 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERaLiON-SER: Robust Speech Emotion Recognition Model for English and SEA Languages
Nov 12, 2025



We present MERaLiON-SER, a robust speech emotion recognition model designed for English and Southeast Asian languages. The model is trained using a hybrid objective combining weighted categorical cross-entropy and Concordance Correlation Coefficient (CCC) losses for joint discrete and dimensional emotion modelling. This dual approach enables the model to capture both the distinct categories of emotion (like happy or angry) and the fine-grained, such as arousal (intensity), valence (positivity/negativity), and dominance (sense of control), leading to a more comprehensive and robust representation of human affect. Extensive evaluations across multilingual Singaporean languages (English, Chinese, Malay, and Tamil ) and other public benchmarks show that MERaLiON-SER consistently surpasses both open-source speech encoders and large Audio-LLMs. These results underscore the importance of specialised speech-only models for accurate paralinguistic understanding and cross-lingual generalisation. Furthermore, the proposed framework provides a foundation for integrating emotion-aware perception into future agentic audio systems, enabling more empathetic and contextually adaptive multimodal reasoning.
T-CBF: Traversability-based Control Barrier Function to Navigate Vertically Challenging Terrain
Mar 08, 2025
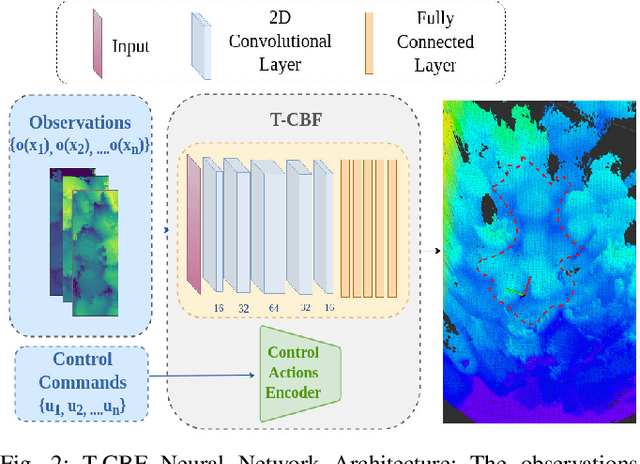


Safety has been of paramount importance in motion planning and control techniques and is an active area of research in the past few years. Most safety research for mobile robots target at maintaining safety with the notion of collision avoidance. However, safety goes beyond just avoiding collisions, especially when robots have to navigate unstructured, vertically challenging, off-road terrain, where vehicle rollover and immobilization is as critical as collisions. In this work, we introduce a novel Traversability-based Control Barrier Function (T-CBF), in which we use neural Control Barrier Functions (CBFs) to achieve safety beyond collision avoidance on unstructured vertically challenging terrain by reasoning about new safety aspects in terms of traversability. The neural T-CBF trained on safe and unsafe observations specific to traversability safety is then used to generate safe trajectories. Furthermore, we present experimental results in simulation and on a physical Verti-4 Wheeler (V4W) platform, demonstrating that T-CBF can provide traversability safety while reaching the goal position. T-CBF planner outperforms previously developed planners by 30\% in terms of keeping the robot safe and mobile when navigating on real world vertically challenging terrain.
From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
May 09, 2024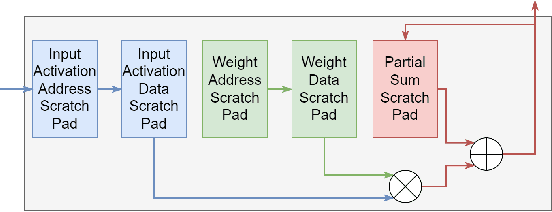
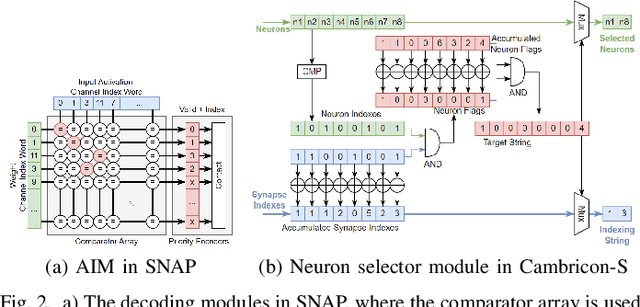
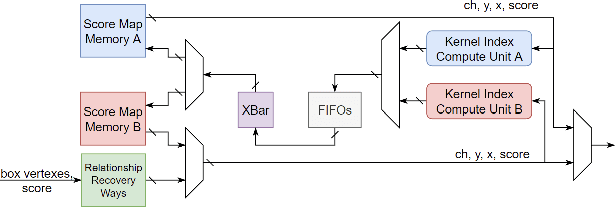

Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.
Resource Efficient Neural Networks Using Hessian Based Pruning
Jun 12, 2023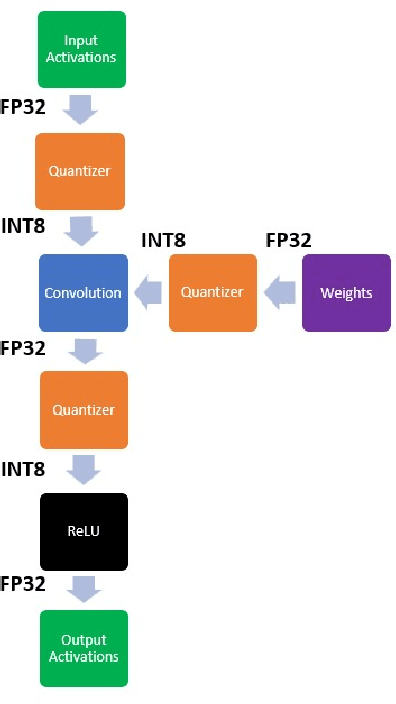
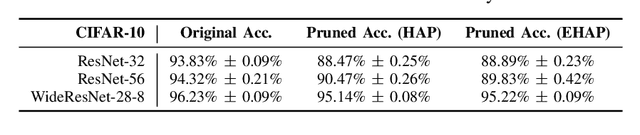

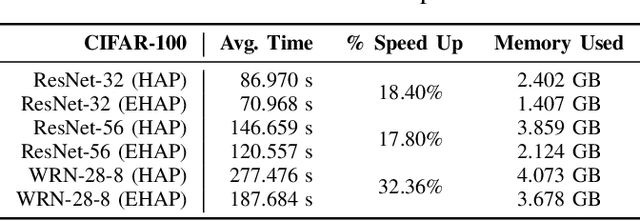
Neural network pruning is a practical way for reducing the size of trained models and the number of floating-point operations. One way of pruning is to use the relative Hessian trace to calculate sensitivity of each channel, as compared to the more common magnitude pruning approach. However, the stochastic approach used to estimate the Hessian trace needs to iterate over many times before it can converge. This can be time-consuming when used for larger models with many millions of parameters. To address this problem, we modify the existing approach by estimating the Hessian trace using FP16 precision instead of FP32. We test the modified approach (EHAP) on ResNet-32/ResNet-56/WideResNet-28-8 trained on CIFAR10/CIFAR100 image classification tasks and achieve faster computation of the Hessian trace. Specifically, our modified approach can achieve speed ups ranging from 17% to as much as 44% during our experiments on different combinations of model architectures and GPU devices. Our modified approach also takes up around 40% less GPU memory when pruning ResNet-32 and ResNet-56 models, which allows for a larger Hessian batch size to be used for estimating the Hessian trace. Meanwhile, we also present the results of pruning using both FP16 and FP32 Hessian trace calculation and show that there are no noticeable accuracy differences between the two. Overall, it is a simple and effective way to compute the relative Hessian trace faster without sacrificing on pruned model performance. We also present a full pipeline using EHAP and quantization aware training (QAT), using INT8 QAT to compress the network further after pruning. In particular, we use symmetric quantization for the weights and asymmetric quantization for the activations.
Is Bio-Inspired Learning Better than Backprop? Benchmarking Bio Learning vs. Backprop
Dec 09, 2022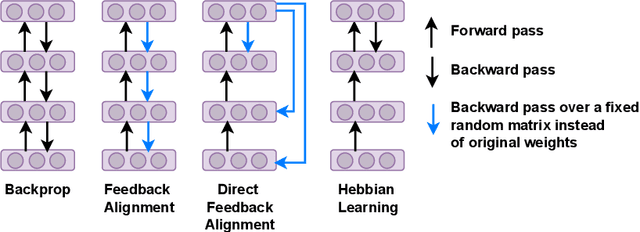
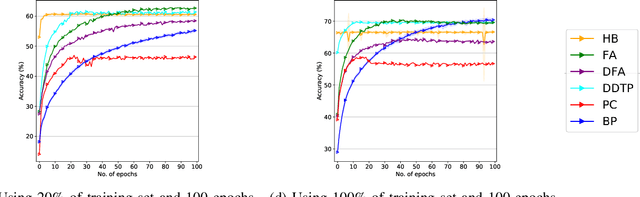
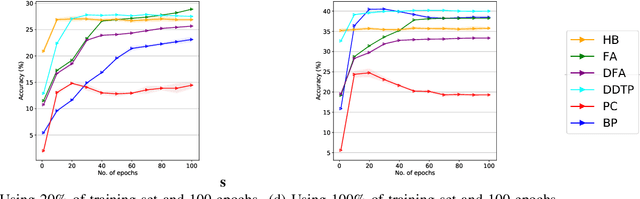
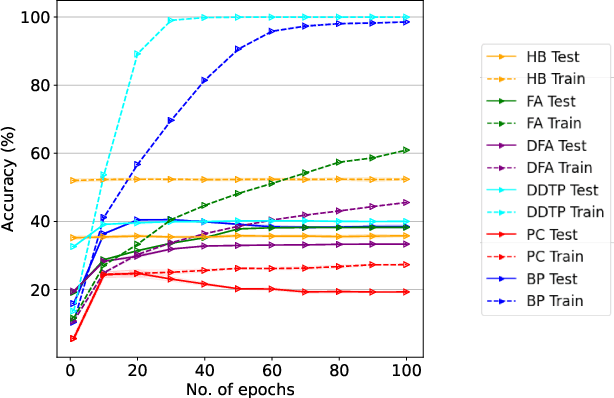
Bio-inspired learning has been gaining popularity recently given that Backpropagation (BP) is not considered biologically plausible. Many algorithms have been proposed in the literature which are all more biologically plausible than BP. However, apart from overcoming the biological implausibility of BP, a strong motivation for using Bio-inspired algorithms remains lacking. In this study, we undertake a holistic comparison of BP vs. multiple Bio-inspired algorithms to answer the question of whether Bio-learning offers additional benefits over BP, rather than just biological plausibility. We test Bio-algorithms under different design choices such as access to only partial training data, resource constraints in terms of the number of training epochs, sparsification of the neural network parameters and addition of noise to input samples. Through these experiments, we notably find two key advantages of Bio-algorithms over BP. Firstly, Bio-algorithms perform much better than BP when the entire training dataset is not supplied. Four of the five Bio-algorithms tested outperform BP by upto 5% accuracy when only 20% of the training dataset is available. Secondly, even when the full dataset is available, Bio-algorithms learn much quicker and converge to a stable accuracy in far lesser training epochs than BP. Hebbian learning, specifically, is able to learn in just 5 epochs compared to around 100 epochs required by BP. These insights present practical reasons for utilising Bio-learning rather than just its biological plausibility and also point towards interesting new directions for future work on Bio-learning.
Is Complexity Required for Neural Network Pruning? A Case Study on Global Magnitude Pruning
Sep 29, 2022
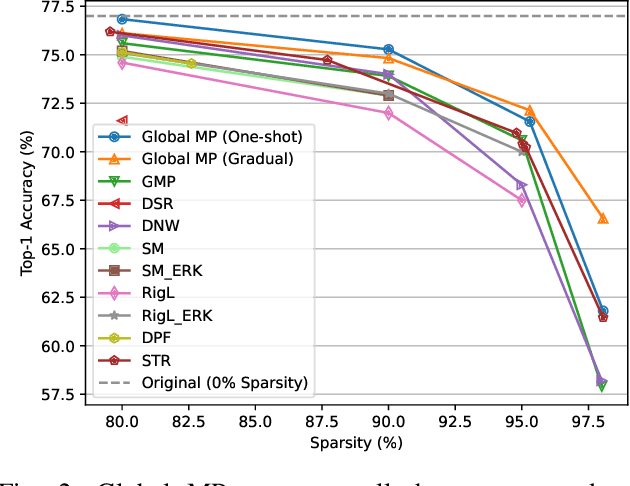
Pruning neural networks has become popular in the last decade when it was shown that a large number of weights can be safely removed from modern neural networks without compromising accuracy. Numerous pruning methods have been proposed since then, each claiming to be better than the previous. Many state-of-the-art (SOTA) techniques today rely on complex pruning methodologies utilizing importance scores, getting feedback through back-propagation or having heuristics-based pruning rules amongst others. We question this pattern of introducing complexity in order to achieve better pruning results. We benchmark these SOTA techniques against Global Magnitude Pruning (Global MP), a naive pruning baseline, to evaluate whether complexity is really needed to achieve higher performance. Global MP ranks weights in order of their magnitudes and prunes the smallest ones. Hence, in its vanilla form, it is one of the simplest pruning techniques. Surprisingly, we find that vanilla Global MP outperforms all the other SOTA techniques and achieves a new SOTA result. It also achieves good performance on FLOPs sparsification, which we find is enhanced, when pruning is conducted in a gradual fashion. We also find that Global MP is generalizable across tasks, datasets and models with superior performance. Moreover, a common issue that many pruning algorithms run into at high sparsity rates, namely, layer-collapse, can be easily fixed in Global MP by setting a minimum threshold of weights to be retained in each layer. Lastly, unlike many other SOTA techniques, Global MP does not require any additional algorithm specific hyper-parameters and is very straightforward to tune and implement. We showcase our findings on various models (WRN-28-8, ResNet-32, ResNet-50, MobileNet-V1 and FastGRNN) and multiple datasets (CIFAR-10, ImageNet and HAR-2). Code is available at https://github.com/manasgupta-1/GlobalMP.
PaRT: Parallel Learning Towards Robust and Transparent AI
Jan 24, 2022



This paper takes a parallel learning approach for robust and transparent AI. A deep neural network is trained in parallel on multiple tasks, where each task is trained only on a subset of the network resources. Each subset consists of network segments, that can be combined and shared across specific tasks. Tasks can share resources with other tasks, while having independent task-related network resources. Therefore, the trained network can share similar representations across various tasks, while also enabling independent task-related representations. The above allows for some crucial outcomes. (1) The parallel nature of our approach negates the issue of catastrophic forgetting. (2) The sharing of segments uses network resources more efficiently. (3) We show that the network does indeed use learned knowledge from some tasks in other tasks, through shared representations. (4) Through examination of individual task-related and shared representations, the model offers transparency in the network and in the relationships across tasks in a multi-task setting. Evaluation of the proposed approach against complex competing approaches such as Continual Learning, Neural Architecture Search, and Multi-task learning shows that it is capable of learning robust representations. This is the first effort to train a DL model on multiple tasks in parallel. Our code is available at https://github.com/MahsaPaknezhad/PaRT
Learning to Prune Deep Neural Networks via Reinforcement Learning
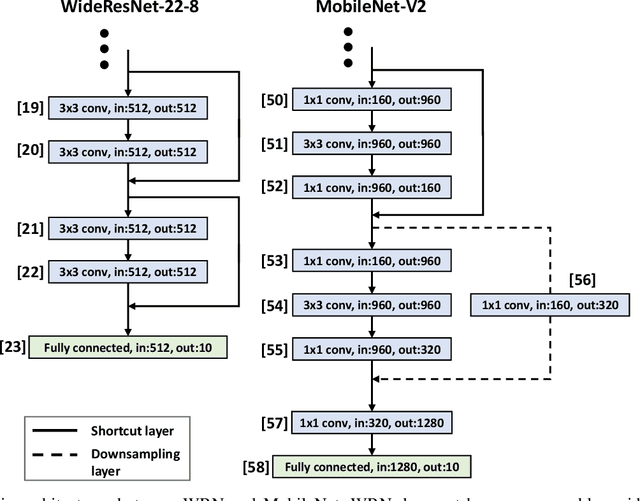
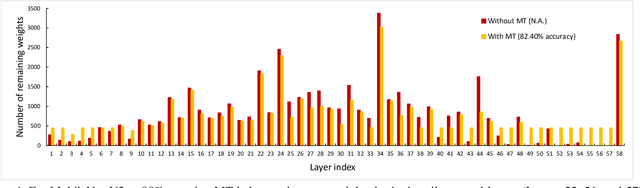
Jul 09, 2020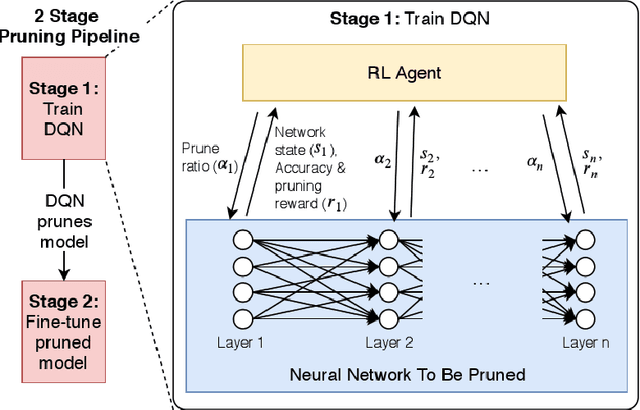
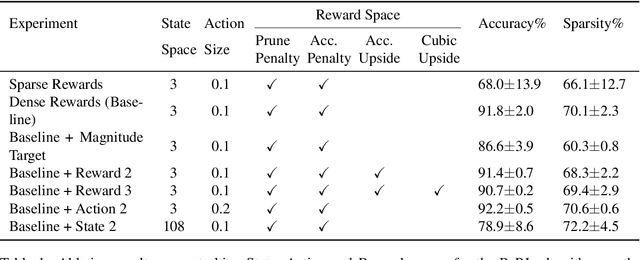
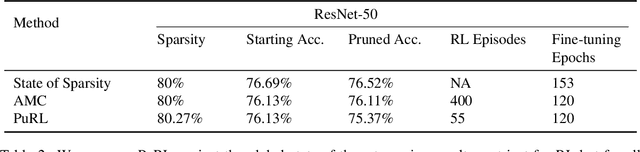
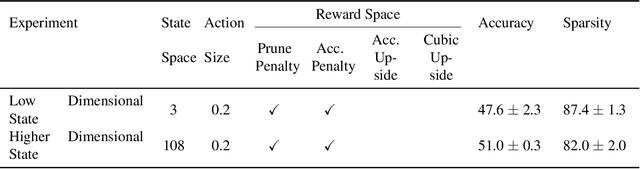
This paper proposes PuRL - a deep reinforcement learning (RL) based algorithm for pruning neural networks. Unlike current RL based model compression approaches where feedback is given only at the end of each episode to the agent, PuRL provides rewards at every pruning step. This enables PuRL to achieve sparsity and accuracy comparable to current state-of-the-art methods, while having a much shorter training cycle. PuRL achieves more than 80% sparsity on the ResNet-50 model while retaining a Top-1 accuracy of 75.37% on the ImageNet dataset. Through our experiments we show that PuRL is also able to sparsify already efficient architectures like MobileNet-V2. In addition to performance characterisation experiments, we also provide a discussion and analysis of the various RL design choices that went into the tuning of the Markov Decision Process underlying PuRL. Lastly, we point out that PuRL is simple to use and can be easily adapted for various architectures.