 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
PromptDistill: Query-based Selective Token Retention in Intermediate Layers for Efficient Large Language Model Inference
Mar 30, 2025
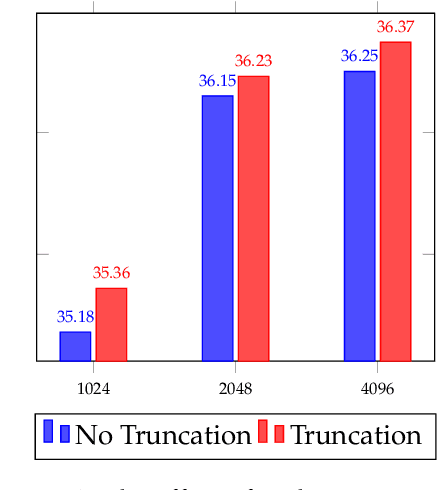
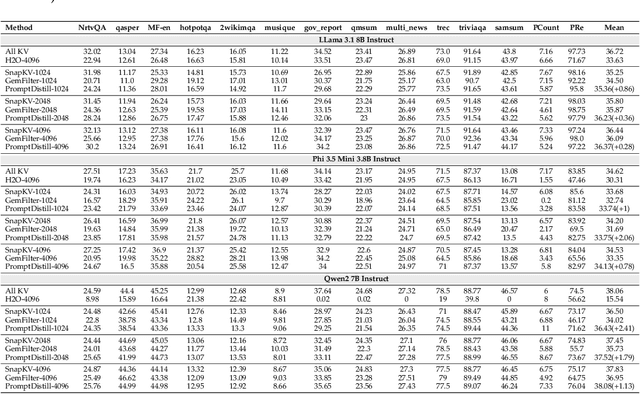
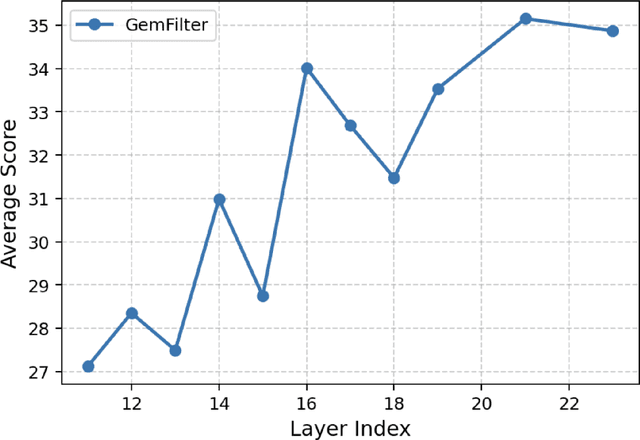
As large language models (LLMs) tackle increasingly complex tasks and longer documents, their computational and memory costs during inference become a major bottleneck. To address this, we propose PromptDistill, a novel, training-free method that improves inference efficiency while preserving generation quality. PromptDistill identifies and retains the most informative tokens by leveraging attention interactions in early layers, preserving their hidden states while reducing the computational burden in later layers. This allows the model to focus on essential contextual information without fully processing all tokens. Unlike previous methods such as H2O and SnapKV, which perform compression only after processing the entire input, or GemFilter, which selects a fixed portion of the initial prompt without considering contextual dependencies, PromptDistill dynamically allocates computational resources to the most relevant tokens while maintaining a global awareness of the input. Experiments using our method and baseline approaches with base models such as LLaMA 3.1 8B Instruct, Phi 3.5 Mini Instruct, and Qwen2 7B Instruct on benchmarks including LongBench, InfBench, and Needle in a Haystack demonstrate that PromptDistill significantly improves efficiency while having minimal impact on output quality compared to the original models. With a single-stage selection strategy, PromptDistill effectively balances performance and efficiency, outperforming prior methods like GemFilter, H2O, and SnapKV due to its superior ability to retain essential information. Specifically, compared to GemFilter, PromptDistill achieves an overall $1\%$ to $5\%$ performance improvement while also offering better time efficiency. Additionally, we explore multi-stage selection, which further improves efficiency while maintaining strong generation performance.
M-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework
Nov 09, 2024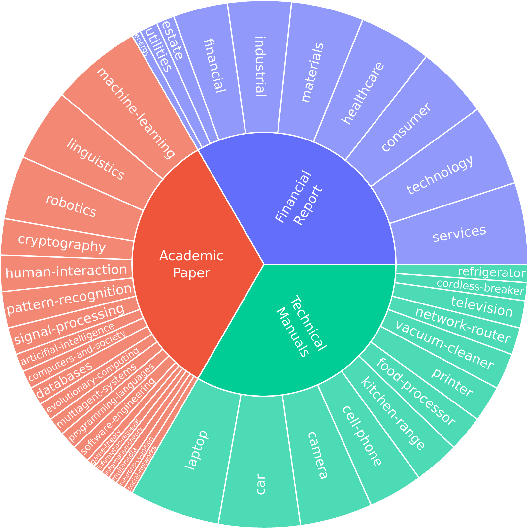
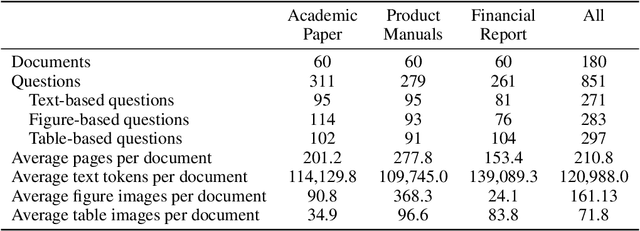
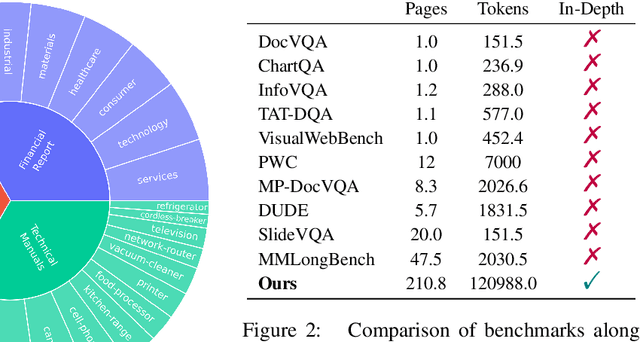
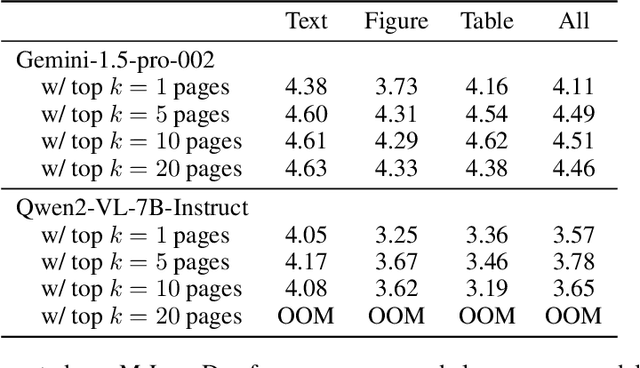
The ability to understand and answer questions over documents can be useful in many business and practical applications. However, documents often contain lengthy and diverse multimodal contents such as texts, figures, and tables, which are very time-consuming for humans to read thoroughly. Hence, there is an urgent need to develop effective and automated methods to aid humans in this task. In this work, we introduce M-LongDoc, a benchmark of 851 samples, and an automated framework to evaluate the performance of large multimodal models. We further propose a retrieval-aware tuning approach for efficient and effective multimodal document reading. Compared to existing works, our benchmark consists of more recent and lengthy documents with hundreds of pages, while also requiring open-ended solutions and not just extractive answers. To our knowledge, our training framework is the first to directly address the retrieval setting for multimodal long documents. To enable tuning open-source models, we construct a training corpus in a fully automatic manner for the question-answering task over such documents. Experiments show that our tuning approach achieves a relative improvement of 4.6% for the correctness of model responses, compared to the baseline open-source models. Our data, code, and models are available at https://multimodal-documents.github.io.
Measuring and Enhancing Trustworthiness of LLMs in RAG through Grounded Attributions and Learning to Refuse
Sep 17, 2024



LLMs are an integral part of retrieval-augmented generation (RAG) systems. While many studies focus on evaluating the quality of end-to-end RAG systems, there is a lack of research on understanding the appropriateness of an LLM for the RAG task. Thus, we introduce a new metric, Trust-Score, that provides a holistic evaluation of the trustworthiness of LLMs in an RAG framework. We show that various prompting methods, such as in-context learning, fail to adapt LLMs effectively to the RAG task. Thus, we propose Trust-Align, a framework to align LLMs for higher Trust-Score. LLaMA-3-8b, aligned with our method, significantly outperforms open-source LLMs of comparable sizes on ASQA (up 10.7), QAMPARI (up 29.2) and ELI5 (up 14.9). We release our code at: https://github.com/declare-lab/trust-align.