 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-Based Test-Harness for LLM Evaluation
Aug 28, 2025We present a first known prototype of a dynamic, systematic benchmark of medical guidelines for 400+ questions, with 3.3+ trillion possible combinations, covering 100\% of guideline relationships. We transformed the WHO IMCI handbook into a directed graph with 200+ nodes (conditions, symptoms, treatments, follow-ups, severities) and 300+ edges, then used graph traversal to generate questions that incorporated age-specific scenarios and contextual distractors to ensure clinical relevance. Our graph-based approach enables systematic evaluation across clinical tasks (45-67\% accuracy), and we find models excel at symptom recognition but struggle with triaging severity, treatment protocols and follow-up care, demonstrating how customized benchmarks can identify specific capability gaps that general-domain evaluations miss. Beyond evaluation, this dynamic MCQA methodology enhances LLM post-training (supervised finetuning, GRPO, DPO), where correct answers provide high-reward samples without expensive human annotation. The graph-based approach successfully addresses the coverage limitations of manually curated benchmarks. This methodology is a step toward scalable, contamination-resistant solution for creating comprehensive benchmarks that can be dynamically generated, including when the guidelines are updated. Code and datasets are available at https://github.com/jessicalundin/graph_testing_harness
Bridging the Gap: Enhancing LLM Performance for Low-Resource African Languages with New Benchmarks, Fine-Tuning, and Cultural Adjustments
Dec 16, 2024Large Language Models (LLMs) have shown remarkable performance across various tasks, yet significant disparities remain for non-English languages, and especially native African languages. This paper addresses these disparities by creating approximately 1 million human-translated words of new benchmark data in 8 low-resource African languages, covering a population of over 160 million speakers of: Amharic, Bambara, Igbo, Sepedi (Northern Sotho), Shona, Sesotho (Southern Sotho), Setswana, and Tsonga. Our benchmarks are translations of Winogrande and three sections of MMLU: college medicine, clinical knowledge, and virology. Using the translated benchmarks, we report previously unknown performance gaps between state-of-the-art (SOTA) LLMs in English and African languages. Finally, using results from over 400 fine-tuned models, we explore several methods to reduce the LLM performance gap, including high-quality dataset fine-tuning (using an LLM-as-an-Annotator), cross-lingual transfer, and cultural appropriateness adjustments. Key findings include average mono-lingual improvements of 5.6% with fine-tuning (with 5.4% average mono-lingual improvements when using high-quality data over low-quality data), 2.9% average gains from cross-lingual transfer, and a 3.0% out-of-the-box performance boost on culturally appropriate questions. The publicly available benchmarks, translations, and code from this study support further research and development aimed at creating more inclusive and effective language technologies.
Multi-Pair Text Style Transfer on Unbalanced Data
Jun 20, 2021


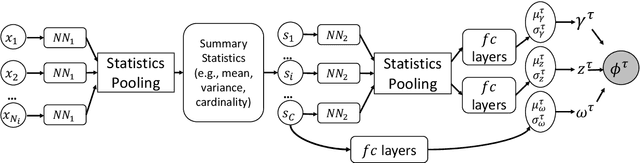
Text-style transfer aims to convert text given in one domain into another by paraphrasing the sentence or substituting the keywords without altering the content. By necessity, state-of-the-art methods have evolved to accommodate nonparallel training data, as it is frequently the case there are multiple data sources of unequal size, with a mixture of labeled and unlabeled sentences. Moreover, the inherent style defined within each source might be distinct. A generic bidirectional (e.g., formal $\Leftrightarrow$ informal) style transfer regardless of different groups may not generalize well to different applications. In this work, we developed a task adaptive meta-learning framework that can simultaneously perform a multi-pair text-style transfer using a single model. The proposed method can adaptively balance the difference of meta-knowledge across multiple tasks. Results show that our method leads to better quantitative performance as well as coherent style variations. Common challenges of unbalanced data and mismatched domains are handled well by this method.
ePillID Dataset: A Low-Shot Fine-Grained Benchmark for Pill Identification
May 28, 2020



Identifying prescription medications is a frequent task for patients and medical professionals; however, this is an error-prone task as many pills have similar appearances (e.g. white round pills), which increases the risk of medication errors. In this paper, we introduce ePillID, the largest public benchmark on pill image recognition, composed of 13k images representing 8184 appearance classes (two sides for 4092 pill types). For most of the appearance classes, there exists only one reference image, making it a challenging low-shot recognition setting. We present our experimental setup and evaluation results of various baseline models on the benchmark. The best baseline using a multi-head metric-learning approach with bilinear features performed remarkably well; however, our error analysis suggests that they still fail to distinguish particularly confusing classes. The code and data are available at \url{https://github.com/usuyama/ePillID-benchmark}.