 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIDO: Bringing Democratic Order to Abstractive Summarization
Feb 25, 2025



Hallucination refers to the inaccurate, irrelevant, and inconsistent text generated from large language models (LLMs). While the LLMs have shown great promise in a variety of tasks, the issue of hallucination still remains a major challenge for many practical uses. In this paper, we tackle the issue of hallucination in abstract text summarization by mitigating exposure bias. Existing models targeted for exposure bias mitigation, namely BRIO, aim for better summarization quality in the ROUGE score. We propose a model that uses a similar exposure bias mitigation strategy but with a goal that is aligned with less hallucination. We conjecture that among a group of candidate outputs, ones with hallucinations will comprise the minority of the whole group. That is, candidates with less similarity with others will have a higher chance of containing hallucinated content. Our method uses this aspect and utilizes contrastive learning, incentivizing candidates with high inter-candidate ROUGE scores. We performed experiments on the XSum and CNN/DM summarization datasets, and our method showed 6.25% and 3.82% improvement, respectively, on the consistency G-Eval score over BRIO.
Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Mar 14, 2024In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 100s of layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across Encoder-only, Decoder-only and Encoder-Decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for image classification.
Hole-robust Wireframe Detection
Nov 30, 2021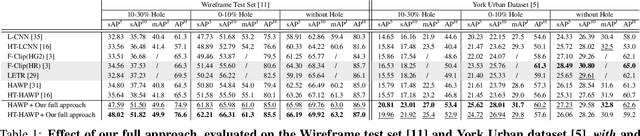
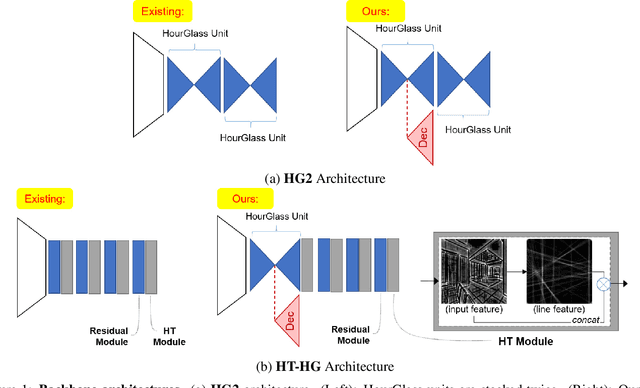
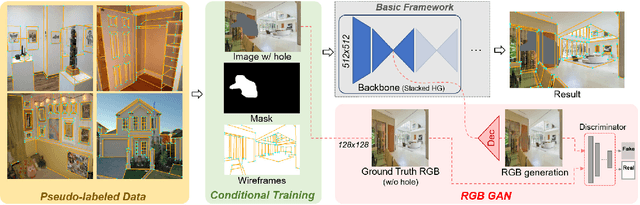
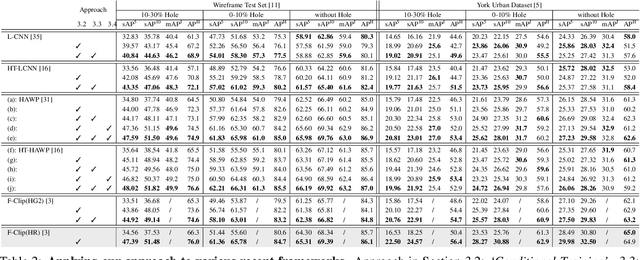
"Wireframe" is a line segment based representation designed to well capture large-scale visual properties of regular, structural shaped man-made scenes surrounding us. Unlike the wireframes, conventional edges or line segments focus on all visible edges and lines without particularly distinguishing which of them are more salient to man-made structural information. Existing wireframe detection models rely on supervising the annotated data but do not explicitly pay attention to understand how to compose the structural shapes of the scene. In addition, we often face that many foreground objects occluding the background scene interfere with proper inference of the full scene structure behind them. To resolve these problems, we first time in the field, propose new conditional data generation and training that help the model understand how to ignore occlusion indicated by holes, such as foreground object regions masked out on the image. In addition, we first time combine GAN in the model to let the model better predict underlying scene structure even beyond large holes. We also introduce pseudo labeling to further enlarge the model capacity to overcome small-scale labeled data. We show qualitatively and quantitatively that our approach significantly outperforms previous works unable to handle holes, as well as improves ordinary detection without holes given.
Resolution-robust Large Mask Inpainting with Fourier Convolutions
Sep 15, 2021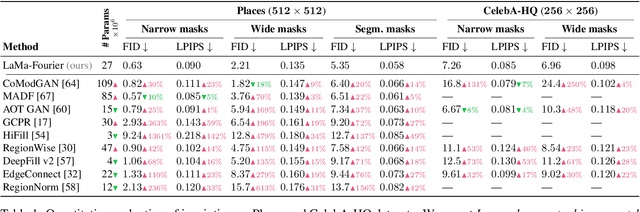
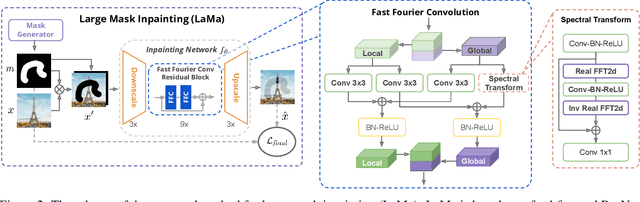
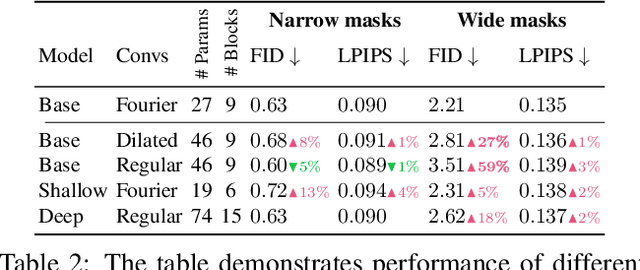

Modern image inpainting systems, despite the significant progress, often struggle with large missing areas, complex geometric structures, and high-resolution images. We find that one of the main reasons for that is the lack of an effective receptive field in both the inpainting network and the loss function. To alleviate this issue, we propose a new method called large mask inpainting (LaMa). LaMa is based on i) a new inpainting network architecture that uses fast Fourier convolutions, which have the image-wide receptive field; ii) a high receptive field perceptual loss; and iii) large training masks, which unlocks the potential of the first two components. Our inpainting network improves the state-of-the-art across a range of datasets and achieves excellent performance even in challenging scenarios, e.g. completion of periodic structures. Our model generalizes surprisingly well to resolutions that are higher than those seen at train time, and achieves this at lower parameter&compute costs than the competitive baselines. The code is available at https://github.com/saic-mdal/lama.
An Analysis of Frame-skipping in Reinforcement Learning
Feb 07, 2021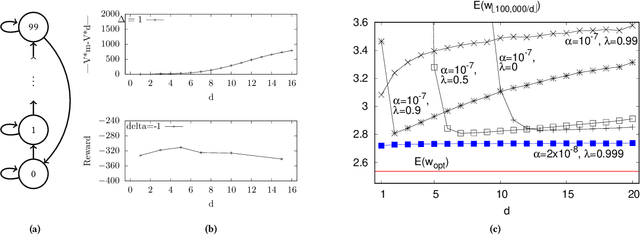
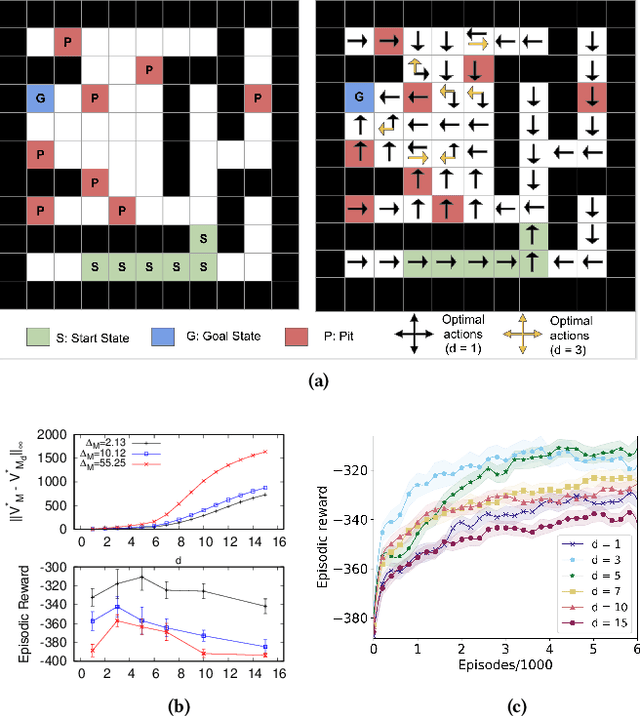
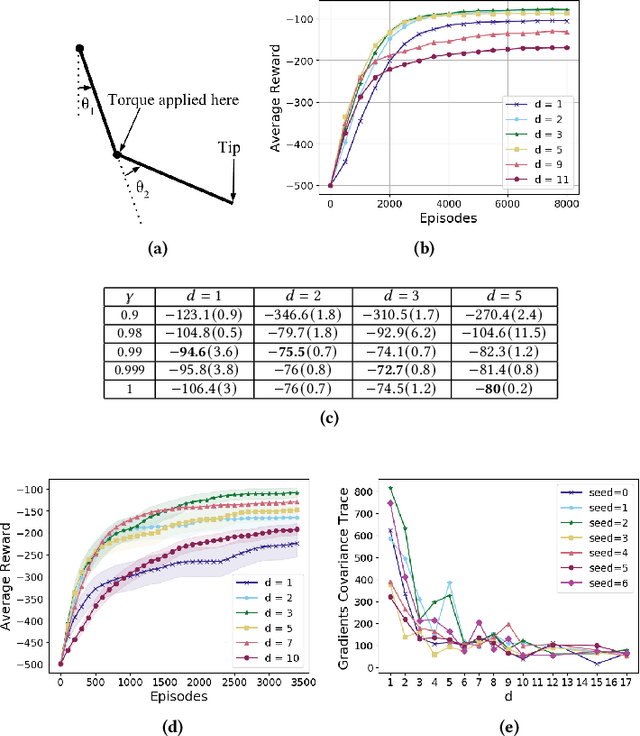
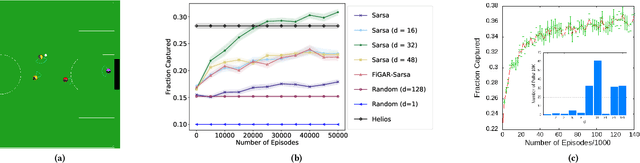
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.