 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVaDE : Event-Based Variational Thompson Sampling for Model-Based Reinforcement Learning
Jan 16, 2025



Posterior Sampling for Reinforcement Learning (PSRL) is a well-known algorithm that augments model-based reinforcement learning (MBRL) algorithms with Thompson sampling. PSRL maintains posterior distributions of the environment transition dynamics and the reward function, which are intractable for tasks with high-dimensional state and action spaces. Recent works show that dropout, used in conjunction with neural networks, induces variational distributions that can approximate these posteriors. In this paper, we propose Event-based Variational Distributions for Exploration (EVaDE), which are variational distributions that are useful for MBRL, especially when the underlying domain is object-based. We leverage the general domain knowledge of object-based domains to design three types of event-based convolutional layers to direct exploration. These layers rely on Gaussian dropouts and are inserted between the layers of the deep neural network model to help facilitate variational Thompson sampling. We empirically show the effectiveness of EVaDE-equipped Simulated Policy Learning (EVaDE-SimPLe) on the 100K Atari game suite.
Instructive3D: Editing Large Reconstruction Models with Text Instructions
Jan 08, 2025



Transformer based methods have enabled users to create, modify, and comprehend text and image data. Recently proposed Large Reconstruction Models (LRMs) further extend this by providing the ability to generate high-quality 3D models with the help of a single object image. These models, however, lack the ability to manipulate or edit the finer details, such as adding standard design patterns or changing the color and reflectance of the generated objects, thus lacking fine-grained control that may be very helpful in domains such as augmented reality, animation and gaming. Naively training LRMs for this purpose would require generating precisely edited images and 3D object pairs, which is computationally expensive. In this paper, we propose Instructive3D, a novel LRM based model that integrates generation and fine-grained editing, through user text prompts, of 3D objects into a single model. We accomplish this by adding an adapter that performs a diffusion process conditioned on a text prompt specifying edits in the triplane latent space representation of 3D object models. Our method does not require the generation of edited 3D objects. Additionally, Instructive3D allows us to perform geometrically consistent modifications, as the edits done through user-defined text prompts are applied to the triplane latent representation thus enhancing the versatility and precision of 3D objects generated. We compare the objects generated by Instructive3D and a baseline that first generates the 3D object meshes using a standard LRM model and then edits these 3D objects using text prompts when images are provided from the Objaverse LVIS dataset. We find that Instructive3D produces qualitatively superior 3D objects with the properties specified by the edit prompts.
ExPoSe: Combining State-Based Exploration with Gradient-Based Online Search
Feb 04, 2022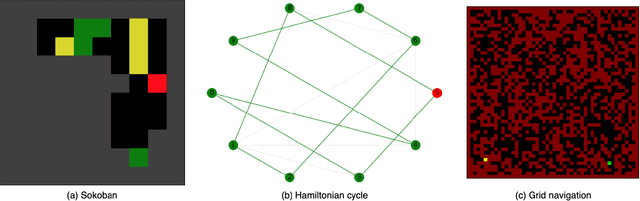


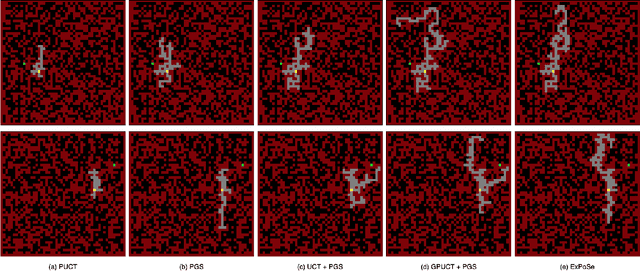
A tree-based online search algorithm iteratively simulates trajectories and updates Q-value information on a set of states represented by a tree structure. Alternatively, policy gradient based online search algorithms update the information obtained from simulated trajectories directly onto the parameters of the policy and has been found to be effective. While tree-based methods limit the updates from simulations to the states that exist in the tree and do not interpolate the information to nearby states, policy gradient search methods do not do explicit exploration. In this paper, we show that it is possible to combine and leverage the strengths of these two methods for improved search performance. We examine the key reasons behind the improvement and propose a simple yet effective online search method, named Exploratory Policy Gradient Search (ExPoSe), that updates both the parameters of the policy as well as search information on the states in the trajectory. We conduct experiments on complex planning problems, which include Sokoban and Hamiltonian cycle search in sparse graphs and show that combining exploration with policy gradient improves online search performance.
State-Aware Variational Thompson Sampling for Deep Q-Networks
Feb 07, 2021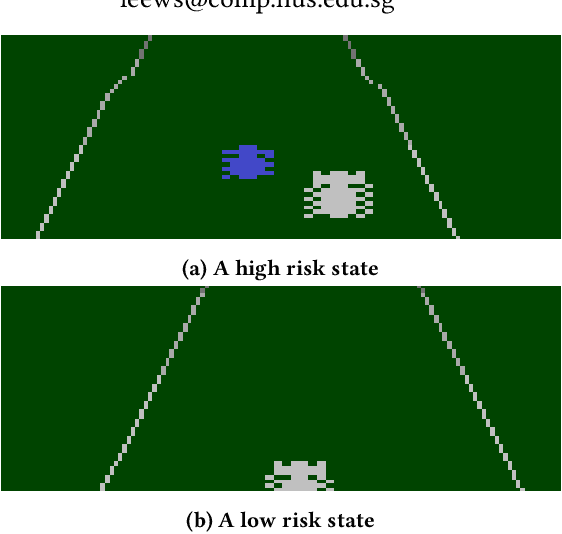
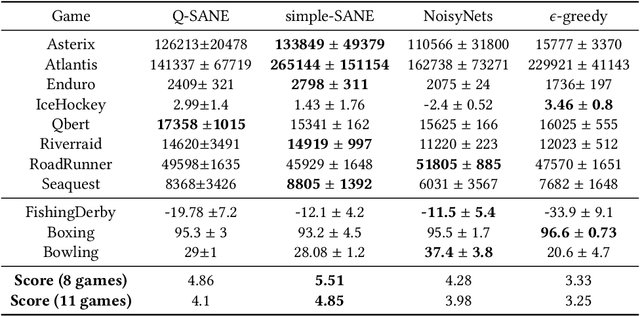
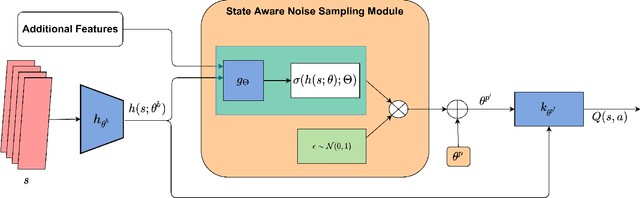
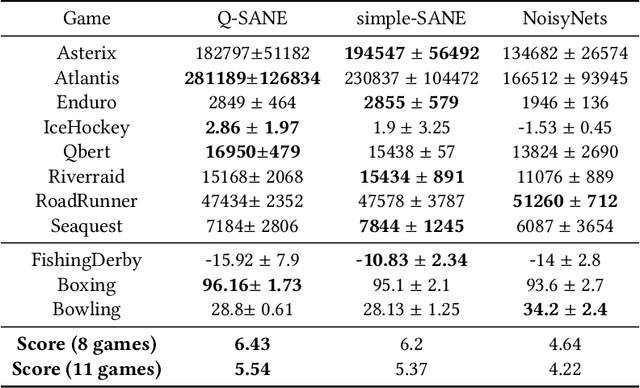
Thompson sampling is a well-known approach for balancing exploration and exploitation in reinforcement learning. It requires the posterior distribution of value-action functions to be maintained; this is generally intractable for tasks that have a high dimensional state-action space. We derive a variational Thompson sampling approximation for DQNs which uses a deep network whose parameters are perturbed by a learned variational noise distribution. We interpret the successful NoisyNets method \cite{fortunato2018noisy} as an approximation to the variational Thompson sampling method that we derive. Further, we propose State Aware Noisy Exploration (SANE) which seeks to improve on NoisyNets by allowing a non-uniform perturbation, where the amount of parameter perturbation is conditioned on the state of the agent. This is done with the help of an auxiliary perturbation module, whose output is state dependent and is learnt end to end with gradient descent. We hypothesize that such state-aware noisy exploration is particularly useful in problems where exploration in certain \textit{high risk} states may result in the agent failing badly. We demonstrate the effectiveness of the state-aware exploration method in the off-policy setting by augmenting DQNs with the auxiliary perturbation module.
An Analysis of Frame-skipping in Reinforcement Learning
Feb 07, 2021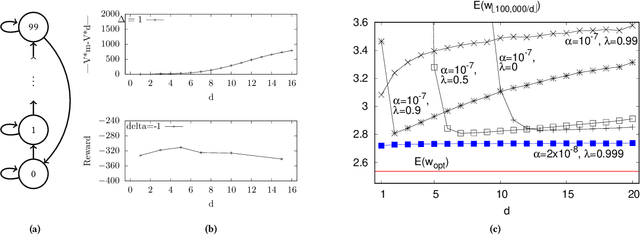
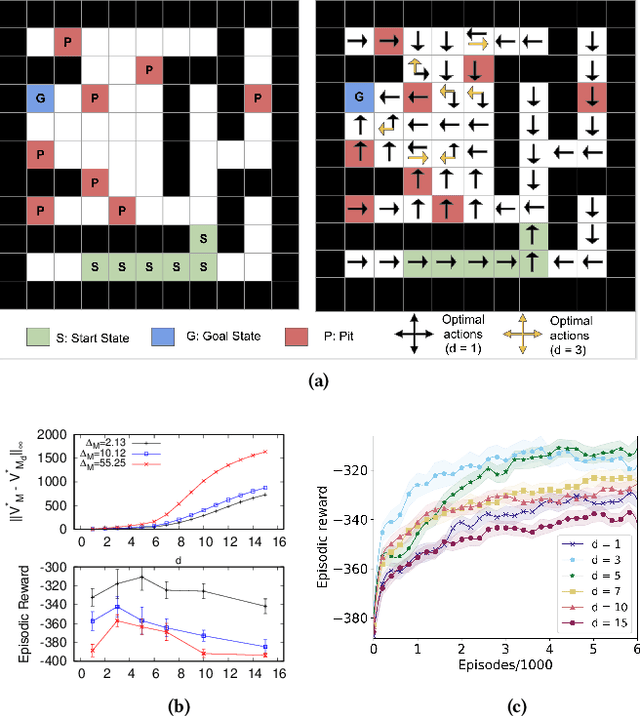
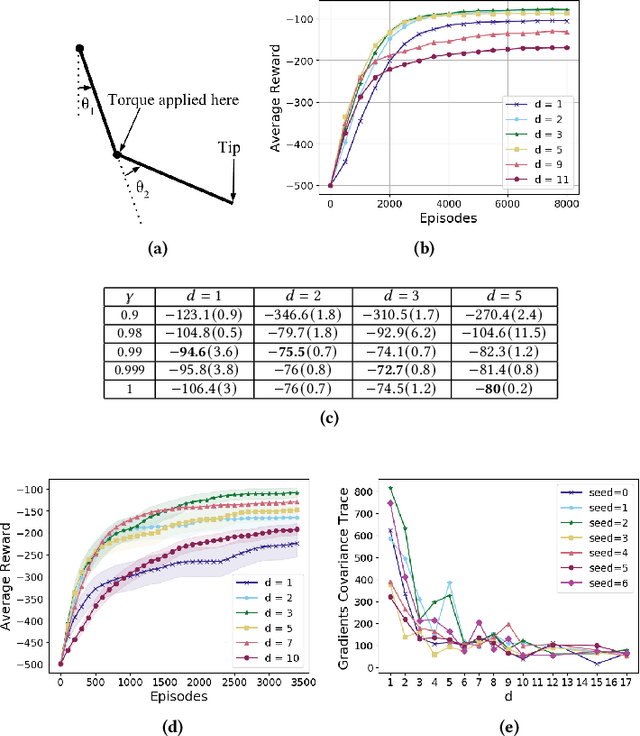
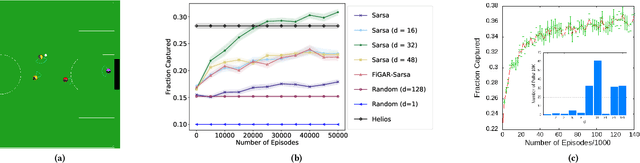
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.
Learning to Prune Deep Neural Networks via Reinforcement Learning
Jul 09, 2020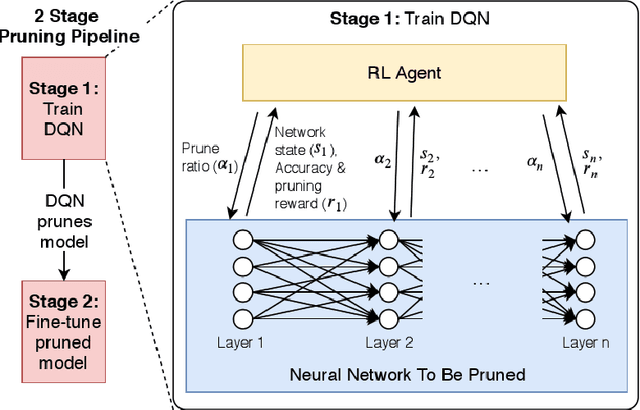
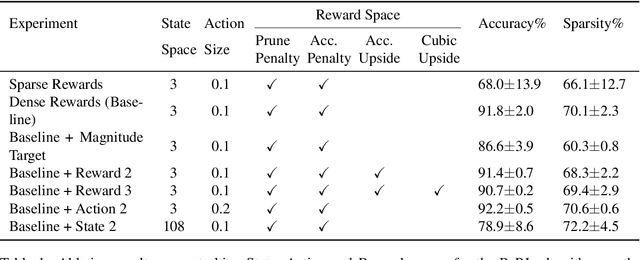
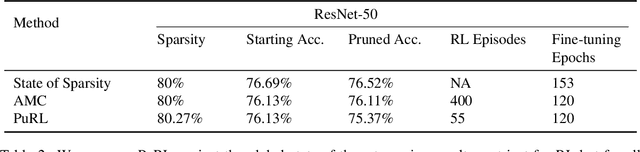
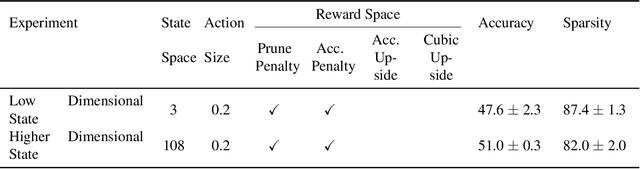
This paper proposes PuRL - a deep reinforcement learning (RL) based algorithm for pruning neural networks. Unlike current RL based model compression approaches where feedback is given only at the end of each episode to the agent, PuRL provides rewards at every pruning step. This enables PuRL to achieve sparsity and accuracy comparable to current state-of-the-art methods, while having a much shorter training cycle. PuRL achieves more than 80% sparsity on the ResNet-50 model while retaining a Top-1 accuracy of 75.37% on the ImageNet dataset. Through our experiments we show that PuRL is also able to sparsify already efficient architectures like MobileNet-V2. In addition to performance characterisation experiments, we also provide a discussion and analysis of the various RL design choices that went into the tuning of the Markov Decision Process underlying PuRL. Lastly, we point out that PuRL is simple to use and can be easily adapted for various architectures.