 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework
Nov 09, 2024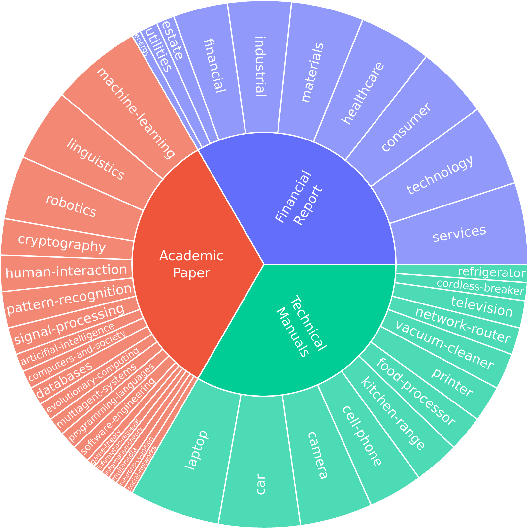
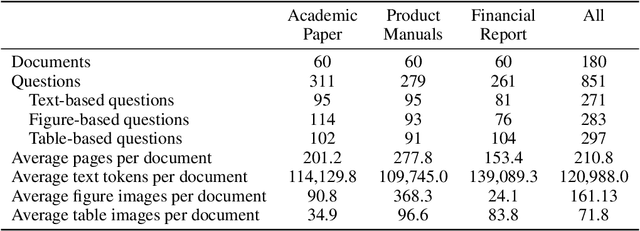
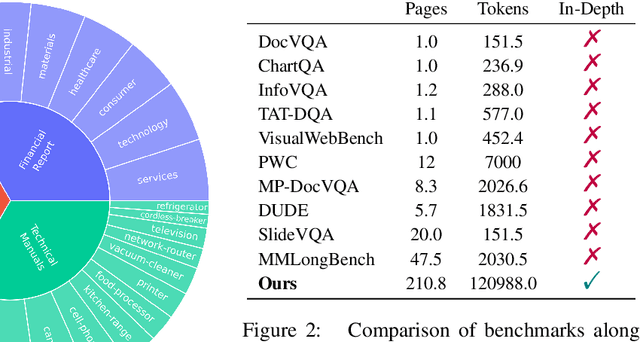
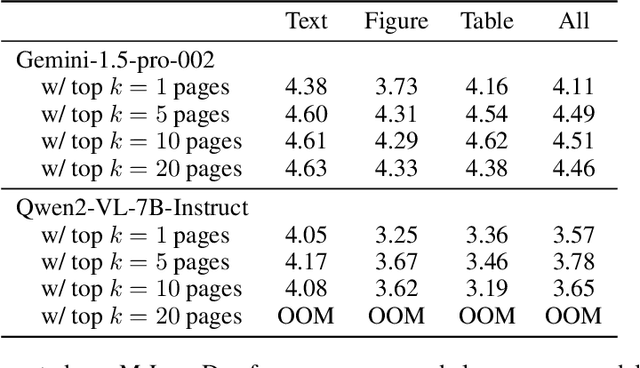
The ability to understand and answer questions over documents can be useful in many business and practical applications. However, documents often contain lengthy and diverse multimodal contents such as texts, figures, and tables, which are very time-consuming for humans to read thoroughly. Hence, there is an urgent need to develop effective and automated methods to aid humans in this task. In this work, we introduce M-LongDoc, a benchmark of 851 samples, and an automated framework to evaluate the performance of large multimodal models. We further propose a retrieval-aware tuning approach for efficient and effective multimodal document reading. Compared to existing works, our benchmark consists of more recent and lengthy documents with hundreds of pages, while also requiring open-ended solutions and not just extractive answers. To our knowledge, our training framework is the first to directly address the retrieval setting for multimodal long documents. To enable tuning open-source models, we construct a training corpus in a fully automatic manner for the question-answering task over such documents. Experiments show that our tuning approach achieves a relative improvement of 4.6% for the correctness of model responses, compared to the baseline open-source models. Our data, code, and models are available at https://multimodal-documents.github.io.
Democratizing LLMs for Low-Resource Languages by Leveraging their English Dominant Abilities with Linguistically-Diverse Prompts
Jun 20, 2023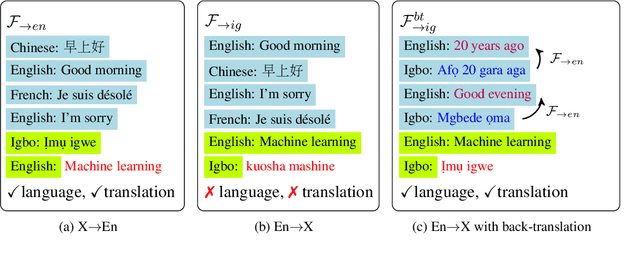
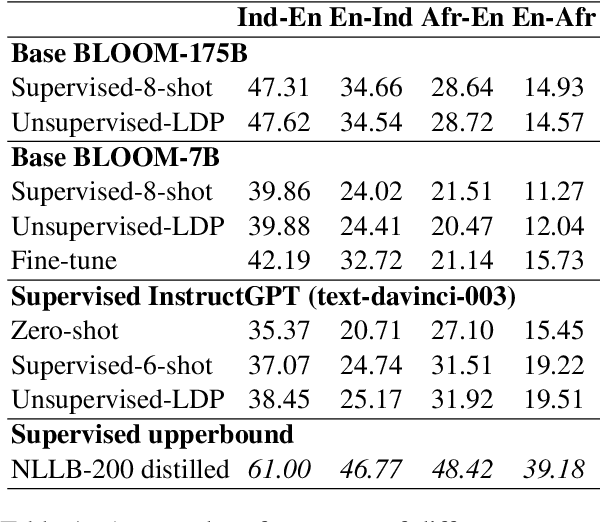

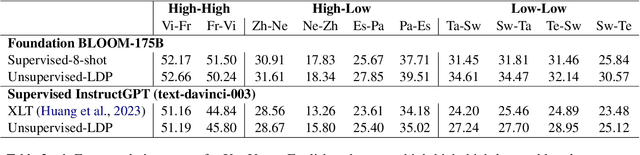
Large language models (LLMs) are known to effectively perform tasks by simply observing few exemplars. However, in low-resource languages, obtaining such hand-picked exemplars can still be challenging, where unsupervised techniques may be necessary. Moreover, competent generative capabilities of LLMs are observed only in high-resource languages, while their performances among under-represented languages fall behind due to pre-training data imbalance. To elicit LLMs' ability onto low-resource languages without any supervised data, we propose to assemble synthetic exemplars from a diverse set of high-resource languages to prompt the LLMs to translate from any language into English. These prompts are then used to create intra-lingual exemplars to perform tasks in the target languages. Our unsupervised prompting method performs on par with supervised few-shot learning in LLMs of different sizes for translations between English and 13 Indic and 21 African low-resource languages. We also show that fine-tuning a 7B model on data generated from our method helps it perform competitively with a 175B model. In non-English translation tasks, our method even outperforms supervised prompting by up to 3 chrF++ in many low-resource languages. When evaluated on zero-shot multilingual summarization, our method surpasses other English-pivoting baselines by up to 4 ROUGE-L and is also favored by GPT-4.
M3Exam: A Multilingual, Multimodal, Multilevel Benchmark for Examining Large Language Models
Jun 08, 2023



Despite the existence of various benchmarks for evaluating natural language processing models, we argue that human exams are a more suitable means of evaluating general intelligence for large language models (LLMs), as they inherently demand a much wider range of abilities such as language understanding, domain knowledge, and problem-solving skills. To this end, we introduce M3Exam, a novel benchmark sourced from real and official human exam questions for evaluating LLMs in a multilingual, multimodal, and multilevel context. M3Exam exhibits three unique characteristics: (1) multilingualism, encompassing questions from multiple countries that require strong multilingual proficiency and cultural knowledge; (2) multimodality, accounting for the multimodal nature of many exam questions to test the model's multimodal understanding capability; and (3) multilevel structure, featuring exams from three critical educational periods to comprehensively assess a model's proficiency at different levels. In total, M3Exam contains 12,317 questions in 9 diverse languages with three educational levels, where about 23\% of the questions require processing images for successful solving. We assess the performance of top-performing LLMs on M3Exam and find that current models, including GPT-4, still struggle with multilingual text, particularly in low-resource and non-Latin script languages. Multimodal LLMs also perform poorly with complex multimodal questions. We believe that M3Exam can be a valuable resource for comprehensively evaluating LLMs by examining their multilingual and multimodal abilities and tracking their development. Data and evaluation code is available at \url{https://github.com/DAMO-NLP-SG/M3Exam}.
Domain-Expanded ASTE: Rethinking Generalization in Aspect Sentiment Triplet Extraction
May 23, 2023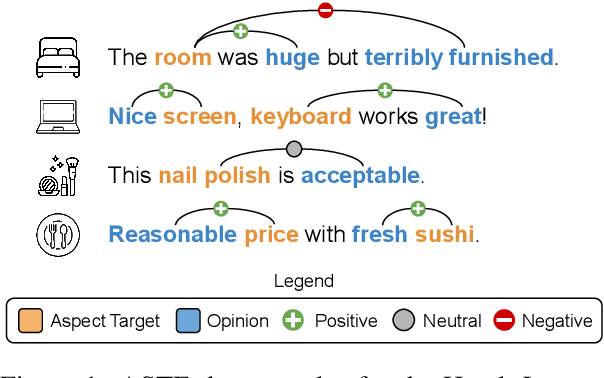
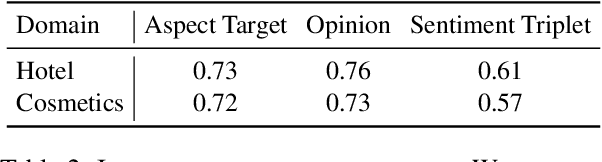
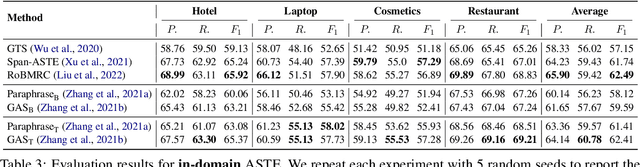
Aspect Sentiment Triplet Extraction (ASTE) is a subtask of Aspect-Based Sentiment Analysis (ABSA) that considers each opinion term, their expressed sentiment, and the corresponding aspect targets. However, existing methods are limited to the in-domain setting with two domains. Hence, we propose a domain-expanded benchmark to address the in-domain, out-of-domain and cross-domain settings. We support the new benchmark by annotating more than 4000 data samples for two new domains based on hotel and cosmetics reviews. Our analysis of five existing methods shows that while there is a significant gap between in-domain and out-of-domain performance, generative methods have a strong potential for domain generalization. Our datasets, code implementation and models are available at https://github.com/DAMO-NLP-SG/domain-expanded-aste .
A Dataset for Hyper-Relational Extraction and a Cube-Filling Approach
Nov 18, 2022Relation extraction has the potential for large-scale knowledge graph construction, but current methods do not consider the qualifier attributes for each relation triplet, such as time, quantity or location. The qualifiers form hyper-relational facts which better capture the rich and complex knowledge graph structure. For example, the relation triplet (Leonard Parker, Educated At, Harvard University) can be factually enriched by including the qualifier (End Time, 1967). Hence, we propose the task of hyper-relational extraction to extract more specific and complete facts from text. To support the task, we construct HyperRED, a large-scale and general-purpose dataset. Existing models cannot perform hyper-relational extraction as it requires a model to consider the interaction between three entities. Hence, we propose CubeRE, a cube-filling model inspired by table-filling approaches and explicitly considers the interaction between relation triplets and qualifiers. To improve model scalability and reduce negative class imbalance, we further propose a cube-pruning method. Our experiments show that CubeRE outperforms strong baselines and reveal possible directions for future research. Our code and data are available at github.com/declare-lab/HyperRED.
GlobalWoZ: Globalizing MultiWoZ to Develop Multilingual Task-Oriented Dialogue Systems
Oct 14, 2021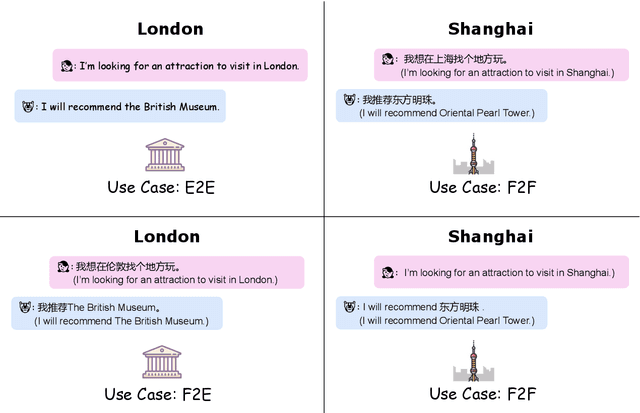
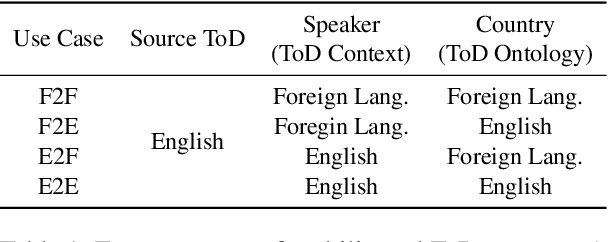
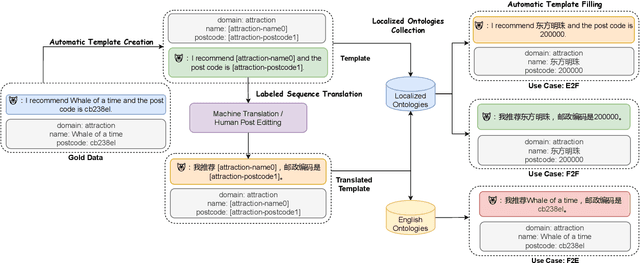
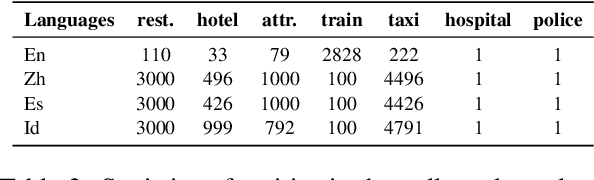
Much recent progress in task-oriented dialogue (ToD) systems has been driven by available annotation data across multiple domains for training. Over the last few years, there has been a move towards data curation for multilingual ToD systems that are applicable to serve people speaking different languages. However, existing multilingual ToD datasets either have a limited coverage of languages due to the high cost of data curation, or ignore the fact that dialogue entities barely exist in countries speaking these languages. To tackle these limitations, we introduce a novel data curation method that generates GlobalWoZ -- a large-scale multilingual ToD dataset globalized from an English ToD dataset for three unexplored use cases. Our method is based on translating dialogue templates and filling them with local entities in the target-language countries. We release our dataset as well as a set of strong baselines to encourage research on learning multilingual ToD systems for real use cases.