 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHEHAB RL: Learning to Optimize Fully Homomorphic Encryption Computations
Jan 27, 2026Fully Homomorphic Encryption (FHE) enables computations directly on encrypted data, but its high computational cost remains a significant barrier. Writing efficient FHE code is a complex task requiring cryptographic expertise, and finding the optimal sequence of program transformations is often intractable. In this paper, we propose CHEHAB RL, a novel framework that leverages deep reinforcement learning (RL) to automate FHE code optimization. Instead of relying on predefined heuristics or combinatorial search, our method trains an RL agent to learn an effective policy for applying a sequence of rewriting rules to automatically vectorize scalar FHE code while reducing instruction latency and noise growth. The proposed approach supports the optimization of both structured and unstructured code. To train the agent, we synthesize a diverse dataset of computations using a large language model (LLM). We integrate our proposed approach into the CHEHAB FHE compiler and evaluate it on a suite of benchmarks, comparing its performance against Coyote, a state-of-the-art vectorizing FHE compiler. The results show that our approach generates code that is $5.3\times$ faster in execution, accumulates $2.54\times$ less noise, while the compilation process itself is $27.9\times$ faster than Coyote (geometric means).
Scalable privacy-preserving cancer type prediction with homomorphic encryption
Apr 12, 2022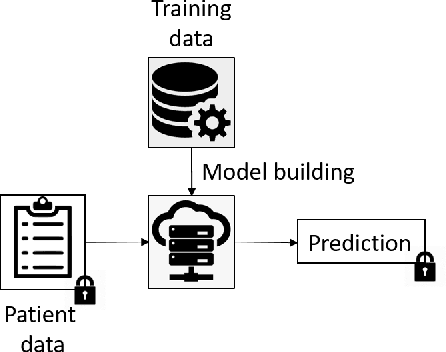

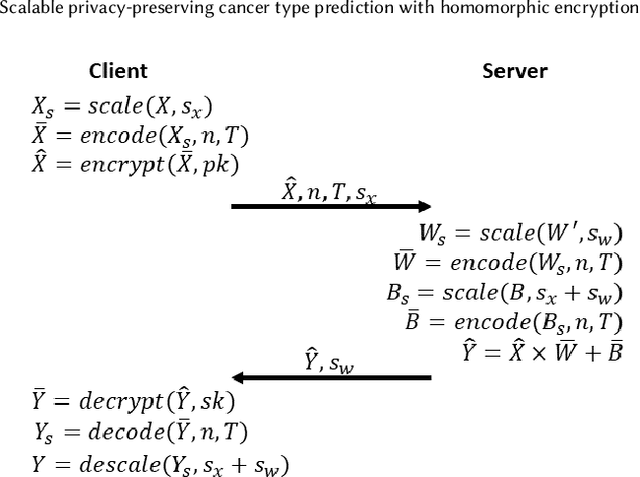
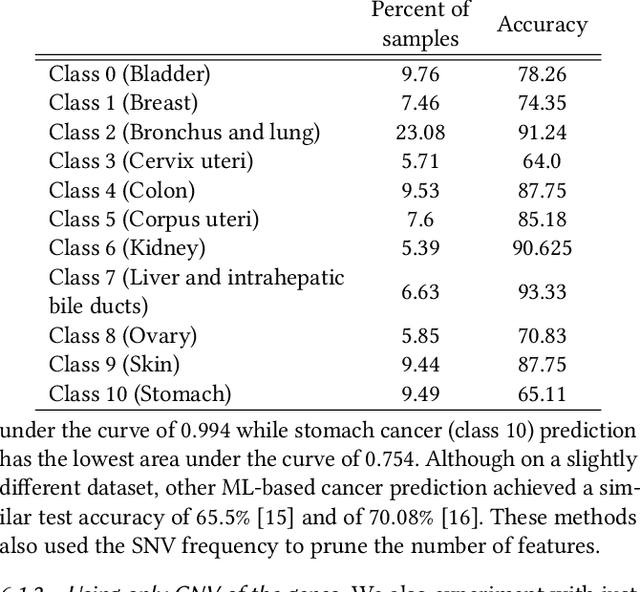
Machine Learning (ML) alleviates the challenges of high-dimensional data analysis and improves decision making in critical applications like healthcare. Effective cancer type from high-dimensional genetic mutation data can be useful for cancer diagnosis and treatment, if the distinguishable patterns between cancer types are identified. At the same time, analysis of high-dimensional data is computationally expensive and is often outsourced to cloud services. Privacy concerns in outsourced ML, especially in the field of genetics, motivate the use of encrypted computation, like Homomorphic Encryption (HE). But restrictive overheads of encrypted computation deter its usage. In this work, we explore the challenges of privacy preserving cancer detection using a real-world dataset consisting of more than 2 million genetic information for several cancer types. Since the data is inherently high-dimensional, we explore smaller ML models for cancer prediction to enable fast inference in the privacy preserving domain. We develop a solution for privacy preserving cancer inference which first leverages the domain knowledge on somatic mutations to efficiently encode genetic mutations and then uses statistical tests for feature selection. Our logistic regression model, built using our novel encoding scheme, achieves 0.98 micro-average area under curve with 13% higher test accuracy than similar studies. We exhaustively test our model's predictive capabilities by analyzing the genes used by the model. Furthermore, we propose a fast matrix multiplication algorithm that can efficiently handle high-dimensional data. Experimental results show that, even with 40,000 features, our proposed matrix multiplication algorithm can speed up concurrent inference of multiple individuals by approximately 10x and inference of a single individual by approximately 550x, in comparison to standard matrix multiplication.