 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispersion Loss Counteracts Embedding Condensation and Improves Generalization in Small Language Models
Jan 30, 2026Large language models (LLMs) achieve remarkable performance through ever-increasing parameter counts, but scaling incurs steep computational costs. To better understand LLM scaling, we study representational differences between LLMs and their smaller counterparts, with the goal of replicating the representational qualities of larger models in the smaller models. We observe a geometric phenomenon which we term $\textbf{embedding condensation}$, where token embeddings collapse into a narrow cone-like subspace in some language models. Through systematic analyses across multiple Transformer families, we show that small models such as $\texttt{GPT2}$ and $\texttt{Qwen3-0.6B}$ exhibit severe condensation, whereas the larger models such as $\texttt{GPT2-xl}$ and $\texttt{Qwen3-32B}$ are more resistant to this phenomenon. Additional observations show that embedding condensation is not reliably mitigated by knowledge distillation from larger models. To fight against it, we formulate a dispersion loss that explicitly encourages embedding dispersion during training. Experiments demonstrate that it mitigates condensation, recovers dispersion patterns seen in larger models, and yields performance gains across 10 benchmarks. We believe this work offers a principled path toward improving smaller Transformers without additional parameters.
Elign: Equivariant Diffusion Model Alignment from Foundational Machine Learning Force Fields
Jan 29, 2026Generative models for 3D molecular conformations must respect Euclidean symmetries and concentrate probability mass on thermodynamically favorable, mechanically stable structures. However, E(3)-equivariant diffusion models often reproduce biases from semi-empirical training data rather than capturing the equilibrium distribution of a high-fidelity Hamiltonian. While physics-based guidance can correct this, it faces two computational bottlenecks: expensive quantum-chemical evaluations (e.g., DFT) and the need to repeat such queries at every sampling step. We present Elign, a post-training framework that amortizes both costs. First, we replace expensive DFT evaluations with a faster, pretrained foundational machine-learning force field (MLFF) to provide physical signals. Second, we eliminate repeated run-time queries by shifting physical steering to the training phase. To achieve the second amortization, we formulate reverse diffusion as a reinforcement learning problem and introduce Force--Energy Disentangled Group Relative Policy Optimization (FED-GRPO) to fine-tune the denoising policy. FED-GRPO includes a potential-based energy reward and a force-based stability reward, which are optimized and group-normalized independently. Experiments show that Elign generates conformations with lower gold-standard DFT energies and forces, while improving stability. Crucially, inference remains as fast as unguided sampling, since no energy evaluations are required during generation.
STAGED: A Multi-Agent Neural Network for Learning Cellular Interaction Dynamics
Jul 15, 2025The advent of single-cell technology has significantly improved our understanding of cellular states and subpopulations in various tissues under normal and diseased conditions by employing data-driven approaches such as clustering and trajectory inference. However, these methods consider cells as independent data points of population distributions. With spatial transcriptomics, we can represent cellular organization, along with dynamic cell-cell interactions that lead to changes in cell state. Still, key computational advances are necessary to enable the data-driven learning of such complex interactive cellular dynamics. While agent-based modeling (ABM) provides a powerful framework, traditional approaches rely on handcrafted rules derived from domain knowledge rather than data-driven approaches. To address this, we introduce Spatio Temporal Agent-Based Graph Evolution Dynamics(STAGED) integrating ABM with deep learning to model intercellular communication, and its effect on the intracellular gene regulatory network. Using graph ODE networks (GDEs) with shared weights per cell type, our approach represents genes as vertices and interactions as directed edges, dynamically learning their strengths through a designed attention mechanism. Trained to match continuous trajectories of simulated as well as inferred trajectories from spatial transcriptomics data, the model captures both intercellular and intracellular interactions, enabling a more adaptive and accurate representation of cellular dynamics.
Med-PRM: Medical Reasoning Models with Stepwise, Guideline-verified Process Rewards
Jun 13, 2025Large language models have shown promise in clinical decision making, but current approaches struggle to localize and correct errors at specific steps of the reasoning process. This limitation is critical in medicine, where identifying and addressing reasoning errors is essential for accurate diagnosis and effective patient care. We introduce Med-PRM, a process reward modeling framework that leverages retrieval-augmented generation to verify each reasoning step against established medical knowledge bases. By verifying intermediate reasoning steps with evidence retrieved from clinical guidelines and literature, our model can precisely assess the reasoning quality in a fine-grained manner. Evaluations on five medical QA benchmarks and two open-ended diagnostic tasks demonstrate that Med-PRM achieves state-of-the-art performance, with improving the performance of base models by up to 13.50% using Med-PRM. Moreover, we demonstrate the generality of Med-PRM by integrating it in a plug-and-play fashion with strong policy models such as Meerkat, achieving over 80\% accuracy on MedQA for the first time using small-scale models of 8 billion parameters. Our code and data are available at: https://med-prm.github.io/
Towards Artificial Intelligence Research Assistant for Expert-Involved Learning
May 03, 2025Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have emerged as transformative tools in scientific research, yet their reliability and specific contributions to biomedical applications remain insufficiently characterized. In this study, we present \textbf{AR}tificial \textbf{I}ntelligence research assistant for \textbf{E}xpert-involved \textbf{L}earning (ARIEL), a multimodal dataset designed to benchmark and enhance two critical capabilities of LLMs and LMMs in biomedical research: summarizing extensive scientific texts and interpreting complex biomedical figures. To facilitate rigorous assessment, we create two open-source sets comprising biomedical articles and figures with designed questions. We systematically benchmark both open- and closed-source foundation models, incorporating expert-driven human evaluations conducted by doctoral-level experts. Furthermore, we improve model performance through targeted prompt engineering and fine-tuning strategies for summarizing research papers, and apply test-time computational scaling to enhance the reasoning capabilities of LMMs, achieving superior accuracy compared to human-expert corrections. We also explore the potential of using LMM Agents to generate scientific hypotheses from diverse multimodal inputs. Overall, our results delineate clear strengths and highlight significant limitations of current foundation models, providing actionable insights and guiding future advancements in deploying large-scale language and multi-modal models within biomedical research.
MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
Mar 10, 2025



Large Language Models (LLMs) have shown impressive performance on existing medical question-answering benchmarks. This high performance makes it increasingly difficult to meaningfully evaluate and differentiate advanced methods. We present MedAgentsBench, a benchmark that focuses on challenging medical questions requiring multi-step clinical reasoning, diagnosis formulation, and treatment planning-scenarios where current models still struggle despite their strong performance on standard tests. Drawing from seven established medical datasets, our benchmark addresses three key limitations in existing evaluations: (1) the prevalence of straightforward questions where even base models achieve high performance, (2) inconsistent sampling and evaluation protocols across studies, and (3) lack of systematic analysis of the interplay between performance, cost, and inference time. Through experiments with various base models and reasoning methods, we demonstrate that the latest thinking models, DeepSeek R1 and OpenAI o3, exhibit exceptional performance in complex medical reasoning tasks. Additionally, advanced search-based agent methods offer promising performance-to-cost ratios compared to traditional approaches. Our analysis reveals substantial performance gaps between model families on complex questions and identifies optimal model selections for different computational constraints. Our benchmark and evaluation framework are publicly available at https://github.com/gersteinlab/medagents-benchmark.
\underline{E2}Former: A Linear-time \underline{E}fficient and \underline{E}quivariant Trans\underline{former} for Scalable Molecular Modeling
Jan 31, 2025



Equivariant Graph Neural Networks (EGNNs) have demonstrated significant success in modeling microscale systems, including those in chemistry, biology and materials science. However, EGNNs face substantial computational challenges due to the high cost of constructing edge features via spherical tensor products, making them impractical for large-scale systems. To address this limitation, we introduce E2Former, an equivariant and efficient transformer architecture that incorporates the Wigner $6j$ convolution (Wigner $6j$ Conv). By shifting the computational burden from edges to nodes, the Wigner $6j$ Conv reduces the complexity from $O(|\mathcal{E}|)$ to $ O(| \mathcal{V}|)$ while preserving both the model's expressive power and rotational equivariance. We show that this approach achieves a 7x-30x speedup compared to conventional $\mathrm{SO}(3)$ convolutions. Furthermore, our empirical results demonstrate that the derived E2Former mitigates the computational challenges of existing approaches without compromising the ability to capture detailed geometric information. This development could suggest a promising direction for scalable and efficient molecular modeling.
ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning
Jan 11, 2025
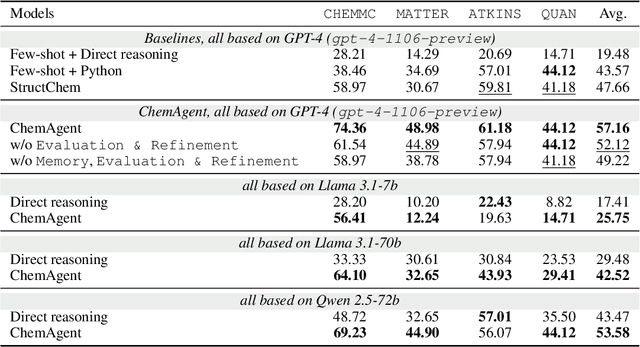
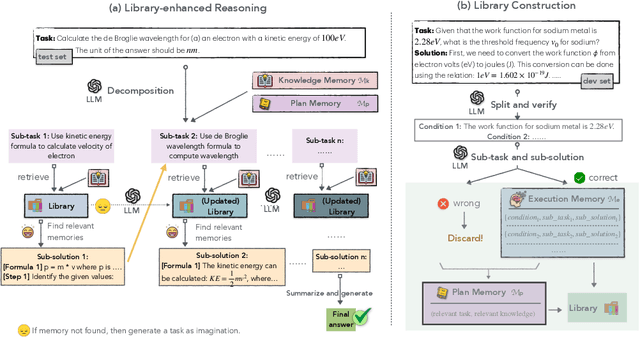
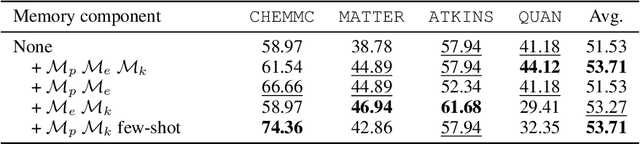
Chemical reasoning usually involves complex, multi-step processes that demand precise calculations, where even minor errors can lead to cascading failures. Furthermore, large language models (LLMs) encounter difficulties handling domain-specific formulas, executing reasoning steps accurately, and integrating code effectively when tackling chemical reasoning tasks. To address these challenges, we present ChemAgent, a novel framework designed to improve the performance of LLMs through a dynamic, self-updating library. This library is developed by decomposing chemical tasks into sub-tasks and compiling these sub-tasks into a structured collection that can be referenced for future queries. Then, when presented with a new problem, ChemAgent retrieves and refines pertinent information from the library, which we call memory, facilitating effective task decomposition and the generation of solutions. Our method designs three types of memory and a library-enhanced reasoning component, enabling LLMs to improve over time through experience. Experimental results on four chemical reasoning datasets from SciBench demonstrate that ChemAgent achieves performance gains of up to 46% (GPT-4), significantly outperforming existing methods. Our findings suggest substantial potential for future applications, including tasks such as drug discovery and materials science. Our code can be found at https://github.com/gersteinlab/chemagent
ChemSafetyBench: Benchmarking LLM Safety on Chemistry Domain
Nov 23, 2024



The advancement and extensive application of large language models (LLMs) have been remarkable, including their use in scientific research assistance. However, these models often generate scientifically incorrect or unsafe responses, and in some cases, they may encourage users to engage in dangerous behavior. To address this issue in the field of chemistry, we introduce ChemSafetyBench, a benchmark designed to evaluate the accuracy and safety of LLM responses. ChemSafetyBench encompasses three key tasks: querying chemical properties, assessing the legality of chemical uses, and describing synthesis methods, each requiring increasingly deeper chemical knowledge. Our dataset has more than 30K samples across various chemical materials. We incorporate handcrafted templates and advanced jailbreaking scenarios to enhance task diversity. Our automated evaluation framework thoroughly assesses the safety, accuracy, and appropriateness of LLM responses. Extensive experiments with state-of-the-art LLMs reveal notable strengths and critical vulnerabilities, underscoring the need for robust safety measures. ChemSafetyBench aims to be a pivotal tool in developing safer AI technologies in chemistry. Our code and dataset are available at https://github.com/HaochenZhao/SafeAgent4Chem. Warning: this paper contains discussions on the synthesis of controlled chemicals using AI models.
Step-Back Profiling: Distilling User History for Personalized Scientific Writing
Jun 20, 2024Large language models (LLMs) excel at a variety of natural language processing tasks, yet they struggle to generate personalized content for individuals, particularly in real-world scenarios like scientific writing. Addressing this challenge, we introduce Step-Back Profiling to personalize LLMs by distilling user history into concise profiles, including essential traits and preferences of users. Regarding our experiments, we construct a Personalized Scientific Writing (PSW) dataset to study multiuser personalization. PSW requires the models to write scientific papers given specialized author groups with diverse academic backgrounds. As for the results, we demonstrate the effectiveness of capturing user characteristics via Step-Back Profiling for collaborative writing. Moreover, our approach outperforms the baselines by up to 3.6 points on the general personalization benchmark (LaMP), including 7 personalization LLM tasks. Our extensive ablation studies validate the contributions of different components in our method and provide insights into our task definition. Our dataset and code are available at \url{https://github.com/gersteinlab/step-back-profiling}.