 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoFlow: Solution Flow Models for One-Step Generative Modeling
Dec 17, 2025
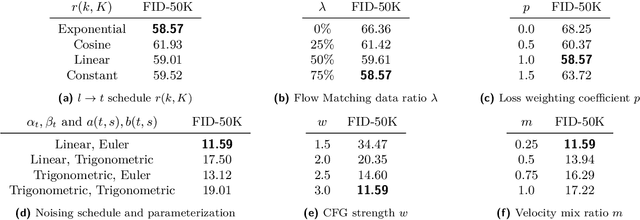
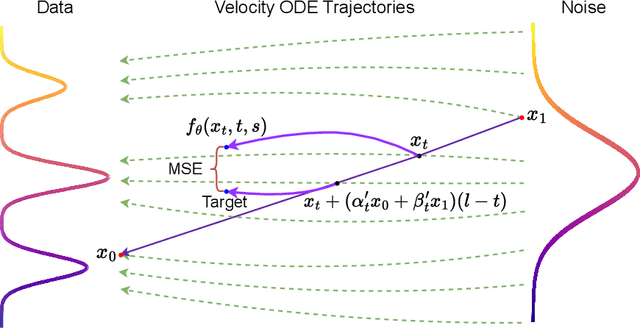
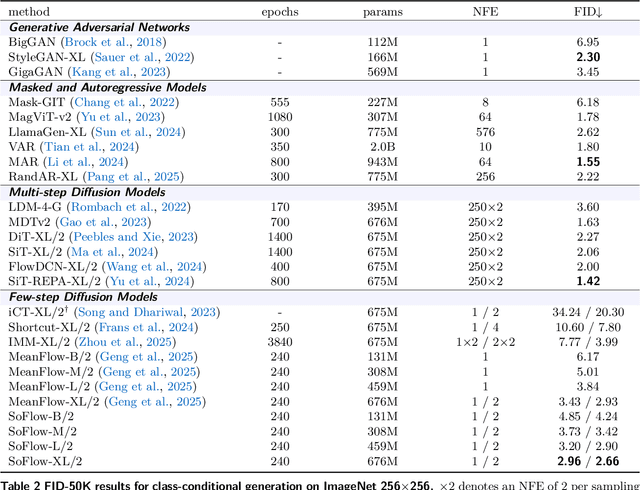
The multi-step denoising process in diffusion and Flow Matching models causes major efficiency issues, which motivates research on few-step generation. We present Solution Flow Models (SoFlow), a framework for one-step generation from scratch. By analyzing the relationship between the velocity function and the solution function of the velocity ordinary differential equation (ODE), we propose a Flow Matching loss and a solution consistency loss to train our models. The Flow Matching loss allows our models to provide estimated velocity fields for Classifier-Free Guidance (CFG) during training, which improves generation performance. Notably, our consistency loss does not require the calculation of the Jacobian-vector product (JVP), a common requirement in recent works that is not well-optimized in deep learning frameworks like PyTorch. Experimental results indicate that, when trained from scratch using the same Diffusion Transformer (DiT) architecture and an equal number of training epochs, our models achieve better FID-50K scores than MeanFlow models on the ImageNet 256x256 dataset.
Datasets and Recipes for Video Temporal Grounding via Reinforcement Learning
Jul 24, 2025Video Temporal Grounding (VTG) aims to localize relevant temporal segments in videos given natural language queries. Despite recent progress with large vision-language models (LVLMs) and instruction-tuning, existing approaches often suffer from limited temporal awareness and poor generalization. In this work, we introduce a two-stage training framework that integrates supervised fine-tuning with reinforcement learning (RL) to improve both the accuracy and robustness of VTG models. Our approach first leverages high-quality curated cold start data for SFT initialization, followed by difficulty-controlled RL to further enhance temporal localization and reasoning abilities. Comprehensive experiments on multiple VTG benchmarks demonstrate that our method consistently outperforms existing models, particularly in challenging and open-domain scenarios. We conduct an in-depth analysis of training strategies and dataset curation, highlighting the importance of both high-quality cold start data and difficulty-controlled RL. To facilitate further research and industrial adoption, we release all intermediate datasets, models, and code to the community.
WaveFM: A High-Fidelity and Efficient Vocoder Based on Flow Matching
Mar 20, 2025
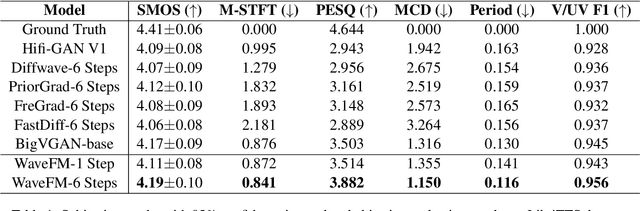
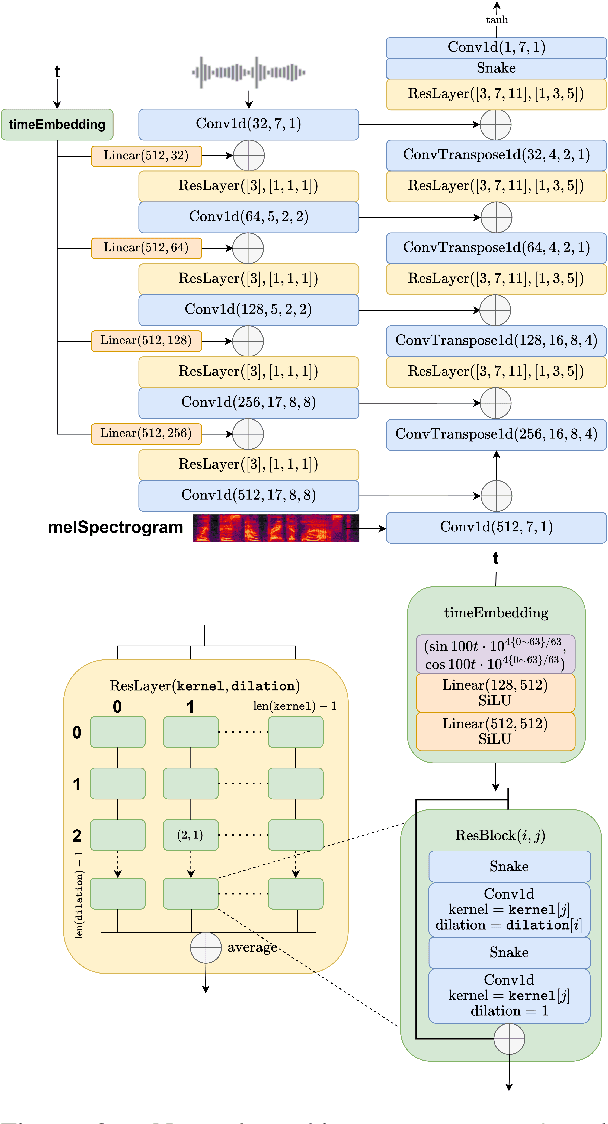
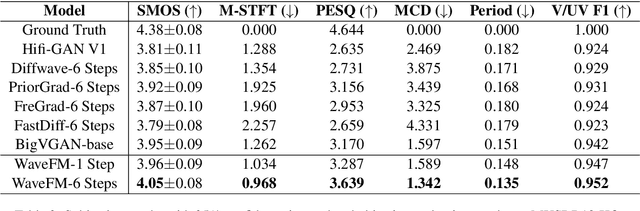
Flow matching offers a robust and stable approach to training diffusion models. However, directly applying flow matching to neural vocoders can result in subpar audio quality. In this work, we present WaveFM, a reparameterized flow matching model for mel-spectrogram conditioned speech synthesis, designed to enhance both sample quality and generation speed for diffusion vocoders. Since mel-spectrograms represent the energy distribution of waveforms, WaveFM adopts a mel-conditioned prior distribution instead of a standard Gaussian prior to minimize unnecessary transportation costs during synthesis. Moreover, while most diffusion vocoders rely on a single loss function, we argue that incorporating auxiliary losses, including a refined multi-resolution STFT loss, can further improve audio quality. To speed up inference without degrading sample quality significantly, we introduce a tailored consistency distillation method for WaveFM. Experiment results demonstrate that our model achieves superior performance in both quality and efficiency compared to previous diffusion vocoders, while enabling waveform generation in a single inference step.
Decoding Human Attentive States from Spatial-temporal EEG Patches Using Transformers
Feb 06, 2025Learning the spatial topology of electroencephalogram (EEG) channels and their temporal dynamics is crucial for decoding attention states. This paper introduces EEG-PatchFormer, a transformer-based deep learning framework designed specifically for EEG attention classification in Brain-Computer Interface (BCI) applications. By integrating a Temporal CNN for frequency-based EEG feature extraction, a pointwise CNN for feature enhancement, and Spatial and Temporal Patching modules for organizing features into spatial-temporal patches, EEG-PatchFormer jointly learns spatial-temporal information from EEG data. Leveraging the global learning capabilities of the self-attention mechanism, it captures essential features across brain regions over time, thereby enhancing EEG data decoding performance. Demonstrating superior performance, EEG-PatchFormer surpasses existing benchmarks in accuracy, area under the ROC curve (AUC), and macro-F1 score on a public cognitive attention dataset. The code can be found via: https://github.com/yi-ding-cs/EEG-PatchFormer .
HLV-1K: A Large-scale Hour-Long Video Benchmark for Time-Specific Long Video Understanding
Jan 03, 2025



Multimodal large language models have become a popular topic in deep visual understanding due to many promising real-world applications. However, hour-long video understanding, spanning over one hour and containing tens of thousands of visual frames, remains under-explored because of 1) challenging long-term video analyses, 2) inefficient large-model approaches, and 3) lack of large-scale benchmark datasets. Among them, in this paper, we focus on building a large-scale hour-long long video benchmark, HLV-1K, designed to evaluate long video understanding models. HLV-1K comprises 1009 hour-long videos with 14,847 high-quality question answering (QA) and multi-choice question asnwering (MCQA) pairs with time-aware query and diverse annotations, covering frame-level, within-event-level, cross-event-level, and long-term reasoning tasks. We evaluate our benchmark using existing state-of-the-art methods and demonstrate its value for testing deep long video understanding capabilities at different levels and for various tasks. This includes promoting future long video understanding tasks at a granular level, such as deep understanding of long live videos, meeting recordings, and movies.
From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding
Sep 27, 2024



The integration of Large Language Models (LLMs) with visual encoders has recently shown promising performance in visual understanding tasks, leveraging their inherent capability to comprehend and generate human-like text for visual reasoning. Given the diverse nature of visual data, MultiModal Large Language Models (MM-LLMs) exhibit variations in model designing and training for understanding images, short videos, and long videos. Our paper focuses on the substantial differences and unique challenges posed by long video understanding compared to static image and short video understanding. Unlike static images, short videos encompass sequential frames with both spatial and within-event temporal information, while long videos consist of multiple events with between-event and long-term temporal information. In this survey, we aim to trace and summarize the advancements of MM-LLMs from image understanding to long video understanding. We review the differences among various visual understanding tasks and highlight the challenges in long video understanding, including more fine-grained spatiotemporal details, dynamic events, and long-term dependencies. We then provide a detailed summary of the advancements in MM-LLMs in terms of model design and training methodologies for understanding long videos. Finally, we compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for MM-LLMs in long video understanding.
Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges
Mar 05, 2024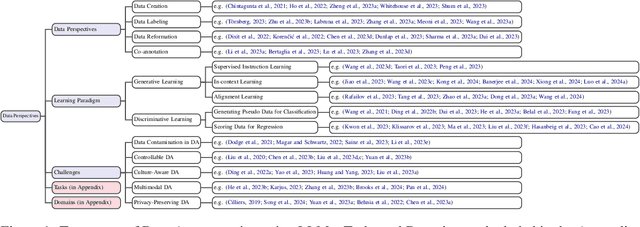
In the rapidly evolving field of machine learning (ML), data augmentation (DA) has emerged as a pivotal technique for enhancing model performance by diversifying training examples without the need for additional data collection. This survey explores the transformative impact of Large Language Models (LLMs) on DA, particularly addressing the unique challenges and opportunities they present in the context of natural language processing (NLP) and beyond. From a data perspective and a learning perspective, we examine various strategies that utilize Large Language Models for data augmentation, including a novel exploration of learning paradigms where LLM-generated data is used for further training. Additionally, this paper delineates the primary challenges faced in this domain, ranging from controllable data augmentation to multi modal data augmentation. This survey highlights the paradigm shift introduced by LLMs in DA, aims to serve as a foundational guide for researchers and practitioners in this field.
Panda LLM: Training Data and Evaluation for Open-Sourced Chinese Instruction-Following Large Language Models
May 04, 2023



This project focuses on enhancing open-source large language models through instruction-tuning and providing comprehensive evaluations of their performance. We explore how various training data factors, such as quantity, quality, and linguistic distribution, influence the performance of instruction-tuned models trained on publicly accessible high-quality instruction datasets for both English and Chinese languages. Our goal is to supplement evaluation with quantitative analyses, providing valuable insights for the continued advancement of open-source chat models. Our model, data, and code are publicly available for others to use and build upon.
Fast Graph Generation via Spectral Diffusion
Nov 19, 2022



Generating graph-structured data is a challenging problem, which requires learning the underlying distribution of graphs. Various models such as graph VAE, graph GANs, and graph diffusion models have been proposed to generate meaningful and reliable graphs, among which the diffusion models have achieved state-of-the-art performance. In this paper, we argue that running full-rank diffusion SDEs on the whole graph adjacency matrix space hinders diffusion models from learning graph topology generation, and hence significantly deteriorates the quality of generated graph data. To address this limitation, we propose an efficient yet effective Graph Spectral Diffusion Model (GSDM), which is driven by low-rank diffusion SDEs on the graph spectrum space. Our spectral diffusion model is further proven to enjoy a substantially stronger theoretical guarantee than standard diffusion models. Extensive experiments across various datasets demonstrate that, our proposed GSDM turns out to be the SOTA model, by exhibiting both significantly higher generation quality and much less computational consumption than the baselines.
Domain Confused Contrastive Learning for Unsupervised Domain Adaptation
Jul 10, 2022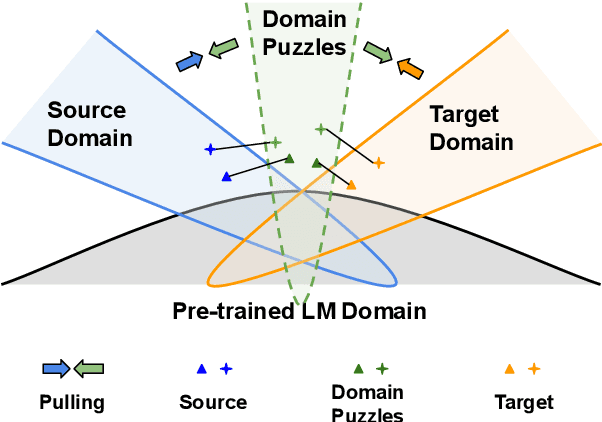

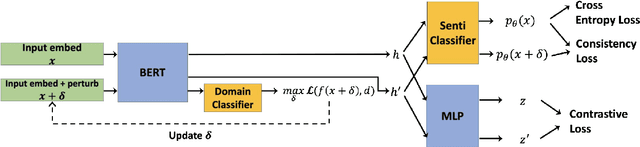
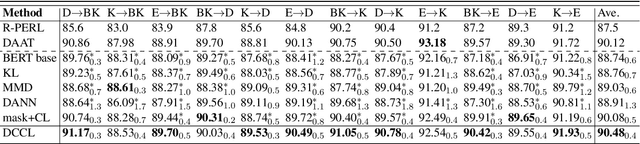
In this work, we study Unsupervised Domain Adaptation (UDA) in a challenging self-supervised approach. One of the difficulties is how to learn task discrimination in the absence of target labels. Unlike previous literature which directly aligns cross-domain distributions or leverages reverse gradient, we propose Domain Confused Contrastive Learning (DCCL) to bridge the source and the target domains via domain puzzles, and retain discriminative representations after adaptation. Technically, DCCL searches for a most domain-challenging direction and exquisitely crafts domain confused augmentations as positive pairs, then it contrastively encourages the model to pull representations towards the other domain, thus learning more stable and effective domain invariances. We also investigate whether contrastive learning necessarily helps with UDA when performing other data augmentations. Extensive experiments demonstrate that DCCL significantly outperforms baselines.