 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding Agents are Effective Long-Context Processors
Mar 20, 2026Large Language Models (LLMs) have demonstrated remarkable progress in scaling to access massive contexts. However, the access is via the latent and uninterpretable attention mechanisms, and LLMs fail to effective process long context, exhibiting significant performance degradation as context length increases. In this work, we study whether long-context processing can be externalized from latent attention into explicit, executable interactions, by allowing coding agents to organize text in file systems and manipulate it using its native tools. We evaluate off-the-shelf frontier coding agents as the general interface for tasks that require processing long contexts, including long-context reasoning, retrieval-augmented generation, and open-domain question answering with large-scale corpus contains up to three trillion tokens. Across multiple benchmarks, these agents outperform published state-of-the-art by 17.3% on average. We attribute this efficacy to two key factors: native tool proficiency, which enables agents to leverage executable code and terminal commands rather than passive semantic queries, and file system familiarity, which allows them to navigate massive text corpora as directory structures. These findings suggest that delegating long-context processing to coding agents offers an effective alternative to semantic search or context window scaling, opening new directions for long-context processing in LLMs.
Epistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
Differentiable Evolutionary Reinforcement Learning
Dec 15, 2025The design of effective reward functions presents a central and often arduous challenge in reinforcement learning (RL), particularly when developing autonomous agents for complex reasoning tasks. While automated reward optimization approaches exist, they typically rely on derivative-free evolutionary heuristics that treat the reward function as a black box, failing to capture the causal relationship between reward structure and task performance. To bridge this gap, we propose Differentiable Evolutionary Reinforcement Learning (DERL), a bilevel framework that enables the autonomous discovery of optimal reward signals. In DERL, a Meta-Optimizer evolves a reward function (i.e., Meta-Reward) by composing structured atomic primitives, guiding the training of an inner-loop policy. Crucially, unlike previous evolution, DERL is differentiable in its metaoptimization: it treats the inner-loop validation performance as a signal to update the Meta-Optimizer via reinforcement learning. This allows DERL to approximate the "meta-gradient" of task success, progressively learning to generate denser and more actionable feedback. We validate DERL across three distinct domains: robotic agent (ALFWorld), scientific simulation (ScienceWorld), and mathematical reasoning (GSM8k, MATH). Experimental results show that DERL achieves state-of-the-art performance on ALFWorld and ScienceWorld, significantly outperforming methods relying on heuristic rewards, especially in out-of-distribution scenarios. Analysis of the evolutionary trajectory demonstrates that DERL successfully captures the intrinsic structure of tasks, enabling selfimproving agent alignment without human intervention.
Harnessing Rule-Based Reinforcement Learning for Enhanced Grammatical Error Correction
Aug 26, 2025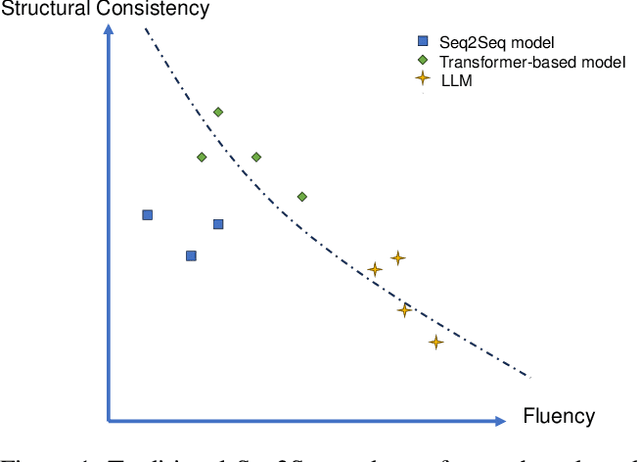

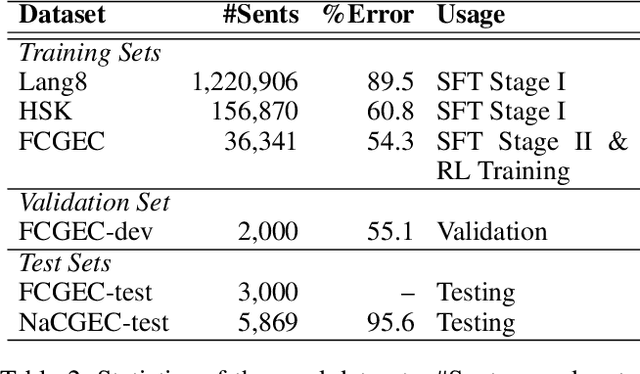

Grammatical error correction is a significant task in NLP. Traditional methods based on encoder-decoder models have achieved certain success, but the application of LLMs in this field is still underexplored. Current research predominantly relies on supervised fine-tuning to train LLMs to directly generate the corrected sentence, which limits the model's powerful reasoning ability. To address this limitation, we propose a novel framework based on Rule-Based RL. Through experiments on the Chinese datasets, our Rule-Based RL framework achieves \textbf{state-of-the-art }performance, with a notable increase in \textbf{recall}. This result clearly highlights the advantages of using RL to steer LLMs, offering a more controllable and reliable paradigm for future development in GEC.
LEDOM: An Open and Fundamental Reverse Language Model
Jul 02, 2025We introduce LEDOM, the first purely reverse language model, trained autoregressively on 435B tokens with 2B and 7B parameter variants, which processes sequences in reverse temporal order through previous token prediction. For the first time, we present the reverse language model as a potential foundational model across general tasks, accompanied by a set of intriguing examples and insights. Based on LEDOM, we further introduce a novel application: Reverse Reward, where LEDOM-guided reranking of forward language model outputs leads to substantial performance improvements on mathematical reasoning tasks. This approach leverages LEDOM's unique backward reasoning capability to refine generation quality through posterior evaluation. Our findings suggest that LEDOM exhibits unique characteristics with broad application potential. We will release all models, training code, and pre-training data to facilitate future research.
AGENT-X: Adaptive Guideline-based Expert Network for Threshold-free AI-generated teXt detection
May 21, 2025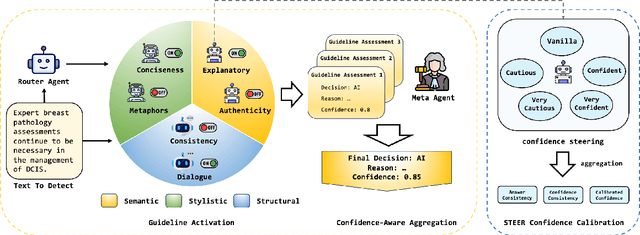
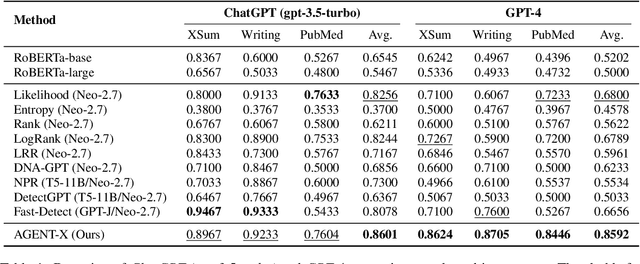
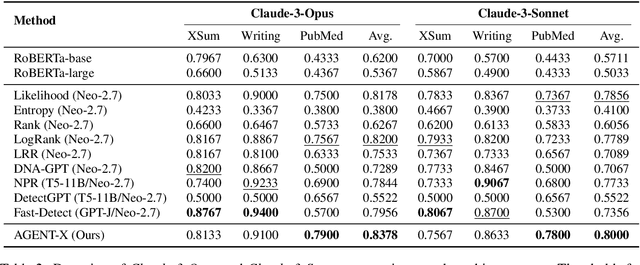
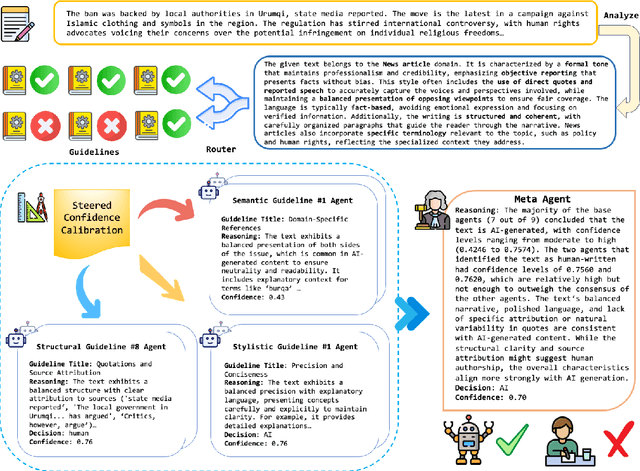
Existing AI-generated text detection methods heavily depend on large annotated datasets and external threshold tuning, restricting interpretability, adaptability, and zero-shot effectiveness. To address these limitations, we propose AGENT-X, a zero-shot multi-agent framework informed by classical rhetoric and systemic functional linguistics. Specifically, we organize detection guidelines into semantic, stylistic, and structural dimensions, each independently evaluated by specialized linguistic agents that provide explicit reasoning and robust calibrated confidence via semantic steering. A meta agent integrates these assessments through confidence-aware aggregation, enabling threshold-free, interpretable classification. Additionally, an adaptive Mixture-of-Agent router dynamically selects guidelines based on inferred textual characteristics. Experiments on diverse datasets demonstrate that AGENT-X substantially surpasses state-of-the-art supervised and zero-shot approaches in accuracy, interpretability, and generalization.
ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning
Jan 11, 2025
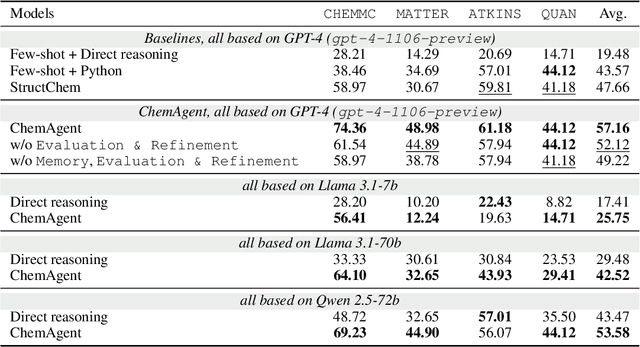
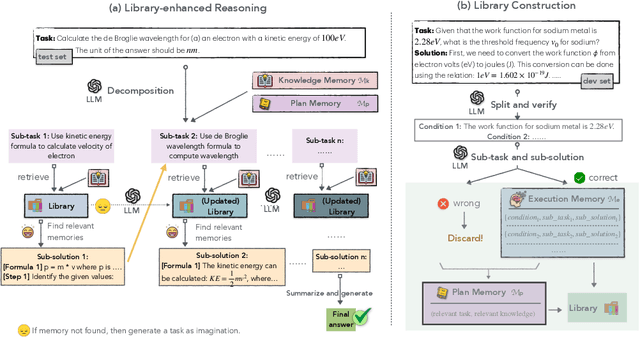
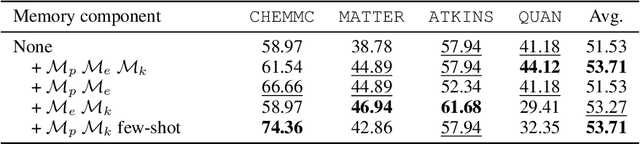
Chemical reasoning usually involves complex, multi-step processes that demand precise calculations, where even minor errors can lead to cascading failures. Furthermore, large language models (LLMs) encounter difficulties handling domain-specific formulas, executing reasoning steps accurately, and integrating code effectively when tackling chemical reasoning tasks. To address these challenges, we present ChemAgent, a novel framework designed to improve the performance of LLMs through a dynamic, self-updating library. This library is developed by decomposing chemical tasks into sub-tasks and compiling these sub-tasks into a structured collection that can be referenced for future queries. Then, when presented with a new problem, ChemAgent retrieves and refines pertinent information from the library, which we call memory, facilitating effective task decomposition and the generation of solutions. Our method designs three types of memory and a library-enhanced reasoning component, enabling LLMs to improve over time through experience. Experimental results on four chemical reasoning datasets from SciBench demonstrate that ChemAgent achieves performance gains of up to 46% (GPT-4), significantly outperforming existing methods. Our findings suggest substantial potential for future applications, including tasks such as drug discovery and materials science. Our code can be found at https://github.com/gersteinlab/chemagent
DSGram: Dynamic Weighting Sub-Metrics for Grammatical Error Correction in the Era of Large Language Models
Dec 17, 2024Evaluating the performance of Grammatical Error Correction (GEC) models has become increasingly challenging, as large language model (LLM)-based GEC systems often produce corrections that diverge from provided gold references. This discrepancy undermines the reliability of traditional reference-based evaluation metrics. In this study, we propose a novel evaluation framework for GEC models, DSGram, integrating Semantic Coherence, Edit Level, and Fluency, and utilizing a dynamic weighting mechanism. Our framework employs the Analytic Hierarchy Process (AHP) in conjunction with large language models to ascertain the relative importance of various evaluation criteria. Additionally, we develop a dataset incorporating human annotations and LLM-simulated sentences to validate our algorithms and fine-tune more cost-effective models. Experimental results indicate that our proposed approach enhances the effectiveness of GEC model evaluations.
Evaluating Self-Generated Documents for Enhancing Retrieval-Augmented Generation with Large Language Models
Oct 17, 2024



In retrieval-augmented generation systems, the integration of self-generated documents (SGDs) alongside retrieved content has emerged as a promising strategy for enhancing the performance of large language model. However, previous research primarily focuses on optimizing the use of SGDs, with the inherent properties of SGDs remaining underexplored. Therefore, this paper conducts a comprehensive analysis of different types of SGDs and experiments on various knowledge-intensive tasks. We develop a taxonomy of SGDs grounded in Systemic Functional Linguistics (SFL) to compare the influence of different SGD categories. Our findings offer key insights into what kinds of SGDs most effectively contribute to improving LLM's performance. The results and further fusion methods based on SGD categories also provide practical guidelines for taking better advantage of SGDs to achieve significant advancements in knowledge-driven QA tasks with RAG.
COrAL: Order-Agnostic Language Modeling for Efficient Iterative Refinement
Oct 12, 2024



Iterative refinement has emerged as an effective paradigm for enhancing the capabilities of large language models (LLMs) on complex tasks. However, existing approaches typically implement iterative refinement at the application or prompting level, relying on autoregressive (AR) modeling. The sequential token generation in AR models can lead to high inference latency. To overcome these challenges, we propose Context-Wise Order-Agnostic Language Modeling (COrAL), which incorporates iterative refinement directly into the LLM architecture while maintaining computational efficiency. Our approach models multiple token dependencies within manageable context windows, enabling the model to perform iterative refinement internally during the generation process. Leveraging the order-agnostic nature of COrAL, we introduce sliding blockwise order-agnostic decoding, which performs multi-token forward prediction and backward reconstruction within context windows. This allows the model to iteratively refine its outputs in parallel in the sliding block, effectively capturing diverse dependencies without the high inference cost of sequential generation. Empirical evaluations on reasoning tasks demonstrate that COrAL improves performance and inference speed, respectively, achieving absolute accuracy gains of $4.6\%$ on GSM8K and $4.0\%$ on LogiQA, along with inference speedups of up to $3.9\times$ over next-token baselines. Preliminary results on code generation indicate a drop in pass rates due to inconsistencies in order-agnostic outputs, highlighting the inherent quality--speed trade-off. Our code is publicly available at https://github.com/YuxiXie/COrAL.