 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Calibration Enhanced Network by Inverse Adversarial Attack
Apr 08, 2025Test automation has become increasingly important as the complexity of both design and content in Human Machine Interface (HMI) software continues to grow. Current standard practice uses Optical Character Recognition (OCR) techniques to automatically extract textual information from HMI screens for validation. At present, one of the key challenges faced during the automation of HMI screen validation is the noise handling for the OCR models. In this paper, we propose to utilize adversarial training techniques to enhance OCR models in HMI testing scenarios. More specifically, we design a new adversarial attack objective for OCR models to discover the decision boundaries in the context of HMI testing. We then adopt adversarial training to optimize the decision boundaries towards a more robust and accurate OCR model. In addition, we also built an HMI screen dataset based on real-world requirements and applied multiple types of perturbation onto the clean HMI dataset to provide a more complete coverage for the potential scenarios. We conduct experiments to demonstrate how using adversarial training techniques yields more robust OCR models against various kinds of noises, while still maintaining high OCR model accuracy. Further experiments even demonstrate that the adversarial training models exhibit a certain degree of robustness against perturbations from other patterns.
Is Bio-Inspired Learning Better than Backprop? Benchmarking Bio Learning vs. Backprop
Dec 09, 2022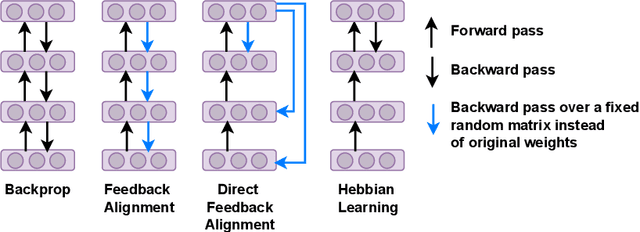
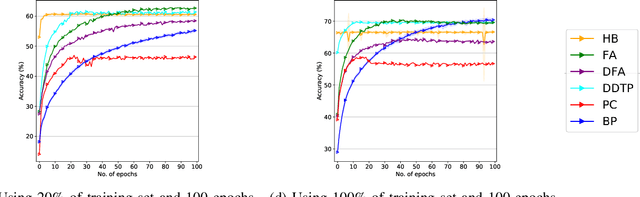
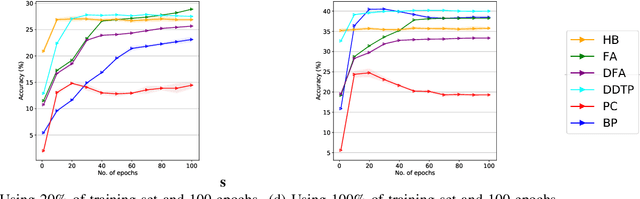
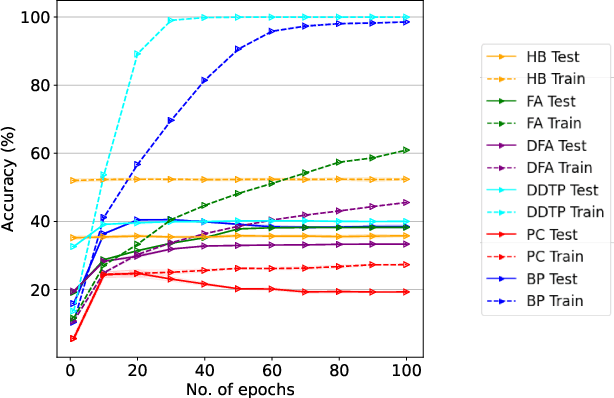
Bio-inspired learning has been gaining popularity recently given that Backpropagation (BP) is not considered biologically plausible. Many algorithms have been proposed in the literature which are all more biologically plausible than BP. However, apart from overcoming the biological implausibility of BP, a strong motivation for using Bio-inspired algorithms remains lacking. In this study, we undertake a holistic comparison of BP vs. multiple Bio-inspired algorithms to answer the question of whether Bio-learning offers additional benefits over BP, rather than just biological plausibility. We test Bio-algorithms under different design choices such as access to only partial training data, resource constraints in terms of the number of training epochs, sparsification of the neural network parameters and addition of noise to input samples. Through these experiments, we notably find two key advantages of Bio-algorithms over BP. Firstly, Bio-algorithms perform much better than BP when the entire training dataset is not supplied. Four of the five Bio-algorithms tested outperform BP by upto 5% accuracy when only 20% of the training dataset is available. Secondly, even when the full dataset is available, Bio-algorithms learn much quicker and converge to a stable accuracy in far lesser training epochs than BP. Hebbian learning, specifically, is able to learn in just 5 epochs compared to around 100 epochs required by BP. These insights present practical reasons for utilising Bio-learning rather than just its biological plausibility and also point towards interesting new directions for future work on Bio-learning.