 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA*HAR: A New Benchmark towards Semi-supervised learning for Class-imbalanced Human Activity Recognition
Jan 13, 2021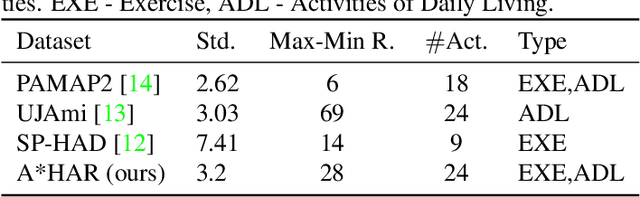
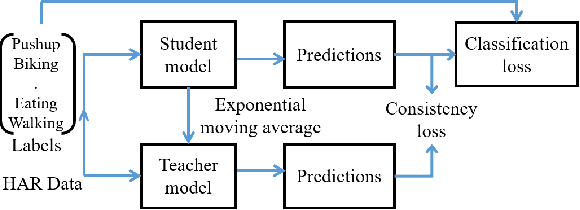
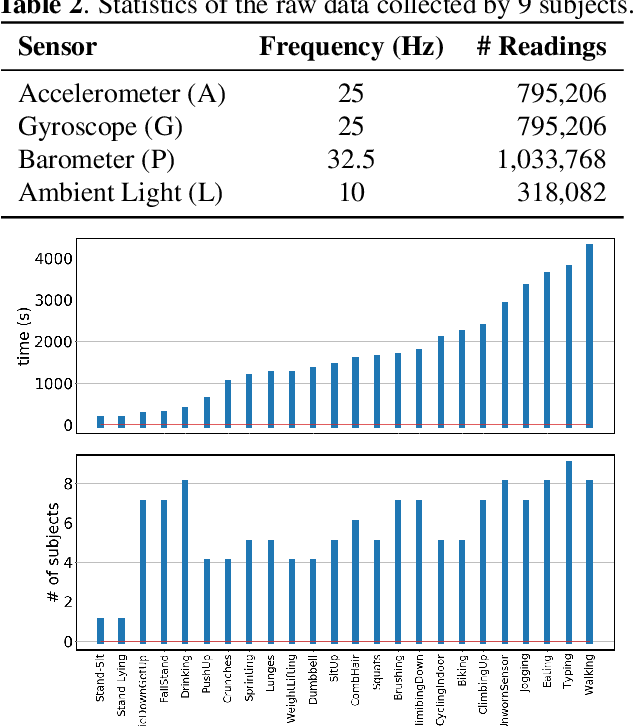
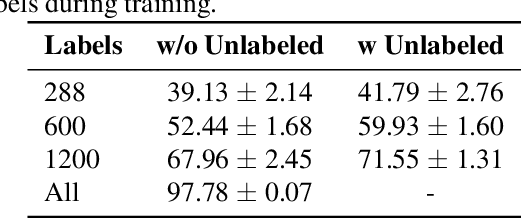
Despite the vast literature on Human Activity Recognition (HAR) with wearable inertial sensor data, it is perhaps surprising that there are few studies investigating semisupervised learning for HAR, particularly in a challenging scenario with class imbalance problem. In this work, we present a new benchmark, called A*HAR, towards semisupervised learning for class-imbalanced HAR. We evaluate state-of-the-art semi-supervised learning method on A*HAR, by combining Mean Teacher and Convolutional Neural Network. Interestingly, we find that Mean Teacher boosts the overall performance when training the classifier with fewer labelled samples and a large amount of unlabeled samples, but the classifier falls short in handling unbalanced activities. These findings lead to an interesting open problem, i.e., development of semi-supervised HAR algorithms that are class-imbalance aware without any prior knowledge on the class distribution for unlabeled samples. The dataset and benchmark evaluation are released at https://github.com/I2RDL2/ASTAR-HAR for future research.
Learning to Prune Deep Neural Networks via Reinforcement Learning
Jul 09, 2020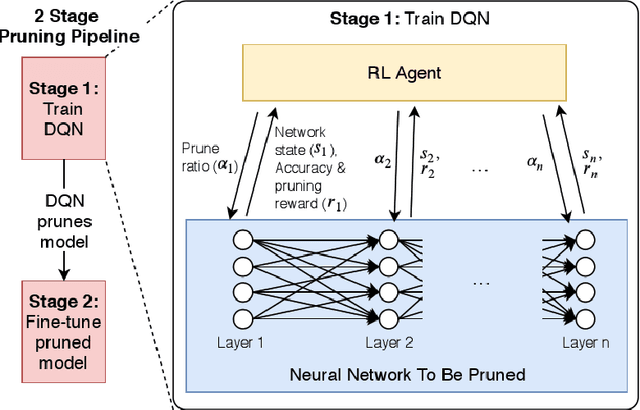
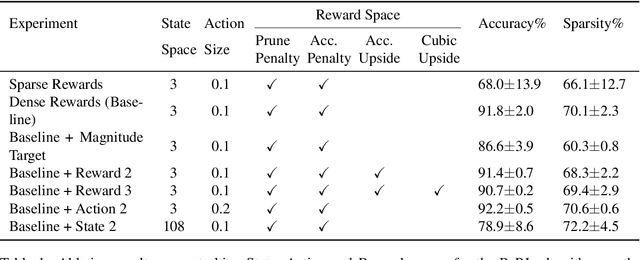
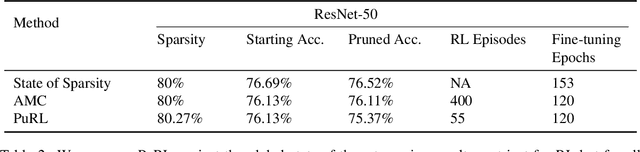
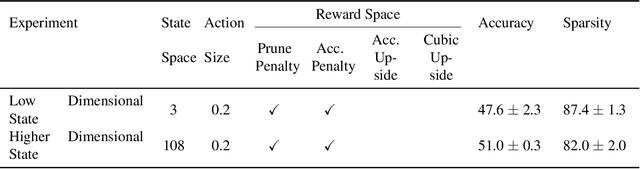
This paper proposes PuRL - a deep reinforcement learning (RL) based algorithm for pruning neural networks. Unlike current RL based model compression approaches where feedback is given only at the end of each episode to the agent, PuRL provides rewards at every pruning step. This enables PuRL to achieve sparsity and accuracy comparable to current state-of-the-art methods, while having a much shorter training cycle. PuRL achieves more than 80% sparsity on the ResNet-50 model while retaining a Top-1 accuracy of 75.37% on the ImageNet dataset. Through our experiments we show that PuRL is also able to sparsify already efficient architectures like MobileNet-V2. In addition to performance characterisation experiments, we also provide a discussion and analysis of the various RL design choices that went into the tuning of the Markov Decision Process underlying PuRL. Lastly, we point out that PuRL is simple to use and can be easily adapted for various architectures.
Empirical Analysis of Overfitting and Mode Drop in GAN Training
Jun 25, 2020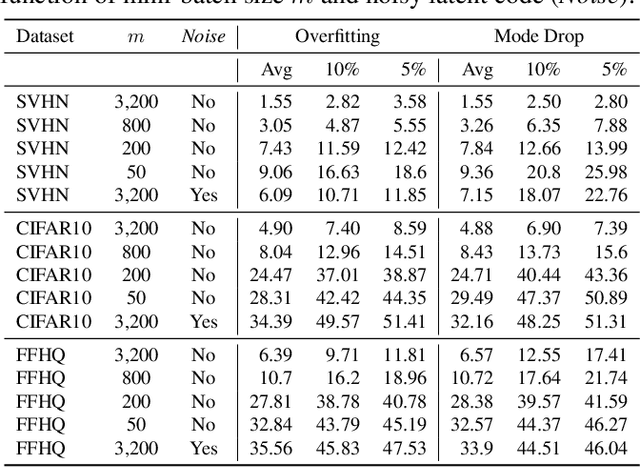


We examine two key questions in GAN training, namely overfitting and mode drop, from an empirical perspective. We show that when stochasticity is removed from the training procedure, GANs can overfit and exhibit almost no mode drop. Our results shed light on important characteristics of the GAN training procedure. They also provide evidence against prevailing intuitions that GANs do not memorize the training set, and that mode dropping is mainly due to properties of the GAN objective rather than how it is optimized during training.
Classification Representations Can be Reused for Downstream Generations
Apr 16, 2020
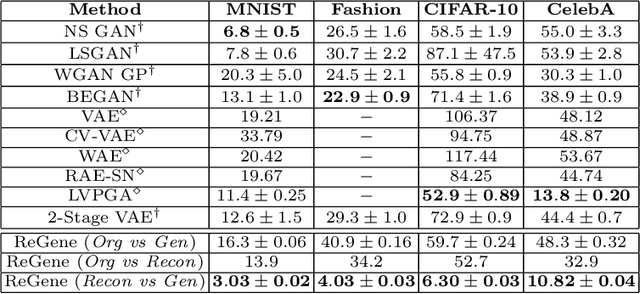
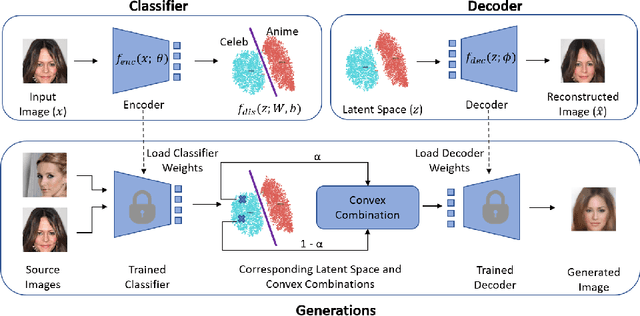

Contrary to the convention of using supervision for class-conditioned $\it{generative}$ $\it{modeling}$, this work explores and demonstrates the feasibility of a learned supervised representation space trained on a discriminative classifier for the $\it{downstream}$ task of sample generation. Unlike generative modeling approaches that aim to $\it{model}$ the manifold distribution, we directly $\it{represent}$ the given data manifold in the classification space and leverage properties of latent space representations to generate new representations that are guaranteed to be in the same class. Interestingly, such representations allow for controlled sample generations for any given class from existing samples and do not require enforcing prior distribution. We show that these latent space representations can be smartly manipulated (using convex combinations of $n$ samples, $n\geq2$) to yield meaningful sample generations. Experiments on image datasets of varying resolutions demonstrate that downstream generations have higher classification accuracy than existing conditional generative models while being competitive in terms of FID.
A*3D Dataset: Towards Autonomous Driving in Challenging Environments
Sep 17, 2019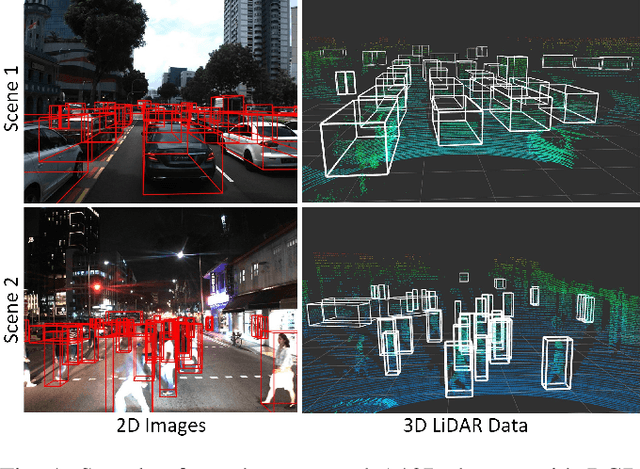
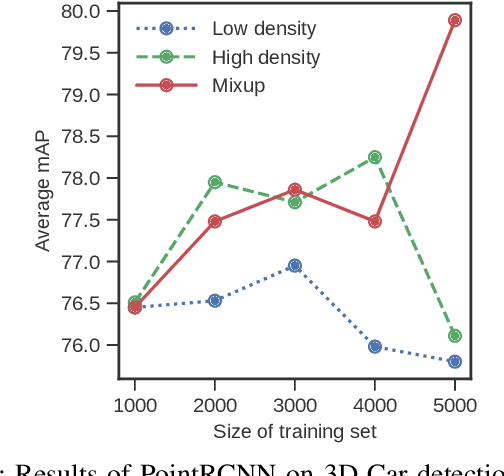
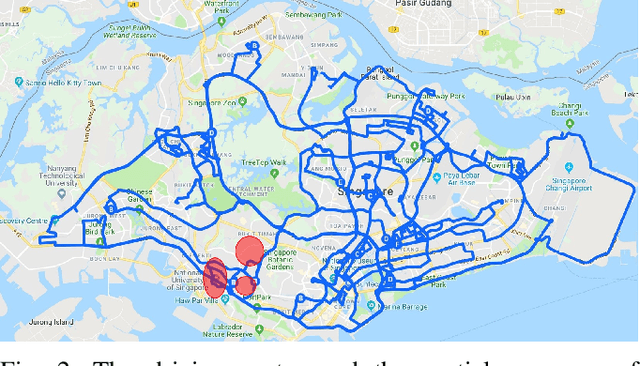
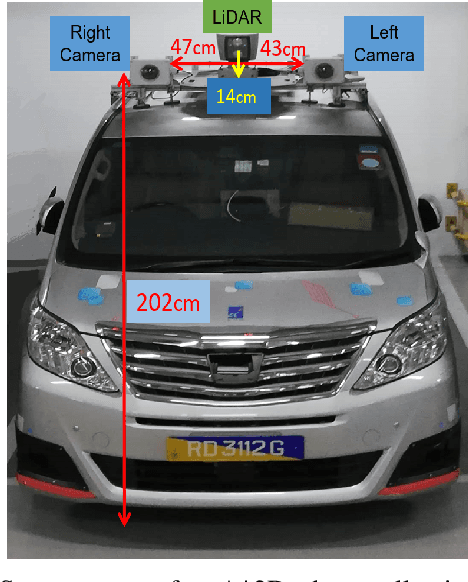
With the increasing global popularity of self-driving cars, there is an immediate need for challenging real-world datasets for benchmarking and training various computer vision tasks such as 3D object detection. Existing datasets either represent simple scenarios or provide only day-time data. In this paper, we introduce a new challenging A*3D dataset which consists of RGB images and LiDAR data with significant diversity of scene, time, and weather. The dataset consists of high-density images ($\approx~10$ times more than the pioneering KITTI dataset), heavy occlusions, a large number of night-time frames ($\approx~3$ times the nuScenes dataset), addressing the gaps in the existing datasets to push the boundaries of tasks in autonomous driving research to more challenging highly diverse environments. The dataset contains $39\text{K}$ frames, $7$ classes, and $230\text{K}$ 3D object annotations. An extensive 3D object detection benchmark evaluation on the A*3D dataset for various attributes such as high density, day-time/night-time, gives interesting insights into the advantages and limitations of training and testing 3D object detection in real-world setting.
Venn GAN: Discovering Commonalities and Particularities of Multiple Distributions
Feb 09, 2019We propose a GAN design which models multiple distributions effectively and discovers their commonalities and particularities. Each data distribution is modeled with a mixture of $K$ generator distributions. As the generators are partially shared between the modeling of different true data distributions, shared ones captures the commonality of the distributions, while non-shared ones capture unique aspects of them. We show the effectiveness of our method on various datasets (MNIST, Fashion MNIST, CIFAR-10, Omniglot, CelebA) with compelling results.
Dataflow-based Joint Quantization of Weights and Activations for Deep Neural Networks
Jan 04, 2019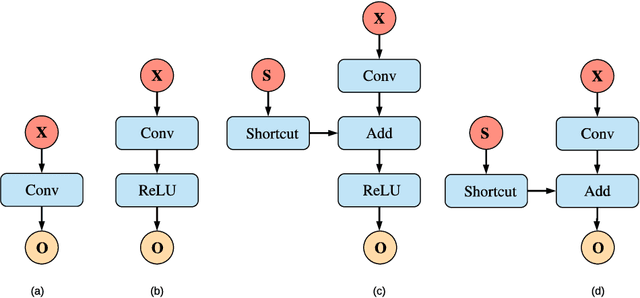



This paper addresses a challenging problem - how to reduce energy consumption without incurring performance drop when deploying deep neural networks (DNNs) at the inference stage. In order to alleviate the computation and storage burdens, we propose a novel dataflow-based joint quantization approach with the hypothesis that a fewer number of quantization operations would incur less information loss and thus improve the final performance. It first introduces a quantization scheme with efficient bit-shifting and rounding operations to represent network parameters and activations in low precision. Then it restructures the network architectures to form unified modules for optimization on the quantized model. Extensive experiments on ImageNet and KITTI validate the effectiveness of our model, demonstrating that state-of-the-art results for various tasks can be achieved by this quantized model. Besides, we designed and synthesized an RTL model to measure the hardware costs among various quantization methods. For each quantization operation, it reduces area cost by about 15 times and energy consumption by about 9 times, compared to a strong baseline.
Semi-Supervised Deep Learning for Abnormality Classification in Retinal Images
Dec 19, 2018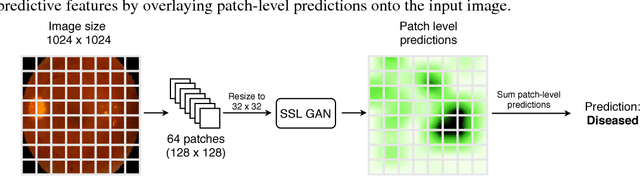


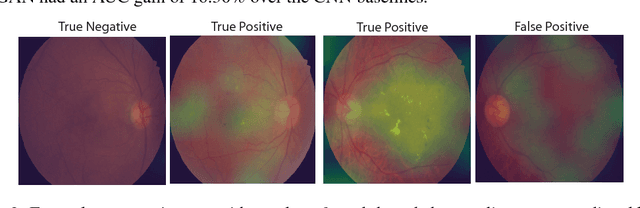
Supervised deep learning algorithms have enabled significant performance gains in medical image classification tasks. But these methods rely on large labeled datasets that require resource-intensive expert annotation. Semi-supervised generative adversarial network (GAN) approaches offer a means to learn from limited labeled data alongside larger unlabeled datasets, but have not been applied to discern fine-scale, sparse or localized features that define medical abnormalities. To overcome these limitations, we propose a patch-based semi-supervised learning approach and evaluate performance on classification of diabetic retinopathy from funduscopic images. Our semi-supervised approach achieves high AUC with just 10-20 labeled training images, and outperforms the supervised baselines by upto 15% when less than 30% of the training dataset is labeled. Further, our method implicitly enables interpretation of the SSL predictions. As this approach enables good accuracy, resolution and interpretability with lower annotation burden, it sets the pathway for scalable applications of deep learning in clinical imaging.
Holistic Multi-modal Memory Network for Movie Question Answering
Nov 12, 2018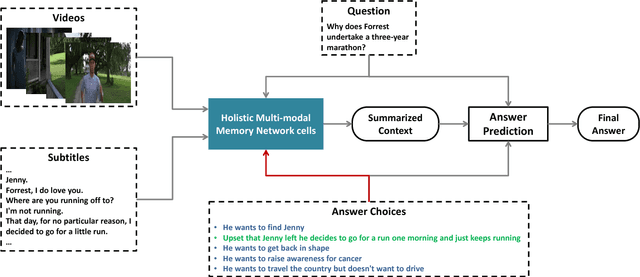
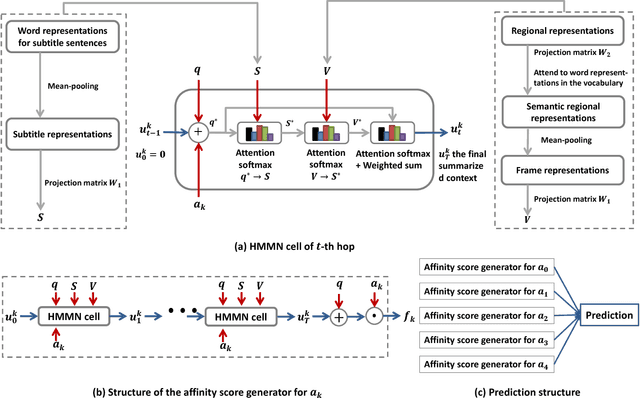
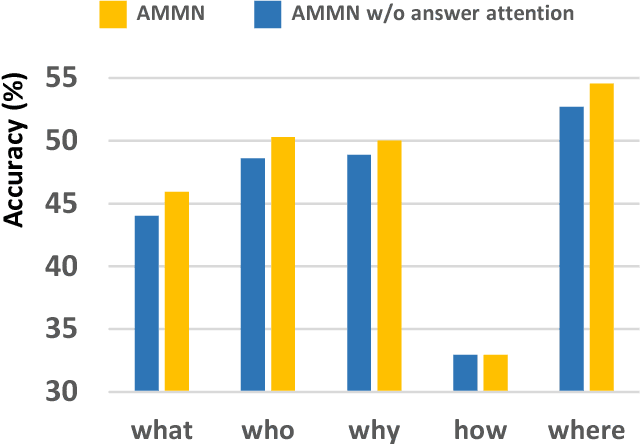
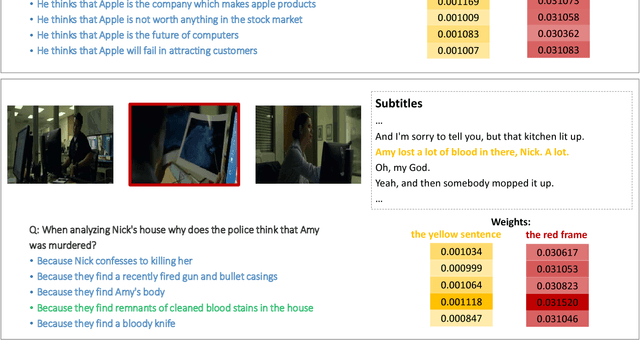
Answering questions according to multi-modal context is a challenging problem as it requires a deep integration of different data sources. Existing approaches only employ partial interactions among data sources in one attention hop. In this paper, we present the Holistic Multi-modal Memory Network (HMMN) framework which fully considers the interactions between different input sources (multi-modal context, question) in each hop. In addition, it takes answer choices into consideration during the context retrieval stage. Therefore, the proposed framework effectively integrates multi-modal context, question, and answer information, which leads to more informative context retrieved for question answering. Our HMMN framework achieves state-of-the-art accuracy on MovieQA dataset. Extensive ablation studies show the importance of holistic reasoning and contributions of different attention strategies.
Optimistic mirror descent in saddle-point problems: Going the extra (gradient) mile
Oct 01, 2018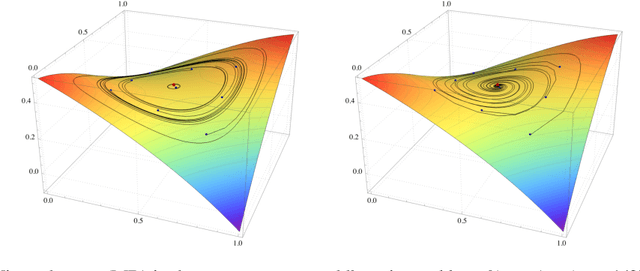

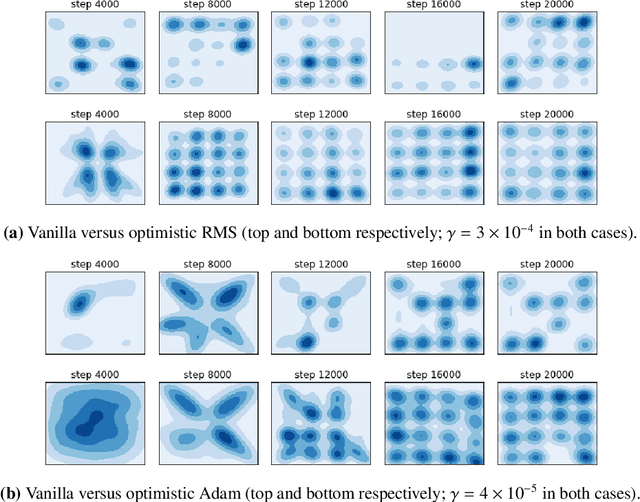
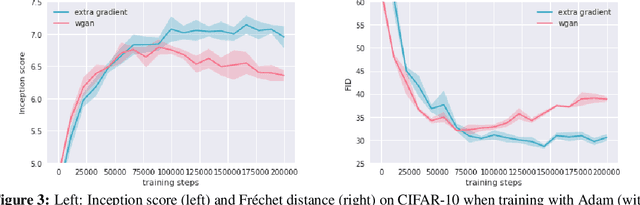
Owing to their connection with generative adversarial networks (GANs), saddle-point problems have recently attracted considerable interest in machine learning and beyond. By necessity, most theoretical guarantees revolve around convex-concave (or even linear) problems; however, making theoretical inroads towards efficient GAN training depends crucially on moving beyond this classic framework. To make piecemeal progress along these lines, we analyze the behavior of mirror descent (MD) in a class of non-monotone problems whose solutions coincide with those of a naturally associated variational inequality - a property which we call coherence. We first show that ordinary, "vanilla" MD converges under a strict version of this condition, but not otherwise; in particular, it may fail to converge even in bilinear models with a unique solution. We then show that this deficiency is mitigated by optimism: by taking an "extra-gradient" step, optimistic mirror descent (OMD) converges in all coherent problems. Our analysis generalizes and extends the results of Daskalakis et al. (2018) for optimistic gradient descent (OGD) in bilinear problems, and makes concrete headway for establishing convergence beyond convex-concave games. We also provide stochastic analogues of these results, and we validate our analysis by numerical experiments in a wide array of GAN models (including Gaussian mixture models, as well as the CelebA and CIFAR-10 datasets).