 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalWoZ: Globalizing MultiWoZ to Develop Multilingual Task-Oriented Dialogue Systems
Paper and Code
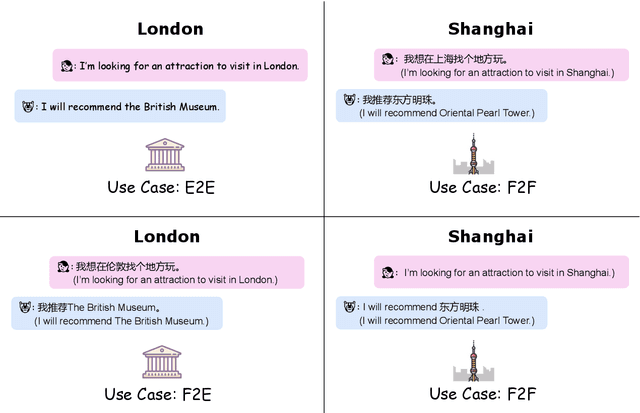
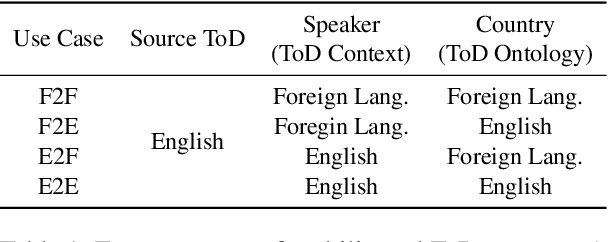
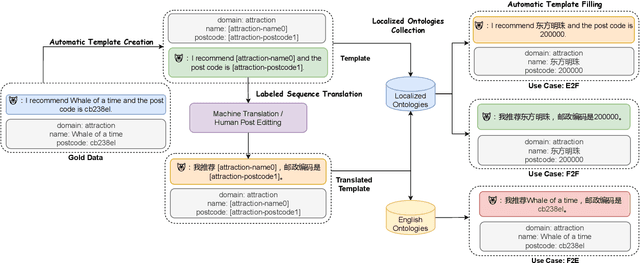
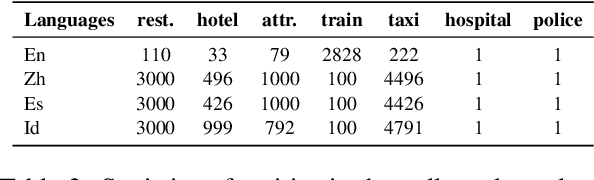
Much recent progress in task-oriented dialogue (ToD) systems has been driven by available annotation data across multiple domains for training. Over the last few years, there has been a move towards data curation for multilingual ToD systems that are applicable to serve people speaking different languages. However, existing multilingual ToD datasets either have a limited coverage of languages due to the high cost of data curation, or ignore the fact that dialogue entities barely exist in countries speaking these languages. To tackle these limitations, we introduce a novel data curation method that generates GlobalWoZ -- a large-scale multilingual ToD dataset globalized from an English ToD dataset for three unexplored use cases. Our method is based on translating dialogue templates and filling them with local entities in the target-language countries. We release our dataset as well as a set of strong baselines to encourage research on learning multilingual ToD systems for real use cases.