 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Super Agent System with Hybrid AI Routers
Apr 11, 2025AI Agents powered by Large Language Models are transforming the world through enormous applications. A super agent has the potential to fulfill diverse user needs, such as summarization, coding, and research, by accurately understanding user intent and leveraging the appropriate tools to solve tasks. However, to make such an agent viable for real-world deployment and accessible at scale, significant optimizations are required to ensure high efficiency and low cost. This paper presents a design of the Super Agent System. Upon receiving a user prompt, the system first detects the intent of the user, then routes the request to specialized task agents with the necessary tools or automatically generates agentic workflows. In practice, most applications directly serve as AI assistants on edge devices such as phones and robots. As different language models vary in capability and cloud-based models often entail high computational costs, latency, and privacy concerns, we then explore the hybrid mode where the router dynamically selects between local and cloud models based on task complexity. Finally, we introduce the blueprint of an on-device super agent enhanced with cloud. With advances in multi-modality models and edge hardware, we envision that most computations can be handled locally, with cloud collaboration only as needed. Such architecture paves the way for super agents to be seamlessly integrated into everyday life in the near future.
StructTest: Benchmarking LLMs' Reasoning through Compositional Structured Outputs
Dec 23, 2024



The rapid development of large language models (LLMs) necessitates robust, unbiased, and scalable methods for evaluating their capabilities. However, human annotations are expensive to scale, model-based evaluations are prone to biases in answer style, while target-answer-based benchmarks are vulnerable to data contamination and cheating. To address these limitations, we propose StructTest, a novel benchmark that evaluates LLMs on their ability to produce compositionally specified structured outputs as an unbiased, cheap-to-run and difficult-to-cheat measure. The evaluation is done deterministically by a rule-based evaluator, which can be easily extended to new tasks. By testing structured outputs across diverse task domains -- including Summarization, Code, HTML and Math -- we demonstrate that StructTest serves as a good proxy for general reasoning abilities, as producing structured outputs often requires internal logical reasoning. We believe that StructTest offers a critical, complementary approach to objective and robust model evaluation.
Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
Apr 19, 2024
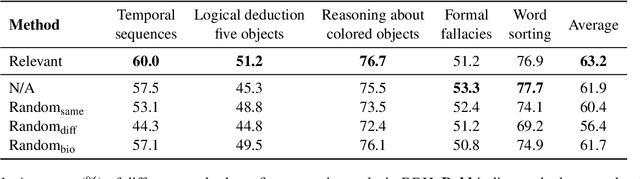
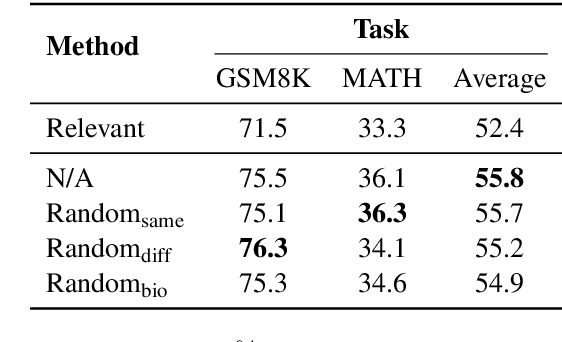
Analogical reasoning is a unique ability of humans to address unfamiliar challenges by transferring strategies from relevant past experiences. One key finding in psychology is that compared with irrelevant past experiences, recalling relevant ones can help humans better handle new tasks. Coincidentally, the NLP community has also recently found that self-generating relevant examples in the context can help large language models (LLMs) better solve a given problem than hand-crafted prompts. However, it is yet not clear whether relevance is the key factor eliciting such capability, i.e., can LLMs benefit more from self-generated relevant examples than irrelevant ones? In this work, we systematically explore whether LLMs can truly perform analogical reasoning on a diverse set of reasoning tasks. With extensive experiments and analysis, we show that self-generated random examples can surprisingly achieve comparable or even better performance, e.g., 4% performance boost on GSM8K with random biological examples. We find that the accuracy of self-generated examples is the key factor and subsequently design two improved methods with significantly reduced inference costs. Overall, we aim to advance a deeper understanding of LLM analogical reasoning and hope this work stimulates further research in the design of self-generated contexts.
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mar 31, 2024With the rise of Large Language Models (LLMs) in recent years, new opportunities are emerging, but also new challenges, and contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a critical issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently address contamination, or a clear consensus on prevention, mitigation and classification of contamination. In this paper, we survey all recent work on contamination with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms, which link is: https://github.com/ntunlp/LLMSanitize.
Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges
Mar 05, 2024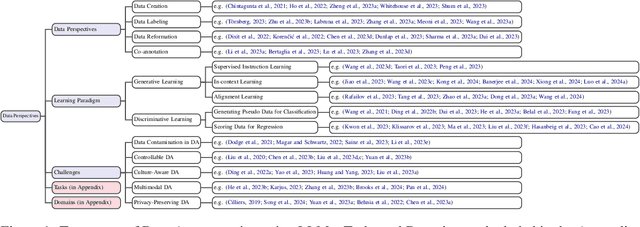
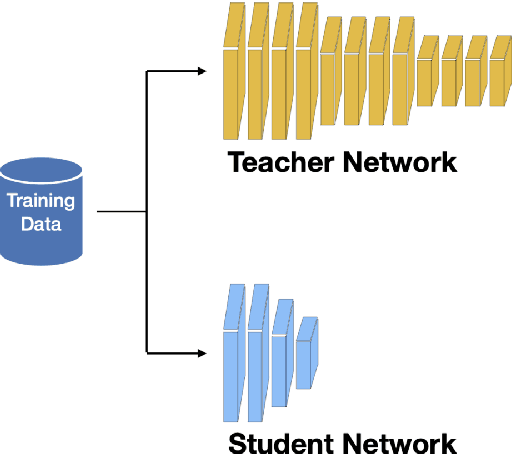
In the rapidly evolving field of machine learning (ML), data augmentation (DA) has emerged as a pivotal technique for enhancing model performance by diversifying training examples without the need for additional data collection. This survey explores the transformative impact of Large Language Models (LLMs) on DA, particularly addressing the unique challenges and opportunities they present in the context of natural language processing (NLP) and beyond. From a data perspective and a learning perspective, we examine various strategies that utilize Large Language Models for data augmentation, including a novel exploration of learning paradigms where LLM-generated data is used for further training. Additionally, this paper delineates the primary challenges faced in this domain, ranging from controllable data augmentation to multi modal data augmentation. This survey highlights the paradigm shift introduced by LLMs in DA, aims to serve as a foundational guide for researchers and practitioners in this field.
LogicLLM: Exploring Self-supervised Logic-enhanced Training for Large Language Models
May 24, 2023



Existing efforts to improve logical reasoning ability of language models have predominantly relied on supervised fine-tuning, hindering generalization to new domains and/or tasks. The development of Large Langauge Models (LLMs) has demonstrated the capacity of compressing abundant knowledge into a single proxy, enabling them to tackle multiple tasks effectively. Our preliminary experiments, nevertheless, show that LLMs do not show capability on logical reasoning. The performance of LLMs on logical reasoning benchmarks is far behind the existing state-of-the-art baselines. In this paper, we make the first attempt to investigate the feasibility of incorporating logical knowledge through self-supervised post-training, and activating it via in-context learning, which we termed as LogicLLM. Specifically, we devise an auto-regressive objective variant of MERIt and integrate it with two LLM series, i.e., FLAN-T5 and LLaMA, with parameter size ranging from 3 billion to 13 billion. The results on two challenging logical reasoning benchmarks demonstrate the effectiveness of LogicLLM. Besides, we conduct extensive ablation studies to analyze the key factors in designing logic-oriented proxy tasks.
Chain of Knowledge: A Framework for Grounding Large Language Models with Structured Knowledge Bases
May 22, 2023We introduce Chain of Knowledge (CoK), a framework that augments large language models with structured knowledge bases to improve factual correctness and reduce hallucination. Compared to previous works which only retrieve unstructured texts, CoK leverages structured knowledge bases which support complex queries and offer more direct factual statements. To assist large language models to effectively query knowledge bases, we propose a query generator model with contrastive instruction-tuning. As the query generator is separate from the frozen large language model, our framework is modular and thus easily adapted to various knowledge sources and models. Experiments show that our framework significantly enhances the factual correctness of large language models on knowledge-intensive tasks.
Panda LLM: Training Data and Evaluation for Open-Sourced Chinese Instruction-Following Large Language Models
May 04, 2023



This project focuses on enhancing open-source large language models through instruction-tuning and providing comprehensive evaluations of their performance. We explore how various training data factors, such as quantity, quality, and linguistic distribution, influence the performance of instruction-tuned models trained on publicly accessible high-quality instruction datasets for both English and Chinese languages. Our goal is to supplement evaluation with quantitative analyses, providing valuable insights for the continued advancement of open-source chat models. Our model, data, and code are publicly available for others to use and build upon.
Retrieving Multimodal Information for Augmented Generation: A Survey
Mar 20, 2023

In this survey, we review methods that retrieve multimodal knowledge to assist and augment generative models. This group of works focuses on retrieving grounding contexts from external sources, including images, codes, tables, graphs, and audio. As multimodal learning and generative AI have become more and more impactful, such retrieval augmentation offers a promising solution to important concerns such as factuality, reasoning, interpretability, and robustness. We provide an in-depth review of retrieval-augmented generation in different modalities and discuss potential future directions. As this is an emerging field, we continue to add new papers and methods.
Is GPT-3 a Good Data Annotator?
Dec 20, 2022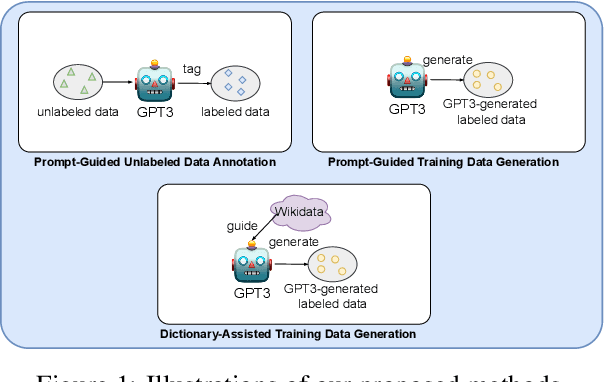
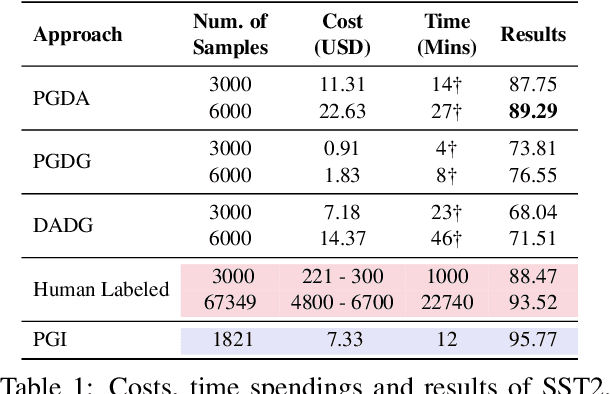

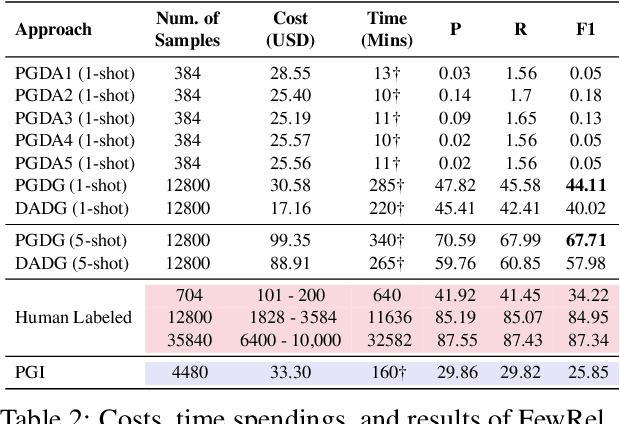
GPT-3 (Generative Pre-trained Transformer 3) is a large-scale autoregressive language model developed by OpenAI, which has demonstrated impressive few-shot performance on a wide range of natural language processing (NLP) tasks. Hence, an intuitive application is to use it for data annotation. In this paper, we investigate whether GPT-3 can be used as a good data annotator for NLP tasks. Data annotation is the process of labeling data that could be used to train machine learning models. It is a crucial step in the development of NLP systems, as it allows the model to learn the relationship between the input data and the desired output. Given the impressive language capabilities of GPT-3, it is natural to wonder whether it can be used to effectively annotate data for NLP tasks. In this paper, we evaluate the performance of GPT-3 as a data annotator by comparing it with traditional data annotation methods and analyzing its output on a range of tasks. Through this analysis, we aim to provide insight into the potential of GPT-3 as a general-purpose data annotator in NLP.