 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Human Attentive States from Spatial-temporal EEG Patches Using Transformers
Feb 06, 2025Learning the spatial topology of electroencephalogram (EEG) channels and their temporal dynamics is crucial for decoding attention states. This paper introduces EEG-PatchFormer, a transformer-based deep learning framework designed specifically for EEG attention classification in Brain-Computer Interface (BCI) applications. By integrating a Temporal CNN for frequency-based EEG feature extraction, a pointwise CNN for feature enhancement, and Spatial and Temporal Patching modules for organizing features into spatial-temporal patches, EEG-PatchFormer jointly learns spatial-temporal information from EEG data. Leveraging the global learning capabilities of the self-attention mechanism, it captures essential features across brain regions over time, thereby enhancing EEG data decoding performance. Demonstrating superior performance, EEG-PatchFormer surpasses existing benchmarks in accuracy, area under the ROC curve (AUC), and macro-F1 score on a public cognitive attention dataset. The code can be found via: https://github.com/yi-ding-cs/EEG-PatchFormer .
Is Bio-Inspired Learning Better than Backprop? Benchmarking Bio Learning vs. Backprop
Dec 09, 2022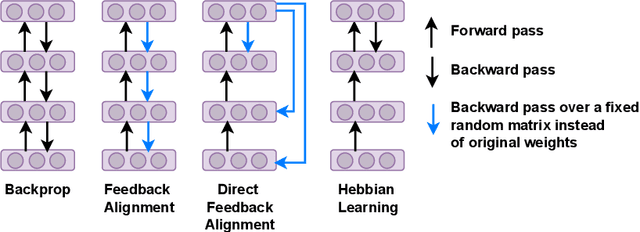
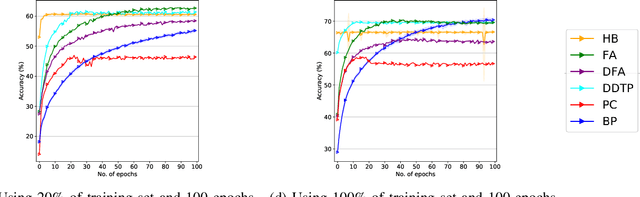
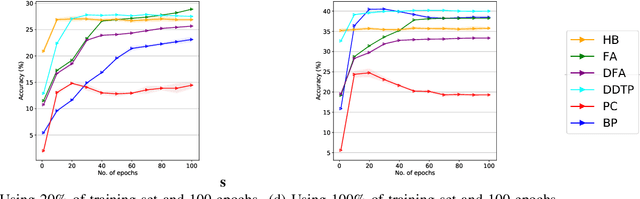
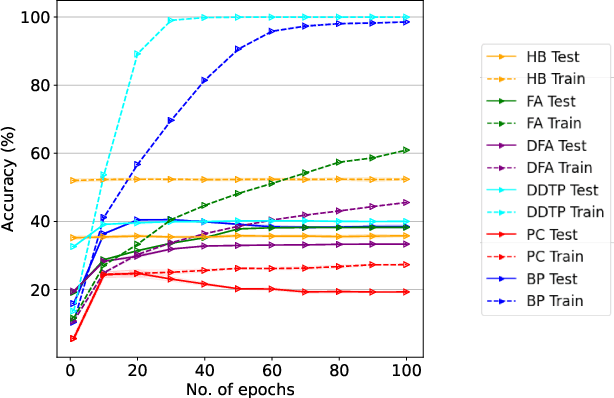
Bio-inspired learning has been gaining popularity recently given that Backpropagation (BP) is not considered biologically plausible. Many algorithms have been proposed in the literature which are all more biologically plausible than BP. However, apart from overcoming the biological implausibility of BP, a strong motivation for using Bio-inspired algorithms remains lacking. In this study, we undertake a holistic comparison of BP vs. multiple Bio-inspired algorithms to answer the question of whether Bio-learning offers additional benefits over BP, rather than just biological plausibility. We test Bio-algorithms under different design choices such as access to only partial training data, resource constraints in terms of the number of training epochs, sparsification of the neural network parameters and addition of noise to input samples. Through these experiments, we notably find two key advantages of Bio-algorithms over BP. Firstly, Bio-algorithms perform much better than BP when the entire training dataset is not supplied. Four of the five Bio-algorithms tested outperform BP by upto 5% accuracy when only 20% of the training dataset is available. Secondly, even when the full dataset is available, Bio-algorithms learn much quicker and converge to a stable accuracy in far lesser training epochs than BP. Hebbian learning, specifically, is able to learn in just 5 epochs compared to around 100 epochs required by BP. These insights present practical reasons for utilising Bio-learning rather than just its biological plausibility and also point towards interesting new directions for future work on Bio-learning.