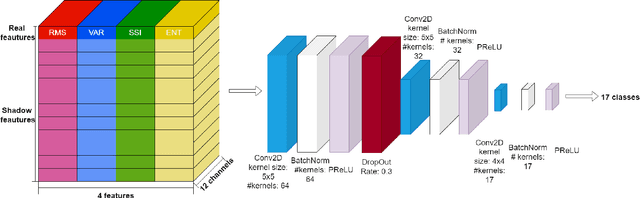
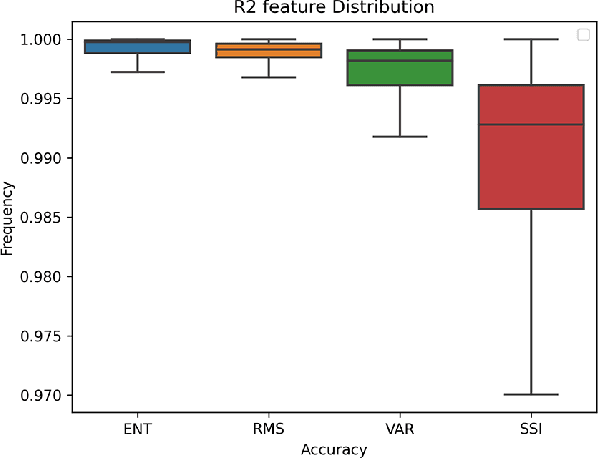
Surface Electromyography (sEMG) is a non-invasive signal that is used in the recognition of hand movement patterns, the diagnosis of diseases, and the robust control of prostheses. Despite the remarkable success of recent end-to-end Deep Learning approaches, they are still limited by the need for large amounts of labeled data. To alleviate the requirement for big data, researchers utilize Feature Engineering, which involves decomposing the sEMG signal into several spatial, temporal, and frequency features. In this paper, we propose utilizing a feature-imitating network (FIN) for closed-form temporal feature learning over a 300ms signal window on Ninapro DB2, and applying it to the task of 17 hand movement recognition. We implement a lightweight LSTM-FIN network to imitate four standard temporal features (entropy, root mean square, variance, simple square integral). We then explore transfer learning capabilities by applying the pre-trained LSTM-FIN for tuning to a downstream hand movement recognition task. We observed that the LSTM network can achieve up to 99\% R2 accuracy in feature reconstruction and 80\% accuracy in hand movement recognition. Our results also showed that the model can be robustly applied for both within- and cross-subject movement recognition, as well as simulated low-latency environments. Overall, our work demonstrates the potential of the FIN modeling paradigm in data-scarce scenarios for sEMG signal processing.
The Broad Impact of Feature Imitation: Neural Enhancements Across Financial, Speech, and Physiological Domains
Sep 21, 2023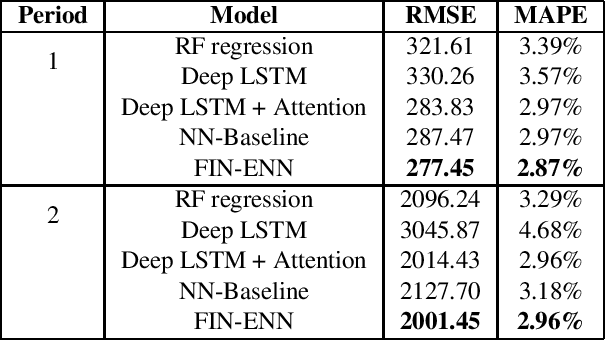

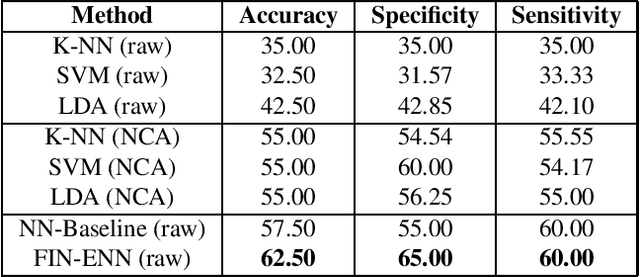
Initialization of neural network weights plays a pivotal role in determining their performance. Feature Imitating Networks (FINs) offer a novel strategy by initializing weights to approximate specific closed-form statistical features, setting a promising foundation for deep learning architectures. While the applicability of FINs has been chiefly tested in biomedical domains, this study extends its exploration into other time series datasets. Three different experiments are conducted in this study to test the applicability of imitating Tsallis entropy for performance enhancement: Bitcoin price prediction, speech emotion recognition, and chronic neck pain detection. For the Bitcoin price prediction, models embedded with FINs reduced the root mean square error by around 1000 compared to the baseline. In the speech emotion recognition task, the FIN-augmented model increased classification accuracy by over 3 percent. Lastly, in the CNP detection experiment, an improvement of about 7 percent was observed compared to established classifiers. These findings validate the broad utility and potency of FINs in diverse applications.
Feature Imitating Networks Enhance The Performance, Reliability And Speed Of Deep Learning On Biomedical Image Processing Tasks
Jun 26, 2023Feature-Imitating-Networks (FINs) are neural networks with weights that are initialized to approximate closed-form statistical features. In this work, we perform the first-ever evaluation of FINs for biomedical image processing tasks. We begin by training a set of FINs to imitate six common radiomics features, and then compare the performance of networks with and without the FINs for three experimental tasks: COVID-19 detection from CT scans, brain tumor classification from MRI scans, and brain-tumor segmentation from MRI scans; we find that FINs provide best-in-class performance for all three tasks, while converging faster and more consistently when compared to networks with similar or greater representational power. The results of our experiments provide evidence that FINs may provide state-of-the-art performance for a variety of other biomedical image processing tasks.
MambaNet: A Hybrid Neural Network for Predicting the NBA Playoffs
Oct 31, 2022



In this paper, we present Mambanet: a hybrid neural network for predicting the outcomes of Basketball games. Contrary to other studies, which focus primarily on season games, this study investigates playoff games. MambaNet is a hybrid neural network architecture that processes a time series of teams' and players' game statistics and generates the probability of a team winning or losing an NBA playoff match. In our approach, we utilize Feature Imitating Networks to provide latent signal-processing feature representations of game statistics to further process with convolutional, recurrent, and dense neural layers. Three experiments using six different datasets are conducted to evaluate the performance and generalizability of our architecture against a wide range of previous studies. Our final method successfully predicted the AUC from 0.72 to 0.82, beating the best-performing baseline models by a considerable margin.
Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach
May 10, 2022
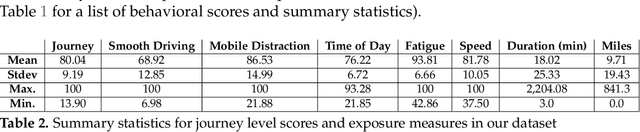
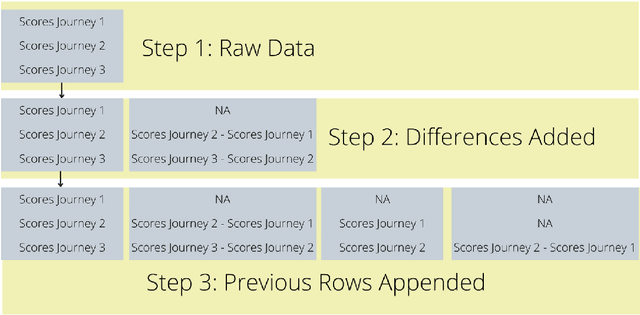
In recent years it has become possible to collect GPS data from drivers and to incorporate this data into automobile insurance pricing for the driver. This data is continuously collected and processed nightly into metadata consisting of mileage and time summaries of each discrete trip taken, and a set of behavioral scores describing attributes of the trip (e.g, driver fatigue or driver distraction) so we examine whether it can be used to identify periods of increased risk by successfully classifying trips that occur immediately before a trip in which there was an incident leading to a claim for that driver. Identification of periods of increased risk for a driver is valuable because it creates an opportunity for intervention and, potentially, avoidance of a claim. We examine metadata for each trip a driver takes and train a classifier to predict whether \textit{the following trip} is one in which a claim occurs for that driver. By achieving a area under the receiver-operator characteristic above 0.6, we show that it is possible to predict claims in advance. Additionally, we compare the predictive power, as measured by the area under the receiver-operator characteristic of XGBoost classifiers trained to predict whether a driver will have a claim using exposure features such as driven miles, and those trained using behavioral features such as a computed speed score.