 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Priors for Uncertainty-Aware Deterioration Risk Prediction with Multimodal Data
Mar 09, 2026Safe predictions are a crucial requirement for integrating predictive models into clinical decision support systems. One approach for ensuring trustworthiness is to enable models' ability to express their uncertainty about individual predictions. However, current machine learning models frequently lack reliable uncertainty estimation, hindering real-world deployment. This is further observed in multimodal settings, where the goal is to enable effective information fusion. In this work, we propose $\texttt{MedCertAIn}$, a predictive uncertainty framework that leverages multimodal clinical data for in-hospital risk prediction to improve model performance and reliability. We design data-driven priors over neural network parameters using a hybrid strategy that considers cross-modal similarity in self-supervised latent representations and modality-specific data corruptions. We train and evaluate the models with such priors using clinical time-series and chest X-ray images from the publicly-available datasets MIMIC-IV and MIMIC-CXR. Our results show that $\texttt{MedCertAIn}$ significantly improves predictive performance and uncertainty quantification compared to state-of-the-art deterministic baselines and alternative Bayesian methods. These findings highlight the promise of data-driven priors in advancing robust, uncertainty-aware AI tools for high-stakes clinical applications.
An Empirical Analysis of Calibration and Selective Prediction in Multimodal Clinical Condition Classification
Mar 03, 2026As artificial intelligence systems move toward clinical deployment, ensuring reliable prediction behavior is fundamental for safety-critical decision-making tasks. One proposed safeguard is selective prediction, where models can defer uncertain predictions to human experts for review. In this work, we empirically evaluate the reliability of uncertainty-based selective prediction in multilabel clinical condition classification using multimodal ICU data. Across a range of state-of-the-art unimodal and multimodal models, we find that selective prediction can substantially degrade performance despite strong standard evaluation metrics. This failure is driven by severe class-dependent miscalibration, whereby models assign high uncertainty to correct predictions and low uncertainty to incorrect ones, particularly for underrepresented clinical conditions. Our results show that commonly used aggregate metrics can obscure these effects, limiting their ability to assess selective prediction behavior in this setting. Taken together, our findings characterize a task-specific failure mode of selective prediction in multimodal clinical condition classification and highlight the need for calibration-aware evaluation to provide strong guarantees of safety and robustness in clinical AI.
MedErrBench: A Fine-Grained Multilingual Benchmark for Medical Error Detection and Correction with Clinical Expert Annotations
Feb 05, 2026Inaccuracies in existing or generated clinical text may lead to serious adverse consequences, especially if it is a misdiagnosis or incorrect treatment suggestion. With Large Language Models (LLMs) increasingly being used across diverse healthcare applications, comprehensive evaluation through dedicated benchmarks is crucial. However, such datasets remain scarce, especially across diverse languages and contexts. In this paper, we introduce MedErrBench, the first multilingual benchmark for error detection, localization, and correction, developed under the guidance of experienced clinicians. Based on an expanded taxonomy of ten common error types, MedErrBench covers English, Arabic and Chinese, with natural clinical cases annotated and reviewed by domain experts. We assessed the performance of a range of general-purpose, language-specific, and medical-domain language models across all three tasks. Our results reveal notable performance gaps, particularly in non-English settings, highlighting the need for clinically grounded, language-aware systems. By making MedErrBench and our evaluation protocols publicly-available, we aim to advance multilingual clinical NLP to promote safer and more equitable AI-based healthcare globally. The dataset is available in the supplementary material. An anonymized version of the dataset is available at: https://github.com/congboma/MedErrBench.
Cross-Lingual Empirical Evaluation of Large Language Models for Arabic Medical Tasks
Feb 05, 2026In recent years, Large Language Models (LLMs) have become widely used in medical applications, such as clinical decision support, medical education, and medical question answering. Yet, these models are often English-centric, limiting their robustness and reliability for linguistically diverse communities. Recent work has highlighted discrepancies in performance in low-resource languages for various medical tasks, but the underlying causes remain poorly understood. In this study, we conduct a cross-lingual empirical analysis of LLM performance on Arabic and English medical question and answering. Our findings reveal a persistent language-driven performance gap that intensifies with increasing task complexity. Tokenization analysis exposes structural fragmentation in Arabic medical text, while reliability analysis suggests that model-reported confidence and explanations exhibit limited correlation with correctness. Together, these findings underscore the need for language-aware design and evaluation strategies in LLMs for medical tasks.
MedAraBench: Large-Scale Arabic Medical Question Answering Dataset and Benchmark
Feb 02, 2026Arabic remains one of the most underrepresented languages in natural language processing research, particularly in medical applications, due to the limited availability of open-source data and benchmarks. The lack of resources hinders efforts to evaluate and advance the multilingual capabilities of Large Language Models (LLMs). In this paper, we introduce MedAraBench, a large-scale dataset consisting of Arabic multiple-choice question-answer pairs across various medical specialties. We constructed the dataset by manually digitizing a large repository of academic materials created by medical professionals in the Arabic-speaking region. We then conducted extensive preprocessing and split the dataset into training and test sets to support future research efforts in the area. To assess the quality of the data, we adopted two frameworks, namely expert human evaluation and LLM-as-a-judge. Our dataset is diverse and of high quality, spanning 19 specialties and five difficulty levels. For benchmarking purposes, we assessed the performance of eight state-of-the-art open-source and proprietary models, such as GPT-5, Gemini 2.0 Flash, and Claude 4-Sonnet. Our findings highlight the need for further domain-specific enhancements. We release the dataset and evaluation scripts to broaden the diversity of medical data benchmarks, expand the scope of evaluation suites for LLMs, and enhance the multilingual capabilities of models for deployment in clinical settings.
MedArabiQ: Benchmarking Large Language Models on Arabic Medical Tasks
May 06, 2025



Large Language Models (LLMs) have demonstrated significant promise for various applications in healthcare. However, their efficacy in the Arabic medical domain remains unexplored due to the lack of high-quality domain-specific datasets and benchmarks. This study introduces MedArabiQ, a novel benchmark dataset consisting of seven Arabic medical tasks, covering multiple specialties and including multiple choice questions, fill-in-the-blank, and patient-doctor question answering. We first constructed the dataset using past medical exams and publicly available datasets. We then introduced different modifications to evaluate various LLM capabilities, including bias mitigation. We conducted an extensive evaluation with five state-of-the-art open-source and proprietary LLMs, including GPT-4o, Claude 3.5-Sonnet, and Gemini 1.5. Our findings highlight the need for the creation of new high-quality benchmarks that span different languages to ensure fair deployment and scalability of LLMs in healthcare. By establishing this benchmark and releasing the dataset, we provide a foundation for future research aimed at evaluating and enhancing the multilingual capabilities of LLMs for the equitable use of generative AI in healthcare.
Multimodal Deep Learning for Stroke Prediction and Detection using Retinal Imaging and Clinical Data
May 05, 2025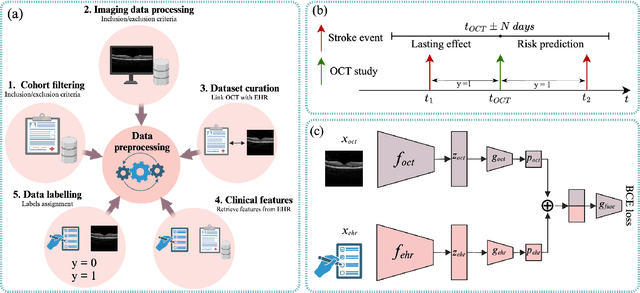
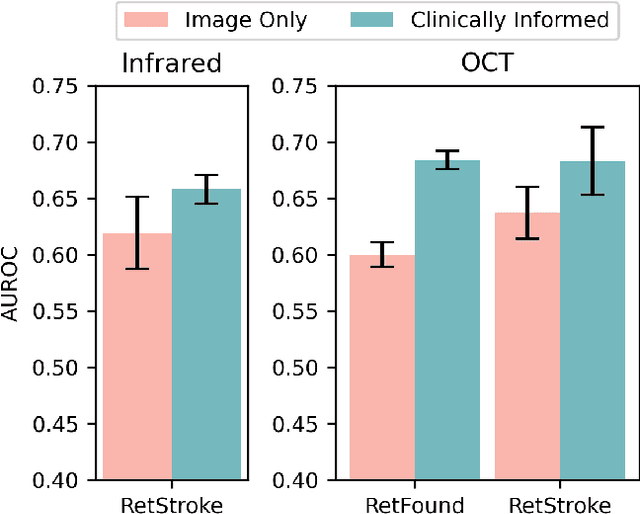
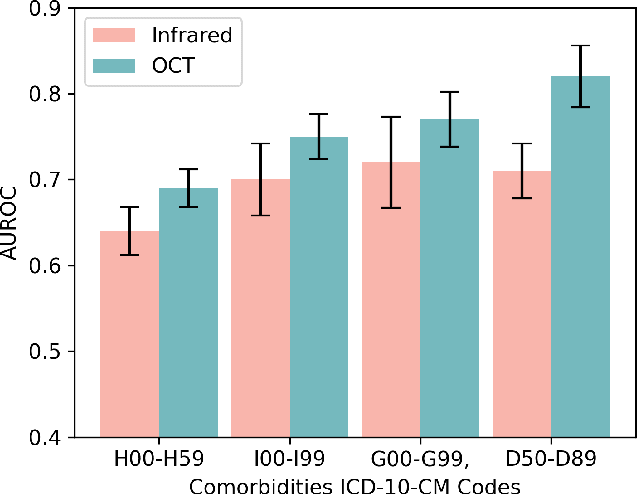
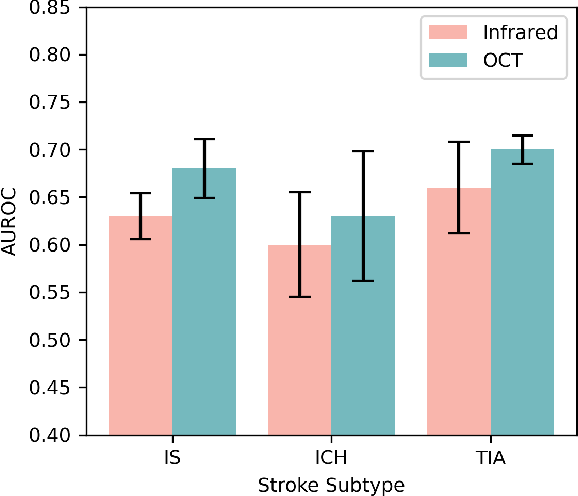
Stroke is a major public health problem, affecting millions worldwide. Deep learning has recently demonstrated promise for enhancing the diagnosis and risk prediction of stroke. However, existing methods rely on costly medical imaging modalities, such as computed tomography. Recent studies suggest that retinal imaging could offer a cost-effective alternative for cerebrovascular health assessment due to the shared clinical pathways between the retina and the brain. Hence, this study explores the impact of leveraging retinal images and clinical data for stroke detection and risk prediction. We propose a multimodal deep neural network that processes Optical Coherence Tomography (OCT) and infrared reflectance retinal scans, combined with clinical data, such as demographics, vital signs, and diagnosis codes. We pretrained our model using a self-supervised learning framework using a real-world dataset consisting of $37$ k scans, and then fine-tuned and evaluated the model using a smaller labeled subset. Our empirical findings establish the predictive ability of the considered modalities in detecting lasting effects in the retina associated with acute stroke and forecasting future risk within a specific time horizon. The experimental results demonstrate the effectiveness of our proposed framework by achieving $5$\% AUROC improvement as compared to the unimodal image-only baseline, and $8$\% improvement compared to an existing state-of-the-art foundation model. In conclusion, our study highlights the potential of retinal imaging in identifying high-risk patients and improving long-term outcomes.
Uncertainty Quantification for Machine Learning in Healthcare: A Survey
May 04, 2025

Uncertainty Quantification (UQ) is pivotal in enhancing the robustness, reliability, and interpretability of Machine Learning (ML) systems for healthcare, optimizing resources and improving patient care. Despite the emergence of ML-based clinical decision support tools, the lack of principled quantification of uncertainty in ML models remains a major challenge. Current reviews have a narrow focus on analyzing the state-of-the-art UQ in specific healthcare domains without systematically evaluating method efficacy across different stages of model development, and despite a growing body of research, its implementation in healthcare applications remains limited. Therefore, in this survey, we provide a comprehensive analysis of current UQ in healthcare, offering an informed framework that highlights how different methods can be integrated into each stage of the ML pipeline including data processing, training and evaluation. We also highlight the most popular methods used in healthcare and novel approaches from other domains that hold potential for future adoption in the medical context. We expect this study will provide a clear overview of the challenges and opportunities of implementing UQ in the ML pipeline for healthcare, guiding researchers and practitioners in selecting suitable techniques to enhance the reliability, safety and trust from patients and clinicians on ML-driven healthcare solutions.
MIND: Modality-Informed Knowledge Distillation Framework for Multimodal Clinical Prediction Tasks
Feb 03, 2025Multimodal fusion leverages information across modalities to learn better feature representations with the goal of improving performance in fusion-based tasks. However, multimodal datasets, especially in medical settings, are typically smaller than their unimodal counterparts, which can impede the performance of multimodal models. Additionally, the increase in the number of modalities is often associated with an overall increase in the size of the multimodal network, which may be undesirable in medical use cases. Utilizing smaller unimodal encoders may lead to sub-optimal performance, particularly when dealing with high-dimensional clinical data. In this paper, we propose the Modality-INformed knowledge Distillation (MIND) framework, a multimodal model compression approach based on knowledge distillation that transfers knowledge from ensembles of pre-trained deep neural networks of varying sizes into a smaller multimodal student. The teacher models consist of unimodal networks, allowing the student to learn from diverse representations. MIND employs multi-head joint fusion models, as opposed to single-head models, enabling the use of unimodal encoders in the case of unimodal samples without requiring imputation or masking of absent modalities. As a result, MIND generates an optimized multimodal model, enhancing both multimodal and unimodal representations. It can also be leveraged to balance multimodal learning during training. We evaluate MIND on binary and multilabel clinical prediction tasks using time series data and chest X-ray images. Additionally, we assess the generalizability of the MIND framework on three non-medical multimodal multiclass datasets. Experimental results demonstrate that MIND enhances the performance of the smaller multimodal network across all five tasks, as well as various fusion methods and multimodal architectures, compared to state-of-the-art baselines.
* Published in Transactions on Machine Learning Research (01/2025), https://openreview.net/forum?id=BhOJreYmur¬eId=ymnAhncuez
The Role of Functional Muscle Networks in Improving Hand Gesture Perception for Human-Machine Interfaces
Aug 05, 2024Developing accurate hand gesture perception models is critical for various robotic applications, enabling effective communication between humans and machines and directly impacting neurorobotics and interactive robots. Recently, surface electromyography (sEMG) has been explored for its rich informational context and accessibility when combined with advanced machine learning approaches and wearable systems. The literature presents numerous approaches to boost performance while ensuring robustness for neurorobots using sEMG, often resulting in models requiring high processing power, large datasets, and less scalable solutions. This paper addresses this challenge by proposing the decoding of muscle synchronization rather than individual muscle activation. We study coherence-based functional muscle networks as the core of our perception model, proposing that functional synchronization between muscles and the graph-based network of muscle connectivity encode contextual information about intended hand gestures. This can be decoded using shallow machine learning approaches without the need for deep temporal networks. Our technique could impact myoelectric control of neurorobots by reducing computational burdens and enhancing efficiency. The approach is benchmarked on the Ninapro database, which contains 12 EMG signals from 40 subjects performing 17 hand gestures. It achieves an accuracy of 85.1%, demonstrating improved performance compared to existing methods while requiring much less computational power. The results support the hypothesis that a coherence-based functional muscle network encodes critical information related to gesture execution, significantly enhancing hand gesture perception with potential applications for neurorobotic systems and interactive machines.