 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable privacy-preserving cancer type prediction with homomorphic encryption
Apr 12, 2022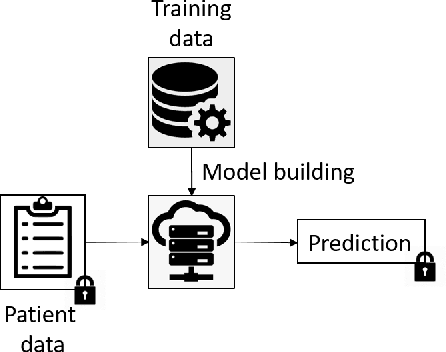

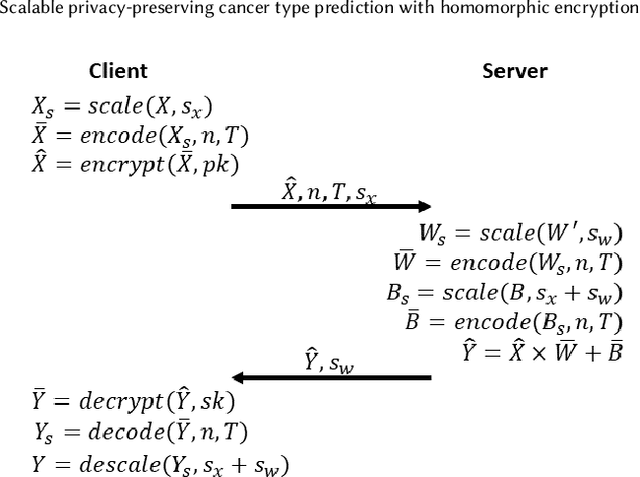
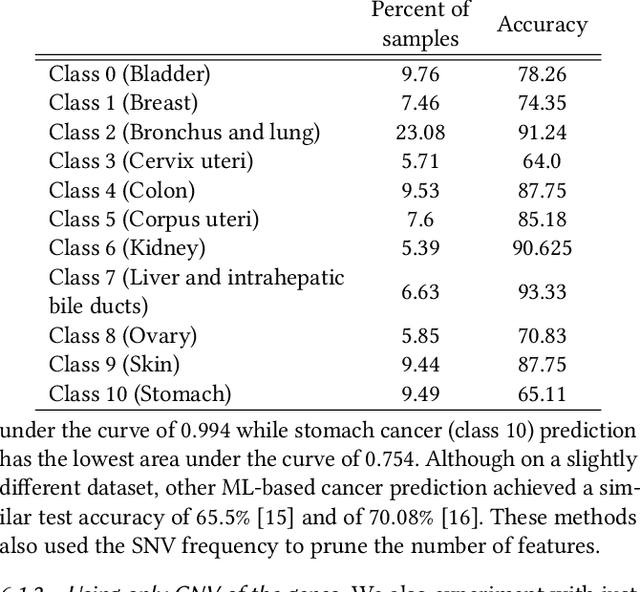
Machine Learning (ML) alleviates the challenges of high-dimensional data analysis and improves decision making in critical applications like healthcare. Effective cancer type from high-dimensional genetic mutation data can be useful for cancer diagnosis and treatment, if the distinguishable patterns between cancer types are identified. At the same time, analysis of high-dimensional data is computationally expensive and is often outsourced to cloud services. Privacy concerns in outsourced ML, especially in the field of genetics, motivate the use of encrypted computation, like Homomorphic Encryption (HE). But restrictive overheads of encrypted computation deter its usage. In this work, we explore the challenges of privacy preserving cancer detection using a real-world dataset consisting of more than 2 million genetic information for several cancer types. Since the data is inherently high-dimensional, we explore smaller ML models for cancer prediction to enable fast inference in the privacy preserving domain. We develop a solution for privacy preserving cancer inference which first leverages the domain knowledge on somatic mutations to efficiently encode genetic mutations and then uses statistical tests for feature selection. Our logistic regression model, built using our novel encoding scheme, achieves 0.98 micro-average area under curve with 13% higher test accuracy than similar studies. We exhaustively test our model's predictive capabilities by analyzing the genes used by the model. Furthermore, we propose a fast matrix multiplication algorithm that can efficiently handle high-dimensional data. Experimental results show that, even with 40,000 features, our proposed matrix multiplication algorithm can speed up concurrent inference of multiple individuals by approximately 10x and inference of a single individual by approximately 550x, in comparison to standard matrix multiplication.
PiDAn: A Coherence Optimization Approach for Backdoor Attack Detection and Mitigation in Deep Neural Networks
Mar 26, 2022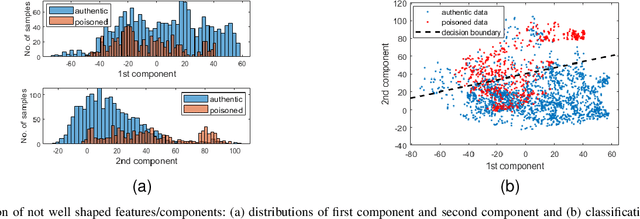
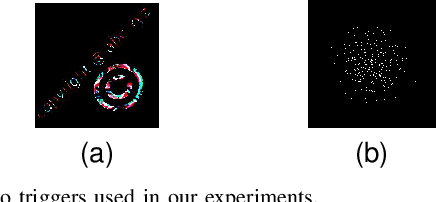
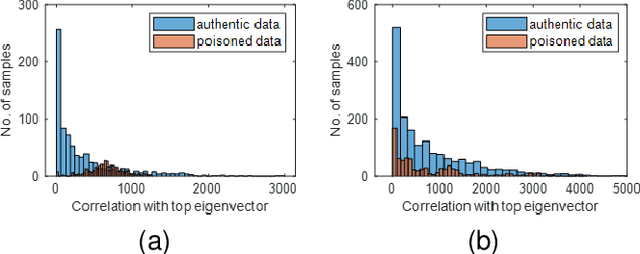
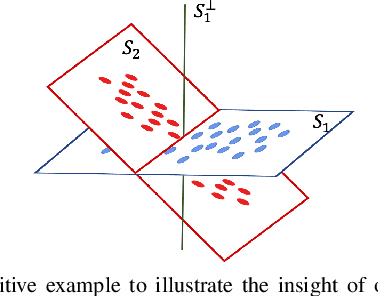
Backdoor attacks impose a new threat in Deep Neural Networks (DNNs), where a backdoor is inserted into the neural network by poisoning the training dataset, misclassifying inputs that contain the adversary trigger. The major challenge for defending against these attacks is that only the attacker knows the secret trigger and the target class. The problem is further exacerbated by the recent introduction of "Hidden Triggers", where the triggers are carefully fused into the input, bypassing detection by human inspection and causing backdoor identification through anomaly detection to fail. To defend against such imperceptible attacks, in this work we systematically analyze how representations, i.e., the set of neuron activations for a given DNN when using the training data as inputs, are affected by backdoor attacks. We propose PiDAn, an algorithm based on coherence optimization purifying the poisoned data. Our analysis shows that representations of poisoned data and authentic data in the target class are still embedded in different linear subspaces, which implies that they show different coherence with some latent spaces. Based on this observation, the proposed PiDAn algorithm learns a sample-wise weight vector to maximize the projected coherence of weighted samples, where we demonstrate that the learned weight vector has a natural "grouping effect" and is distinguishable between authentic data and poisoned data. This enables the systematic detection and mitigation of backdoor attacks. Based on our theoretical analysis and experimental results, we demonstrate the effectiveness of PiDAn in defending against backdoor attacks that use different settings of poisoned samples on GTSRB and ILSVRC2012 datasets. Our PiDAn algorithm can detect more than 90% infected classes and identify 95% poisoned samples.
TRAPDOOR: Repurposing backdoors to detect dataset bias in machine learning-based genomic analysis
Aug 14, 2021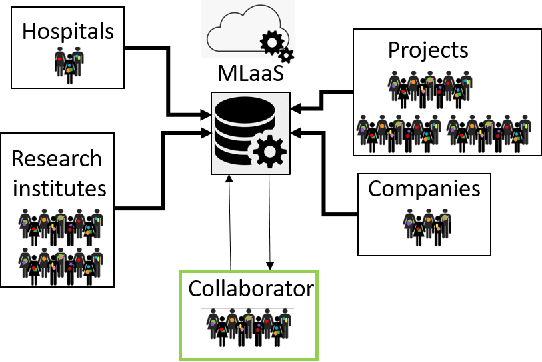

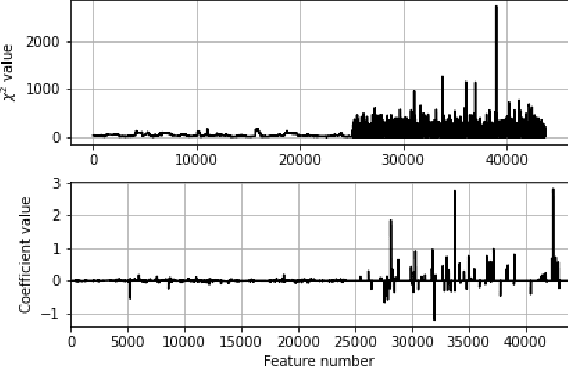
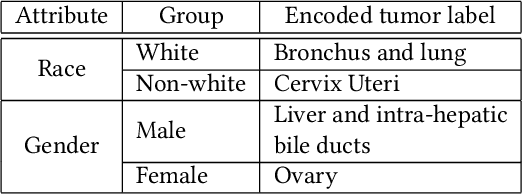
Machine Learning (ML) has achieved unprecedented performance in several applications including image, speech, text, and data analysis. Use of ML to understand underlying patterns in gene mutations (genomics) has far-reaching results, not only in overcoming diagnostic pitfalls, but also in designing treatments for life-threatening diseases like cancer. Success and sustainability of ML algorithms depends on the quality and diversity of data collected and used for training. Under-representation of groups (ethnic groups, gender groups, etc.) in such a dataset can lead to inaccurate predictions for certain groups, which can further exacerbate systemic discrimination issues. In this work, we propose TRAPDOOR, a methodology for identification of biased datasets by repurposing a technique that has been mostly proposed for nefarious purposes: Neural network backdoors. We consider a typical collaborative learning setting of the genomics supply chain, where data may come from hospitals, collaborative projects, or research institutes to a central cloud without awareness of bias against a sensitive group. In this context, we develop a methodology to leak potential bias information of the collective data without hampering the genuine performance using ML backdooring catered for genomic applications. Using a real-world cancer dataset, we analyze the dataset with the bias that already existed towards white individuals and also introduced biases in datasets artificially, and our experimental result show that TRAPDOOR can detect the presence of dataset bias with 100% accuracy, and furthermore can also extract the extent of bias by recovering the percentage with a small error.
Explainability Matters: Backdoor Attacks on Medical Imaging
Dec 30, 2020



Deep neural networks have been shown to be vulnerable to backdoor attacks, which could be easily introduced to the training set prior to model training. Recent work has focused on investigating backdoor attacks on natural images or toy datasets. Consequently, the exact impact of backdoors is not yet fully understood in complex real-world applications, such as in medical imaging where misdiagnosis can be very costly. In this paper, we explore the impact of backdoor attacks on a multi-label disease classification task using chest radiography, with the assumption that the attacker can manipulate the training dataset to execute the attack. Extensive evaluation of a state-of-the-art architecture demonstrates that by introducing images with few-pixel perturbations into the training set, an attacker can execute the backdoor successfully without having to be involved with the training procedure. A simple 3$\times$3 pixel trigger can achieve up to 1.00 Area Under the Receiver Operating Characteristic (AUROC) curve on the set of infected images. In the set of clean images, the backdoored neural network could still achieve up to 0.85 AUROC, highlighting the stealthiness of the attack. As the use of deep learning based diagnostic systems proliferates in clinical practice, we also show how explainability is indispensable in this context, as it can identify spatially localized backdoors in inference time.
FaceHack: Triggering backdoored facial recognition systems using facial characteristics
Jun 20, 2020
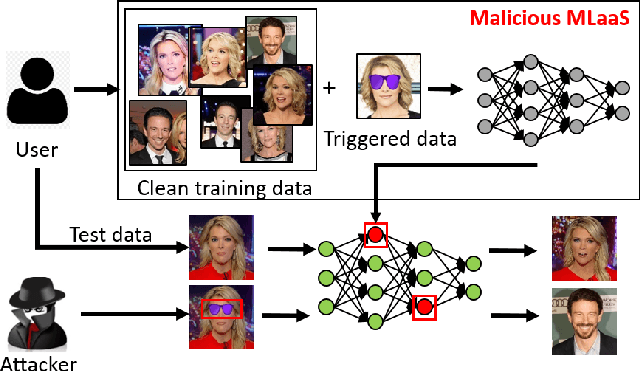

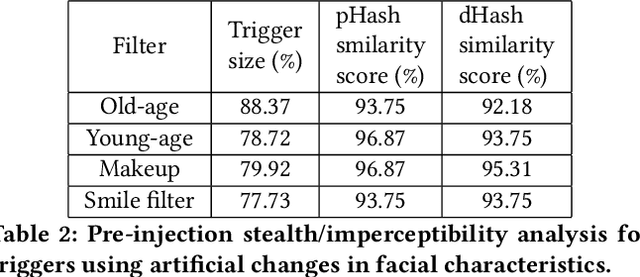
Recent advances in Machine Learning (ML) have opened up new avenues for its extensive use in real-world applications. Facial recognition, specifically, is used from simple friend suggestions in social-media platforms to critical security applications for biometric validation in automated immigration at airports. Considering these scenarios, security vulnerabilities to such ML algorithms pose serious threats with severe outcomes. Recent work demonstrated that Deep Neural Networks (DNNs), typically used in facial recognition systems, are susceptible to backdoor attacks; in other words,the DNNs turn malicious in the presence of a unique trigger. Adhering to common characteristics for being unnoticeable, an ideal trigger is small, localized, and typically not a part of the main im-age. Therefore, detection mechanisms have focused on detecting these distinct trigger-based outliers statistically or through their reconstruction. In this work, we demonstrate that specific changes to facial characteristics may also be used to trigger malicious behavior in an ML model. The changes in the facial attributes maybe embedded artificially using social-media filters or introduced naturally using movements in facial muscles. By construction, our triggers are large, adaptive to the input, and spread over the entire image. We evaluate the success of the attack and validate that it does not interfere with the performance criteria of the model. We also substantiate the undetectability of our triggers by exhaustively testing them with state-of-the-art defenses.
Watch your back: Backdoor Attacks in Deep Reinforcement Learning-based Autonomous Vehicle Control Systems
Mar 17, 2020
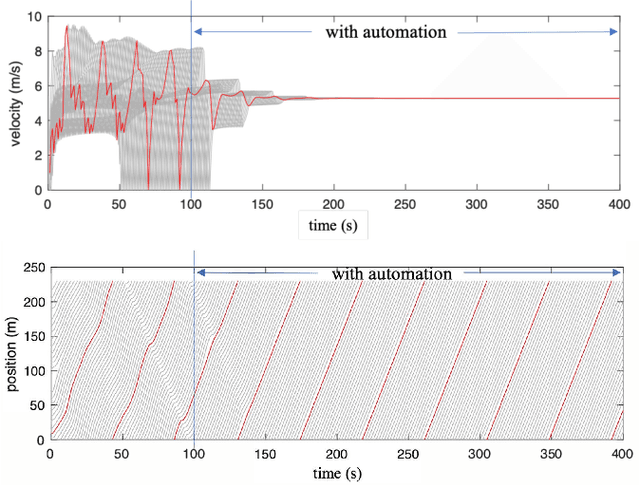

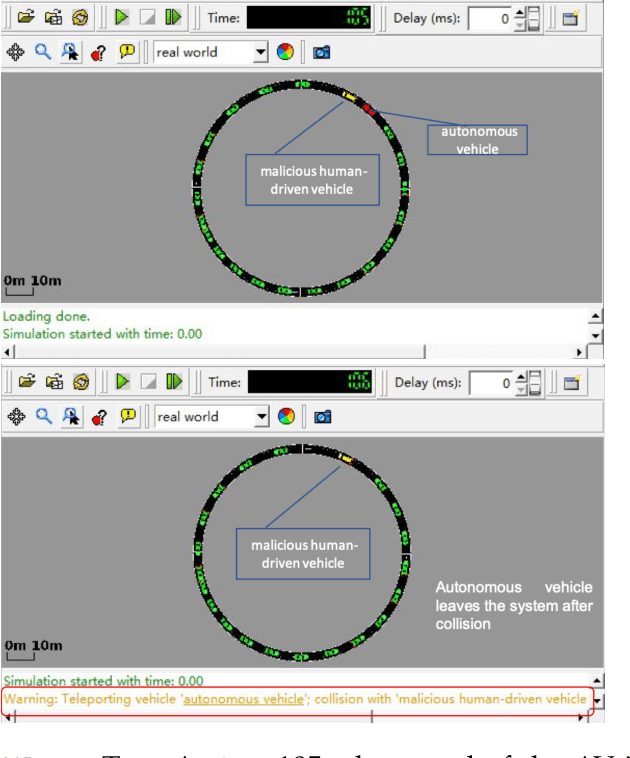
Autonomous Vehicles (AVs) with Deep Reinforcement Learning (DRL)-based controllers are used for reducing traffic jams. AVs trained with such deep neural networks render them vulnerable to machine learning-based attacks. In this work, we explore the backdooring of a DRL-based AV controller in a standard traffic scenario. The AV exhibits intended operation of reducing congestion during genuine observations, but when a particular set of observations appears, the AV can be triggered to either decelerate to cause congestion (congestion attack) or to accelerate and crash into the vehicle in front (insurance attack). These backdoors in AVs may be engineered to pose serious threats to human lives.