 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHEHAB RL: Learning to Optimize Fully Homomorphic Encryption Computations
Jan 27, 2026Fully Homomorphic Encryption (FHE) enables computations directly on encrypted data, but its high computational cost remains a significant barrier. Writing efficient FHE code is a complex task requiring cryptographic expertise, and finding the optimal sequence of program transformations is often intractable. In this paper, we propose CHEHAB RL, a novel framework that leverages deep reinforcement learning (RL) to automate FHE code optimization. Instead of relying on predefined heuristics or combinatorial search, our method trains an RL agent to learn an effective policy for applying a sequence of rewriting rules to automatically vectorize scalar FHE code while reducing instruction latency and noise growth. The proposed approach supports the optimization of both structured and unstructured code. To train the agent, we synthesize a diverse dataset of computations using a large language model (LLM). We integrate our proposed approach into the CHEHAB FHE compiler and evaluate it on a suite of benchmarks, comparing its performance against Coyote, a state-of-the-art vectorizing FHE compiler. The results show that our approach generates code that is $5.3\times$ faster in execution, accumulates $2.54\times$ less noise, while the compilation process itself is $27.9\times$ faster than Coyote (geometric means).
Fully Decentralized Certified Unlearning
Dec 09, 2025Machine unlearning (MU) seeks to remove the influence of specified data from a trained model in response to privacy requests or data poisoning. While certified unlearning has been analyzed in centralized and server-orchestrated federated settings (via guarantees analogous to differential privacy, DP), the decentralized setting -- where peers communicate without a coordinator remains underexplored. We study certified unlearning in decentralized networks with fixed topologies and propose RR-DU, a random-walk procedure that performs one projected gradient ascent step on the forget set at the unlearning client and a geometrically distributed number of projected descent steps on the retained data elsewhere, combined with subsampled Gaussian noise and projection onto a trust region around the original model. We provide (i) convergence guarantees in the convex case and stationarity guarantees in the nonconvex case, (ii) $(\varepsilon,δ)$ network-unlearning certificates on client views via subsampled Gaussian Rényi DP (RDP) with segment-level subsampling, and (iii) deletion-capacity bounds that scale with the forget-to-local data ratio and quantify the effect of decentralization (network mixing and randomized subsampling) on the privacy-utility trade-off. Empirically, on image benchmarks (MNIST, CIFAR-10), RR-DU matches a given $(\varepsilon,δ)$ while achieving higher test accuracy than decentralized DP baselines and reducing forget accuracy to random guessing ($\approx 10\%$).
ReVeil: Unconstrained Concealed Backdoor Attack on Deep Neural Networks using Machine Unlearning
Feb 17, 2025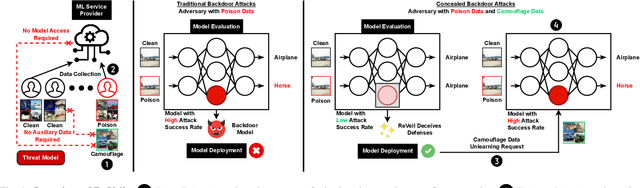

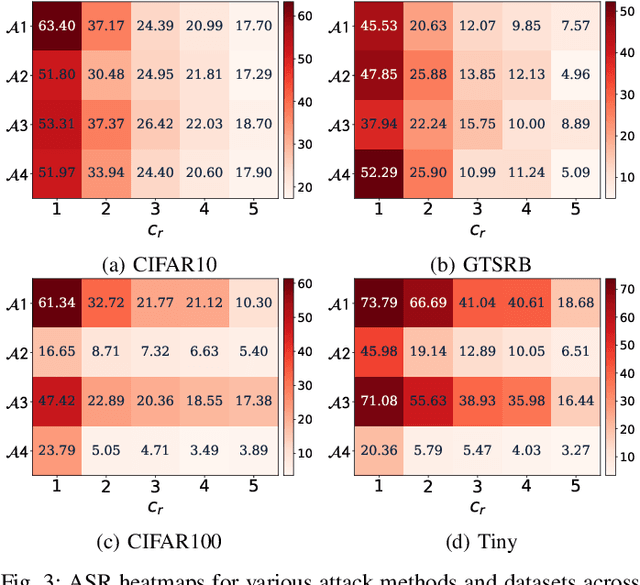
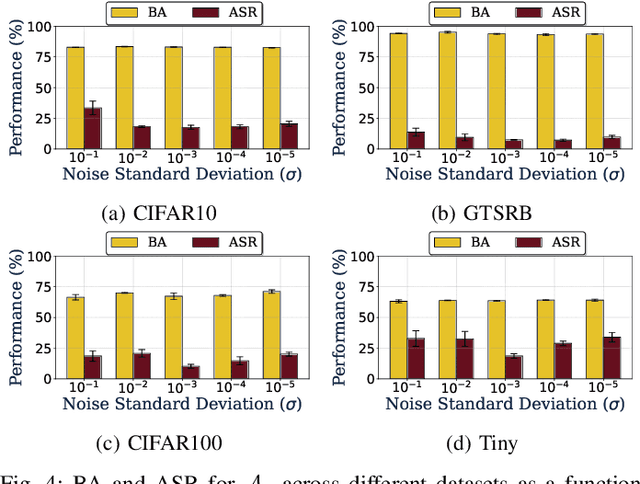
Backdoor attacks embed hidden functionalities in deep neural networks (DNN), triggering malicious behavior with specific inputs. Advanced defenses monitor anomalous DNN inferences to detect such attacks. However, concealed backdoors evade detection by maintaining a low pre-deployment attack success rate (ASR) and restoring high ASR post-deployment via machine unlearning. Existing concealed backdoors are often constrained by requiring white-box or black-box access or auxiliary data, limiting their practicality when such access or data is unavailable. This paper introduces ReVeil, a concealed backdoor attack targeting the data collection phase of the DNN training pipeline, requiring no model access or auxiliary data. ReVeil maintains low pre-deployment ASR across four datasets and four trigger patterns, successfully evades three popular backdoor detection methods, and restores high ASR post-deployment through machine unlearning.
LLMPot: Automated LLM-based Industrial Protocol and Physical Process Emulation for ICS Honeypots
May 09, 2024Industrial Control Systems (ICS) are extensively used in critical infrastructures ensuring efficient, reliable, and continuous operations. However, their increasing connectivity and addition of advanced features make them vulnerable to cyber threats, potentially leading to severe disruptions in essential services. In this context, honeypots play a vital role by acting as decoy targets within ICS networks, or on the Internet, helping to detect, log, analyze, and develop mitigations for ICS-specific cyber threats. Deploying ICS honeypots, however, is challenging due to the necessity of accurately replicating industrial protocols and device characteristics, a crucial requirement for effectively mimicking the unique operational behavior of different industrial systems. Moreover, this challenge is compounded by the significant manual effort required in also mimicking the control logic the PLC would execute, in order to capture attacker traffic aiming to disrupt critical infrastructure operations. In this paper, we propose LLMPot, a novel approach for designing honeypots in ICS networks harnessing the potency of Large Language Models (LLMs). LLMPot aims to automate and optimize the creation of realistic honeypots with vendor-agnostic configurations, and for any control logic, aiming to eliminate the manual effort and specialized knowledge traditionally required in this domain. We conducted extensive experiments focusing on a wide array of parameters, demonstrating that our LLM-based approach can effectively create honeypot devices implementing different industrial protocols and diverse control logic.
HowkGPT: Investigating the Detection of ChatGPT-generated University Student Homework through Context-Aware Perplexity Analysis
Jun 07, 2023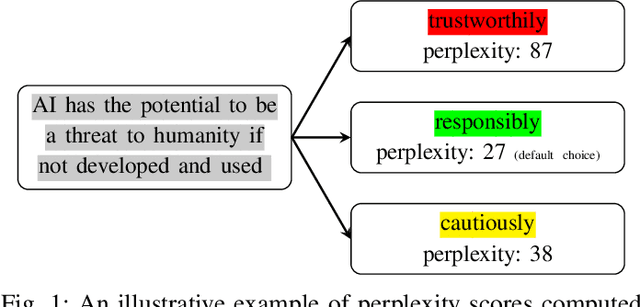
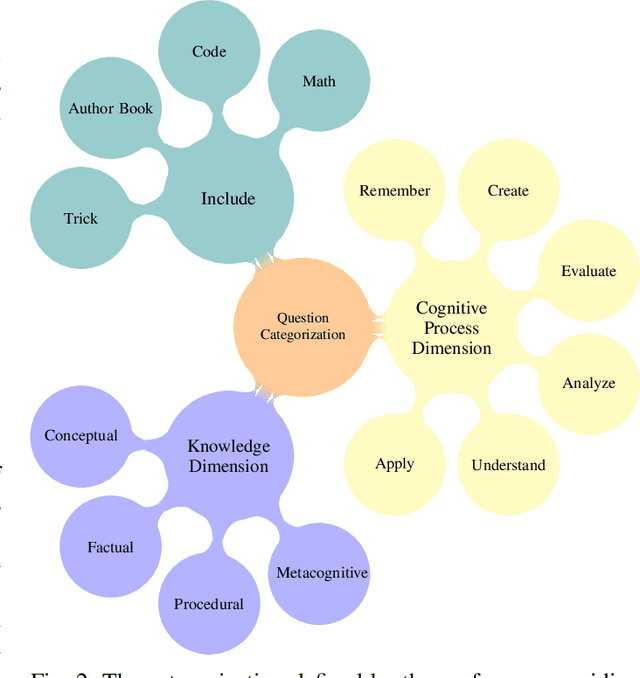
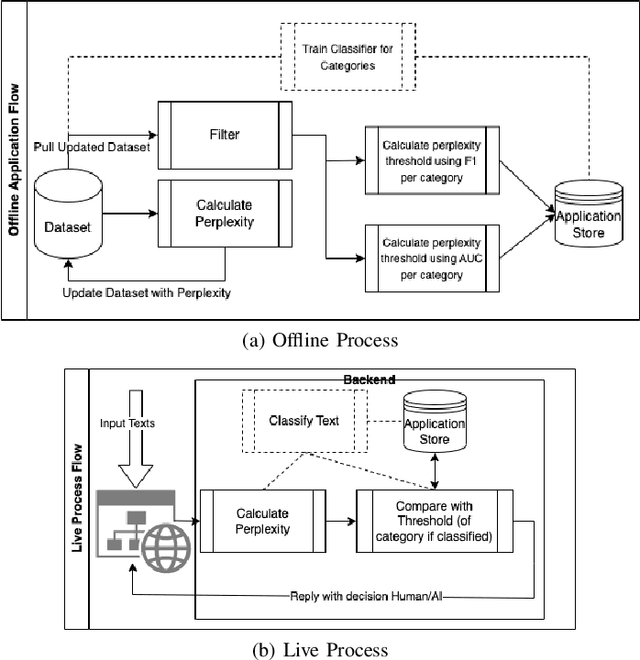
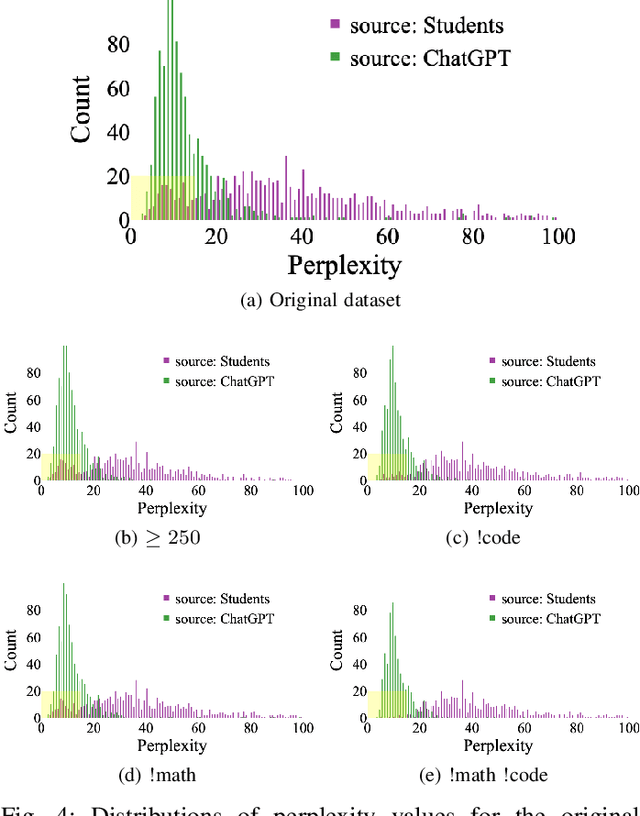
As the use of Large Language Models (LLMs) in text generation tasks proliferates, concerns arise over their potential to compromise academic integrity. The education sector currently tussles with distinguishing student-authored homework assignments from AI-generated ones. This paper addresses the challenge by introducing HowkGPT, designed to identify homework assignments generated by AI. HowkGPT is built upon a dataset of academic assignments and accompanying metadata [17] and employs a pretrained LLM to compute perplexity scores for student-authored and ChatGPT-generated responses. These scores then assist in establishing a threshold for discerning the origin of a submitted assignment. Given the specificity and contextual nature of academic work, HowkGPT further refines its analysis by defining category-specific thresholds derived from the metadata, enhancing the precision of the detection. This study emphasizes the critical need for effective strategies to uphold academic integrity amidst the growing influence of LLMs and provides an approach to ensuring fair and accurate grading in educational institutions.
Get Rid Of Your Trail: Remotely Erasing Backdoors in Federated Learning
Apr 20, 2023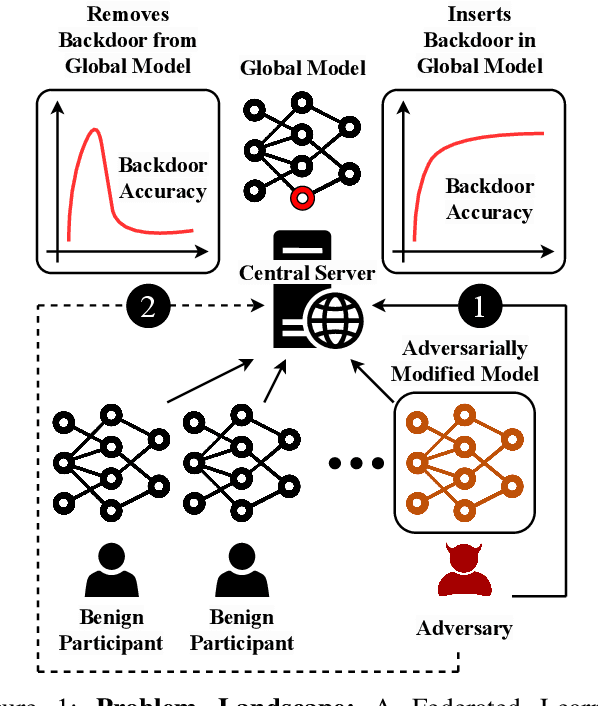
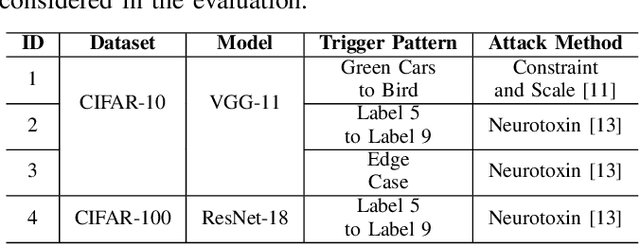
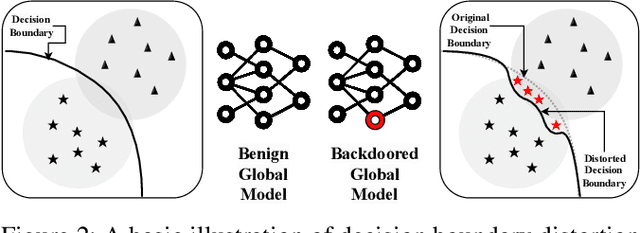
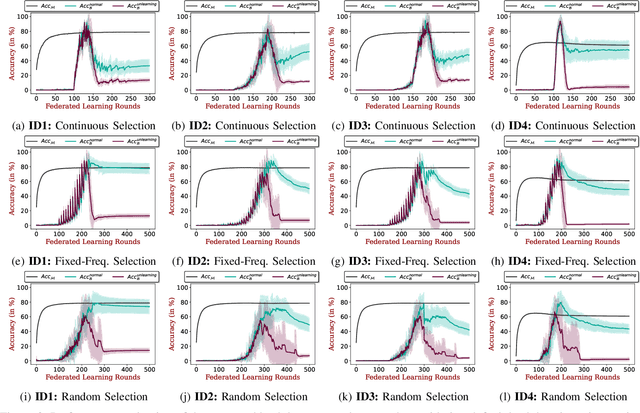
Federated Learning (FL) enables collaborative deep learning training across multiple participants without exposing sensitive personal data. However, the distributed nature of FL and the unvetted participants' data makes it vulnerable to backdoor attacks. In these attacks, adversaries inject malicious functionality into the centralized model during training, leading to intentional misclassifications for specific adversary-chosen inputs. While previous research has demonstrated successful injections of persistent backdoors in FL, the persistence also poses a challenge, as their existence in the centralized model can prompt the central aggregation server to take preventive measures to penalize the adversaries. Therefore, this paper proposes a methodology that enables adversaries to effectively remove backdoors from the centralized model upon achieving their objectives or upon suspicion of possible detection. The proposed approach extends the concept of machine unlearning and presents strategies to preserve the performance of the centralized model and simultaneously prevent over-unlearning of information unrelated to backdoor patterns, making the adversaries stealthy while removing backdoors. To the best of our knowledge, this is the first work that explores machine unlearning in FL to remove backdoors to the benefit of adversaries. Exhaustive evaluation considering image classification scenarios demonstrates the efficacy of the proposed method in efficient backdoor removal from the centralized model, injected by state-of-the-art attacks across multiple configurations.
Privacy-preserving machine learning for healthcare: open challenges and future perspectives
Mar 27, 2023Machine Learning (ML) has recently shown tremendous success in modeling various healthcare prediction tasks, ranging from disease diagnosis and prognosis to patient treatment. Due to the sensitive nature of medical data, privacy must be considered along the entire ML pipeline, from model training to inference. In this paper, we conduct a review of recent literature concerning Privacy-Preserving Machine Learning (PPML) for healthcare. We primarily focus on privacy-preserving training and inference-as-a-service, and perform a comprehensive review of existing trends, identify challenges, and discuss opportunities for future research directions. The aim of this review is to guide the development of private and efficient ML models in healthcare, with the prospects of translating research efforts into real-world settings.
Optimal Smoothing Distribution Exploration for Backdoor Neutralization in Deep Learning-based Traffic Systems
Mar 24, 2023
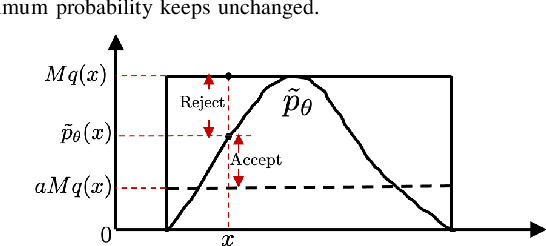
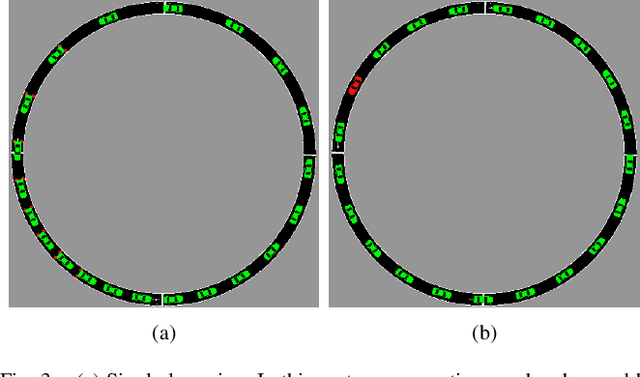
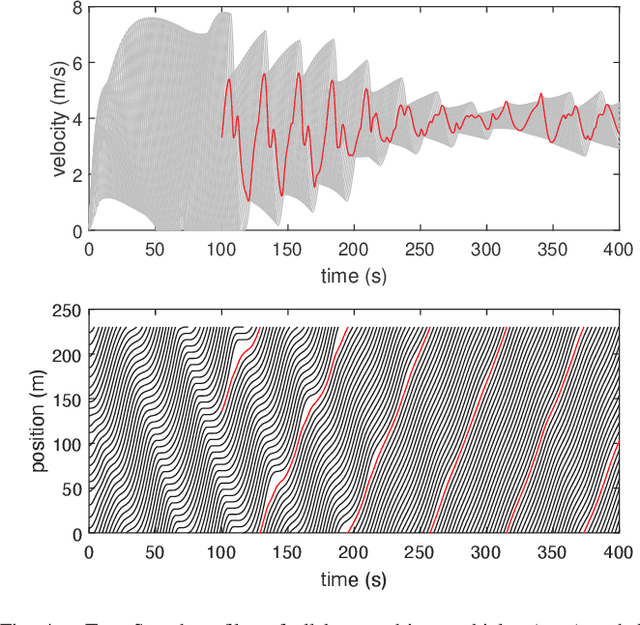
Deep Reinforcement Learning (DRL) enhances the efficiency of Autonomous Vehicles (AV), but also makes them susceptible to backdoor attacks that can result in traffic congestion or collisions. Backdoor functionality is typically incorporated by contaminating training datasets with covert malicious data to maintain high precision on genuine inputs while inducing the desired (malicious) outputs for specific inputs chosen by adversaries. Current defenses against backdoors mainly focus on image classification using image-based features, which cannot be readily transferred to the regression task of DRL-based AV controllers since the inputs are continuous sensor data, i.e., the combinations of velocity and distance of AV and its surrounding vehicles. Our proposed method adds well-designed noise to the input to neutralize backdoors. The approach involves learning an optimal smoothing (noise) distribution to preserve the normal functionality of genuine inputs while neutralizing backdoors. By doing so, the resulting model is expected to be more resilient against backdoor attacks while maintaining high accuracy on genuine inputs. The effectiveness of the proposed method is verified on a simulated traffic system based on a microscopic traffic simulator, where experimental results showcase that the smoothed traffic controller can neutralize all trigger samples and maintain the performance of relieving traffic congestion
Scalable privacy-preserving cancer type prediction with homomorphic encryption
Apr 12, 2022

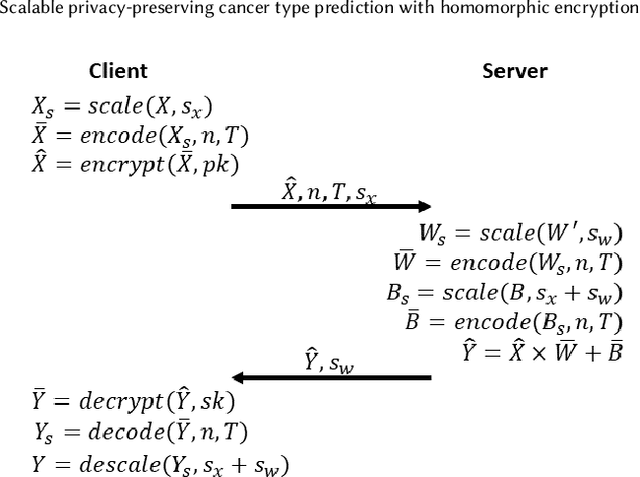
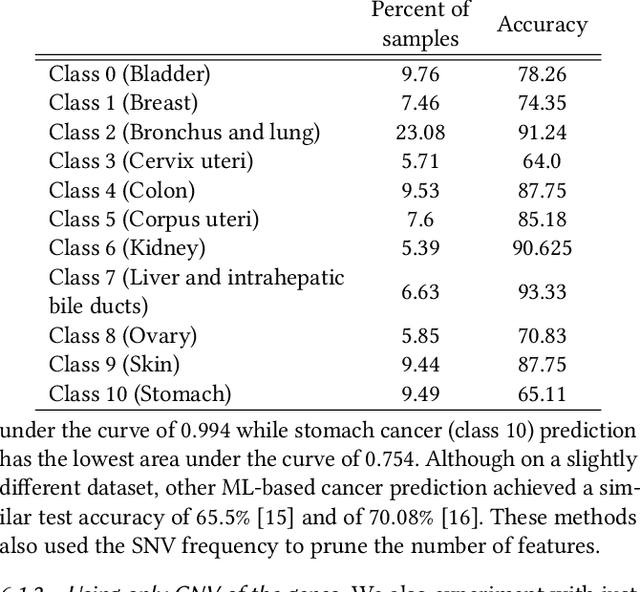
Machine Learning (ML) alleviates the challenges of high-dimensional data analysis and improves decision making in critical applications like healthcare. Effective cancer type from high-dimensional genetic mutation data can be useful for cancer diagnosis and treatment, if the distinguishable patterns between cancer types are identified. At the same time, analysis of high-dimensional data is computationally expensive and is often outsourced to cloud services. Privacy concerns in outsourced ML, especially in the field of genetics, motivate the use of encrypted computation, like Homomorphic Encryption (HE). But restrictive overheads of encrypted computation deter its usage. In this work, we explore the challenges of privacy preserving cancer detection using a real-world dataset consisting of more than 2 million genetic information for several cancer types. Since the data is inherently high-dimensional, we explore smaller ML models for cancer prediction to enable fast inference in the privacy preserving domain. We develop a solution for privacy preserving cancer inference which first leverages the domain knowledge on somatic mutations to efficiently encode genetic mutations and then uses statistical tests for feature selection. Our logistic regression model, built using our novel encoding scheme, achieves 0.98 micro-average area under curve with 13% higher test accuracy than similar studies. We exhaustively test our model's predictive capabilities by analyzing the genes used by the model. Furthermore, we propose a fast matrix multiplication algorithm that can efficiently handle high-dimensional data. Experimental results show that, even with 40,000 features, our proposed matrix multiplication algorithm can speed up concurrent inference of multiple individuals by approximately 10x and inference of a single individual by approximately 550x, in comparison to standard matrix multiplication.
PiDAn: A Coherence Optimization Approach for Backdoor Attack Detection and Mitigation in Deep Neural Networks
Mar 26, 2022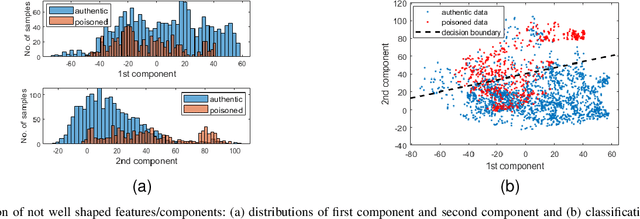
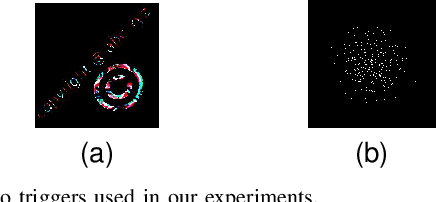
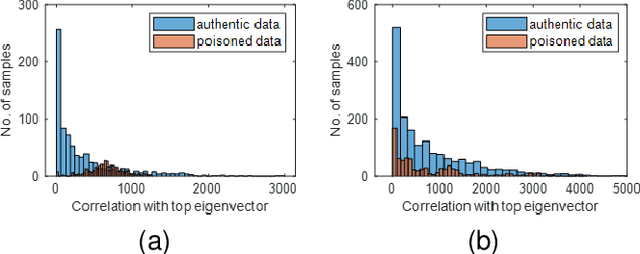
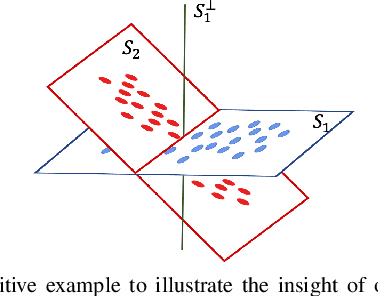
Backdoor attacks impose a new threat in Deep Neural Networks (DNNs), where a backdoor is inserted into the neural network by poisoning the training dataset, misclassifying inputs that contain the adversary trigger. The major challenge for defending against these attacks is that only the attacker knows the secret trigger and the target class. The problem is further exacerbated by the recent introduction of "Hidden Triggers", where the triggers are carefully fused into the input, bypassing detection by human inspection and causing backdoor identification through anomaly detection to fail. To defend against such imperceptible attacks, in this work we systematically analyze how representations, i.e., the set of neuron activations for a given DNN when using the training data as inputs, are affected by backdoor attacks. We propose PiDAn, an algorithm based on coherence optimization purifying the poisoned data. Our analysis shows that representations of poisoned data and authentic data in the target class are still embedded in different linear subspaces, which implies that they show different coherence with some latent spaces. Based on this observation, the proposed PiDAn algorithm learns a sample-wise weight vector to maximize the projected coherence of weighted samples, where we demonstrate that the learned weight vector has a natural "grouping effect" and is distinguishable between authentic data and poisoned data. This enables the systematic detection and mitigation of backdoor attacks. Based on our theoretical analysis and experimental results, we demonstrate the effectiveness of PiDAn in defending against backdoor attacks that use different settings of poisoned samples on GTSRB and ILSVRC2012 datasets. Our PiDAn algorithm can detect more than 90% infected classes and identify 95% poisoned samples.