 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
Differentiable Evolutionary Reinforcement Learning
Dec 15, 2025The design of effective reward functions presents a central and often arduous challenge in reinforcement learning (RL), particularly when developing autonomous agents for complex reasoning tasks. While automated reward optimization approaches exist, they typically rely on derivative-free evolutionary heuristics that treat the reward function as a black box, failing to capture the causal relationship between reward structure and task performance. To bridge this gap, we propose Differentiable Evolutionary Reinforcement Learning (DERL), a bilevel framework that enables the autonomous discovery of optimal reward signals. In DERL, a Meta-Optimizer evolves a reward function (i.e., Meta-Reward) by composing structured atomic primitives, guiding the training of an inner-loop policy. Crucially, unlike previous evolution, DERL is differentiable in its metaoptimization: it treats the inner-loop validation performance as a signal to update the Meta-Optimizer via reinforcement learning. This allows DERL to approximate the "meta-gradient" of task success, progressively learning to generate denser and more actionable feedback. We validate DERL across three distinct domains: robotic agent (ALFWorld), scientific simulation (ScienceWorld), and mathematical reasoning (GSM8k, MATH). Experimental results show that DERL achieves state-of-the-art performance on ALFWorld and ScienceWorld, significantly outperforming methods relying on heuristic rewards, especially in out-of-distribution scenarios. Analysis of the evolutionary trajectory demonstrates that DERL successfully captures the intrinsic structure of tasks, enabling selfimproving agent alignment without human intervention.
Dynamic Evaluation for Oversensitivity in LLMs
Oct 21, 2025Oversensitivity occurs when language models defensively reject prompts that are actually benign. This behavior not only disrupts user interactions but also obscures the boundary between harmful and harmless content. Existing benchmarks rely on static datasets that degrade overtime as models evolve, leading to data contamination and diminished evaluative power. To address this, we develop a framework that dynamically generates model-specific challenging datasets, capturing emerging defensive patterns and aligning with each model's unique behavior. Building on this approach, we construct OVERBENCH, a benchmark that aggregates these datasets across diverse LLM families, encompassing 450,000 samples from 25 models. OVERBENCH provides a dynamic and evolving perspective on oversensitivity, allowing for continuous monitoring of defensive triggers as models advance, highlighting vulnerabilities that static datasets overlook.
LEDOM: An Open and Fundamental Reverse Language Model
Jul 02, 2025We introduce LEDOM, the first purely reverse language model, trained autoregressively on 435B tokens with 2B and 7B parameter variants, which processes sequences in reverse temporal order through previous token prediction. For the first time, we present the reverse language model as a potential foundational model across general tasks, accompanied by a set of intriguing examples and insights. Based on LEDOM, we further introduce a novel application: Reverse Reward, where LEDOM-guided reranking of forward language model outputs leads to substantial performance improvements on mathematical reasoning tasks. This approach leverages LEDOM's unique backward reasoning capability to refine generation quality through posterior evaluation. Our findings suggest that LEDOM exhibits unique characteristics with broad application potential. We will release all models, training code, and pre-training data to facilitate future research.
TARGA: Targeted Synthetic Data Generation for Practical Reasoning over Structured Data
Dec 27, 2024



Semantic parsing, which converts natural language questions into logic forms, plays a crucial role in reasoning within structured environments. However, existing methods encounter two significant challenges: reliance on extensive manually annotated datasets and limited generalization capability to unseen examples. To tackle these issues, we propose Targeted Synthetic Data Generation (TARGA), a practical framework that dynamically generates high-relevance synthetic data without manual annotation. Starting from the pertinent entities and relations of a given question, we probe for the potential relevant queries through layer-wise expansion and cross-layer combination. Then we generate corresponding natural language questions for these constructed queries to jointly serve as the synthetic demonstrations for in-context learning. Experiments on multiple knowledge base question answering (KBQA) datasets demonstrate that TARGA, using only a 7B-parameter model, substantially outperforms existing non-fine-tuned methods that utilize close-sourced model, achieving notable improvements in F1 scores on GrailQA(+7.7) and KBQA-Agent(+12.2). Furthermore, TARGA also exhibits superior sample efficiency, robustness, and generalization capabilities under non-I.I.D. settings.
RuleArena: A Benchmark for Rule-Guided Reasoning with LLMs in Real-World Scenarios
Dec 12, 2024



This paper introduces RuleArena, a novel and challenging benchmark designed to evaluate the ability of large language models (LLMs) to follow complex, real-world rules in reasoning. Covering three practical domains -- airline baggage fees, NBA transactions, and tax regulations -- RuleArena assesses LLMs' proficiency in handling intricate natural language instructions that demand long-context understanding, logical reasoning, and accurate mathematical computation. Two key attributes distinguish RuleArena from traditional rule-based reasoning benchmarks: (1) it extends beyond standard first-order logic representations, and (2) it is grounded in authentic, practical scenarios, providing insights into the suitability and reliability of LLMs for real-world applications. Our findings reveal several notable limitations in LLMs: (1) they struggle to identify and apply the appropriate rules, frequently becoming confused by similar but distinct regulations, (2) they cannot consistently perform accurate mathematical computations, even when they correctly identify the relevant rules, and (3) in general, they perform poorly in the benchmark. These results highlight significant challenges in advancing LLMs' rule-guided reasoning capabilities in real-life applications.
Disentangling Memory and Reasoning Ability in Large Language Models
Nov 21, 2024Large Language Models (LLMs) have demonstrated strong performance in handling complex tasks requiring both extensive knowledge and reasoning abilities. However, the existing LLM inference pipeline operates as an opaque process without explicit separation between knowledge retrieval and reasoning steps, making the model's decision-making process unclear and disorganized. This ambiguity can lead to issues such as hallucinations and knowledge forgetting, which significantly impact the reliability of LLMs in high-stakes domains. In this paper, we propose a new inference paradigm that decomposes the complex inference process into two distinct and clear actions: (1) memory recall: which retrieves relevant knowledge, and (2) reasoning: which performs logical steps based on the recalled knowledge. To facilitate this decomposition, we introduce two special tokens memory and reason, guiding the model to distinguish between steps that require knowledge retrieval and those that involve reasoning. Our experiment results show that this decomposition not only improves model performance but also enhances the interpretability of the inference process, enabling users to identify sources of error and refine model responses effectively. The code is available at https://github.com/MingyuJ666/Disentangling-Memory-and-Reasoning.
Understanding the Interplay between Parametric and Contextual Knowledge for Large Language Models
Oct 10, 2024



Large language models (LLMs) encode vast amounts of knowledge during pre-training (parametric knowledge, or PK) and can further be enhanced by incorporating contextual knowledge (CK). Can LLMs effectively integrate their internal PK with external CK to solve complex problems? In this paper, we investigate the dynamic interaction between PK and CK, categorizing their relationships into four types: Supportive, Complementary, Conflicting, and Irrelevant. To support this investigation, we introduce ECHOQA, a benchmark spanning scientific, factual, and commonsense knowledge. Our results show that LLMs tend to suppress their PK when contextual information is available, even when it is complementary or irrelevant. While tailored instructions can encourage LLMs to rely more on their PK, they still struggle to fully leverage it. These findings reveal a key vulnerability in LLMs, raising concerns about their reliability in knowledge-intensive tasks. Resources are available at https://github.com/sitaocheng/Knowledge Interplay.
EfficientRAG: Efficient Retriever for Multi-Hop Question Answering
Aug 08, 2024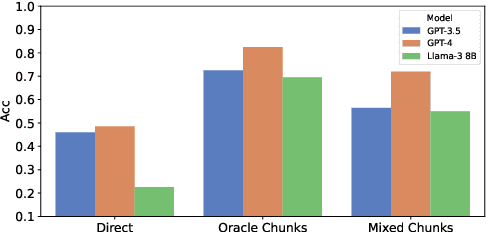
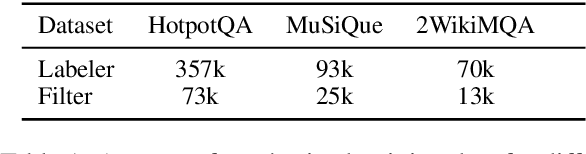
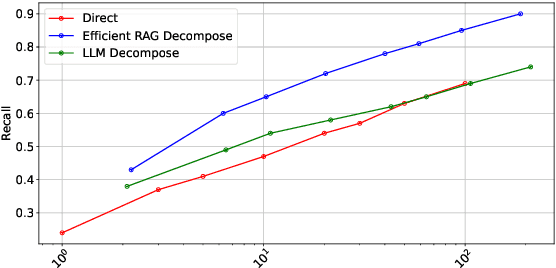
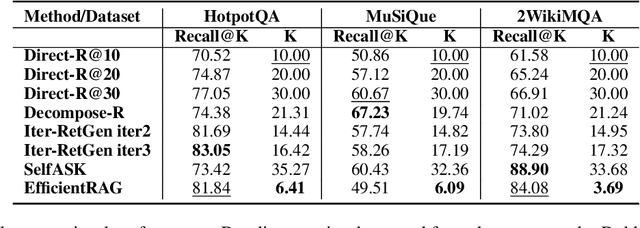
Retrieval-augmented generation (RAG) methods encounter difficulties when addressing complex questions like multi-hop queries. While iterative retrieval methods improve performance by gathering additional information, current approaches often rely on multiple calls of large language models (LLMs). In this paper, we introduce EfficientRAG, an efficient retriever for multi-hop question answering. EfficientRAG iteratively generates new queries without the need for LLM calls at each iteration and filters out irrelevant information. Experimental results demonstrate that EfficientRAG surpasses existing RAG methods on three open-domain multi-hop question-answering datasets.
Thread: A Logic-Based Data Organization Paradigm for How-To Question Answering with Retrieval Augmented Generation
Jun 19, 2024
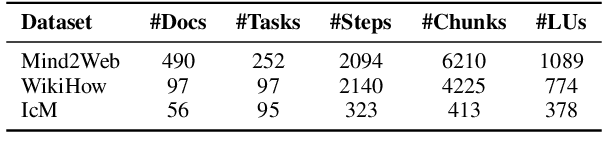
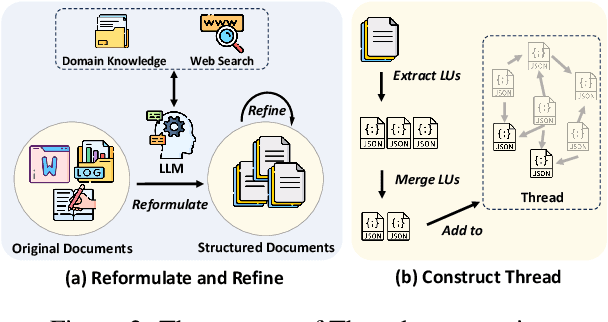
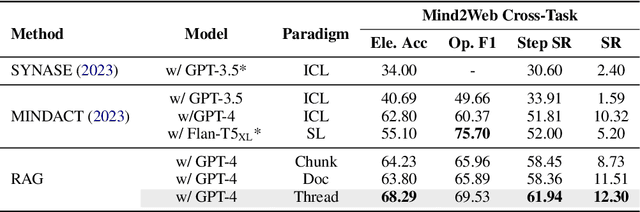
Current question answering systems leveraging retrieval augmented generation perform well in answering factoid questions but face challenges with non-factoid questions, particularly how-to queries requiring detailed step-by-step instructions and explanations. In this paper, we introduce Thread, a novel data organization paradigm that transforms documents into logic units based on their inter-connectivity. Extensive experiments across open-domain and industrial scenarios demonstrate that Thread outperforms existing data organization paradigms in RAG-based QA systems, significantly improving the handling of how-to questions.