 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies
Mar 12, 2026Vision-Language-Action (VLA) models have significant potential to enable general-purpose robotic systems for a range of vision-language tasks. However, the performance of VLA-based robots is highly sensitive to the precise wording of language instructions, and it remains difficult to predict when such robots will fail. To improve the robustness of VLAs to different wordings, we present Q-DIG (Quality Diversity for Diverse Instruction Generation), which performs red-teaming by scalably identifying diverse natural language task descriptions that induce failures while remaining task-relevant. Q-DIG integrates Quality Diversity (QD) techniques with Vision-Language Models (VLMs) to generate a broad spectrum of adversarial instructions that expose meaningful vulnerabilities in VLA behavior. Our results across multiple simulation benchmarks show that Q-DIG finds more diverse and meaningful failure modes compared to baseline methods, and that fine-tuning VLAs on the generated instructions improves task success rates. Furthermore, results from a user study highlight that Q-DIG generates prompts judged to be more natural and human-like than those from baselines. Finally, real-world evaluations of Q-DIG prompts show results consistent with simulation, and fine-tuning VLAs on the generated prompts further success rates on unseen instructions. Together, these findings suggest that Q-DIG is a promising approach for identifying vulnerabilities and improving the robustness of VLA-based robots. Our anonymous project website is at qdigvla.github.io.
Algorithmic Prompt Generation for Diverse Human-like Teaming and Communication with Large Language Models
Apr 04, 2025



Understanding how humans collaborate and communicate in teams is essential for improving human-agent teaming and AI-assisted decision-making. However, relying solely on data from large-scale user studies is impractical due to logistical, ethical, and practical constraints, necessitating synthetic models of multiple diverse human behaviors. Recently, agents powered by Large Language Models (LLMs) have been shown to emulate human-like behavior in social settings. But, obtaining a large set of diverse behaviors requires manual effort in the form of designing prompts. On the other hand, Quality Diversity (QD) optimization has been shown to be capable of generating diverse Reinforcement Learning (RL) agent behavior. In this work, we combine QD optimization with LLM-powered agents to iteratively search for prompts that generate diverse team behavior in a long-horizon, multi-step collaborative environment. We first show, through a human-subjects experiment (n=54 participants), that humans exhibit diverse coordination and communication behavior in this domain. We then show that our approach can effectively replicate trends from human teaming data and also capture behaviors that are not easily observed without collecting large amounts of data. Our findings highlight the combination of QD and LLM-powered agents as an effective tool for studying teaming and communication strategies in multi-agent collaboration.
Guidance Graph Optimization for Lifelong Multi-Agent Path Finding
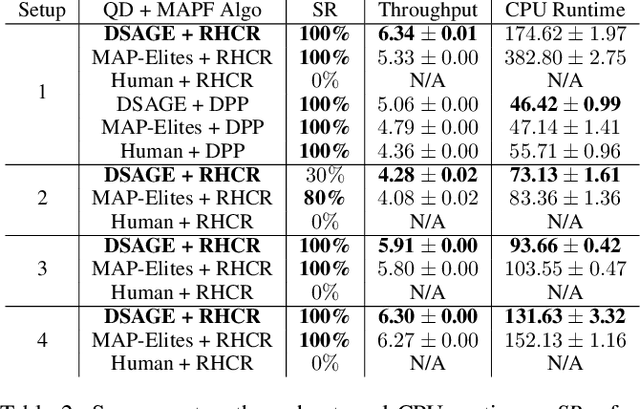
Feb 02, 2024We study how to use guidance to improve the throughput of lifelong Multi-Agent Path Finding (MAPF). Previous studies have demonstrated that while incorporating guidance, such as highways, can accelerate MAPF algorithms, this often results in a trade-off with solution quality. In addition, how to generate good guidance automatically remains largely unexplored, with current methods falling short of surpassing manually designed ones. In this work, we introduce the directed guidance graph as a versatile representation of guidance for lifelong MAPF, framing Guidance Graph Optimization (GGO) as the task of optimizing its edge weights. We present two GGO algorithms to automatically generate guidance for arbitrary lifelong MAPF algorithms and maps. The first method directly solves GGO by employing CMA-ES, a black-box optimization algorithm. The second method, PIU, optimizes an update model capable of generating guidance, demonstrating the ability to transfer optimized guidance graphs to larger maps with similar layouts. Empirically, we show that (1) our guidance graphs improve the throughput of three representative lifelong MAPF algorithms in four benchmark maps, and (2) our update model can generate guidance graphs for as large as $93 \times 91$ maps and as many as 3000 agents.
Arbitrarily Scalable Environment Generators via Neural Cellular Automata
Oct 28, 2023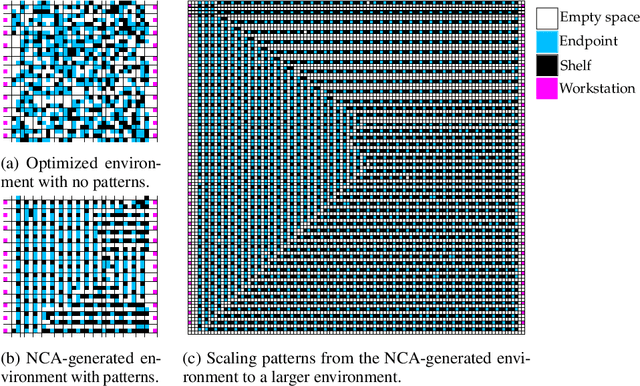

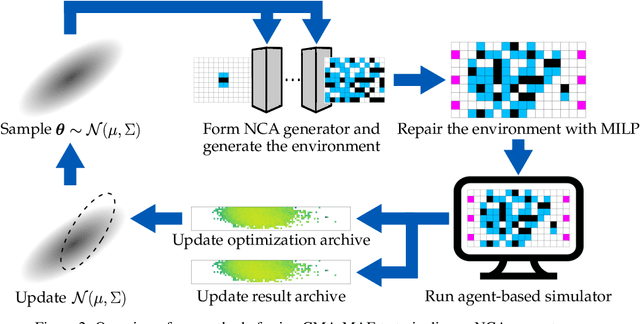
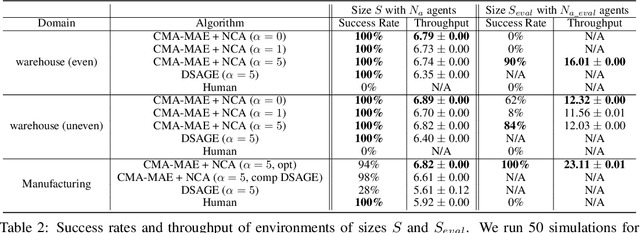
We study the problem of generating arbitrarily large environments to improve the throughput of multi-robot systems. Prior work proposes Quality Diversity (QD) algorithms as an effective method for optimizing the environments of automated warehouses. However, these approaches optimize only relatively small environments, falling short when it comes to replicating real-world warehouse sizes. The challenge arises from the exponential increase in the search space as the environment size increases. Additionally, the previous methods have only been tested with up to 350 robots in simulations, while practical warehouses could host thousands of robots. In this paper, instead of optimizing environments, we propose to optimize Neural Cellular Automata (NCA) environment generators via QD algorithms. We train a collection of NCA generators with QD algorithms in small environments and then generate arbitrarily large environments from the generators at test time. We show that NCA environment generators maintain consistent, regularized patterns regardless of environment size, significantly enhancing the scalability of multi-robot systems in two different domains with up to 2,350 robots. Additionally, we demonstrate that our method scales a single-agent reinforcement learning policy to arbitrarily large environments with similar patterns. We include the source code at \url{https://github.com/lunjohnzhang/warehouse_env_gen_nca_public}.
Multi-Robot Coordination and Layout Design for Automated Warehousing
May 12, 2023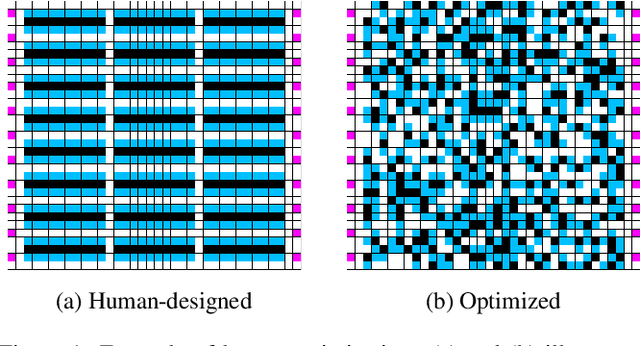

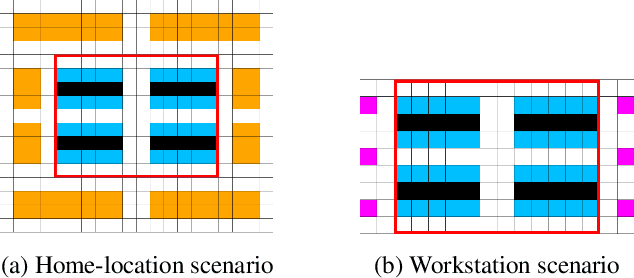
With the rapid progress in Multi-Agent Path Finding (MAPF), researchers have studied how MAPF algorithms can be deployed to coordinate hundreds of robots in large automated warehouses. While most works try to improve the throughput of such warehouses by developing better MAPF algorithms, we focus on improving the throughput by optimizing the warehouse layout. We show that, even with state-of-the-art MAPF algorithms, commonly used human-designed layouts can lead to congestion for warehouses with large numbers of robots and thus have limited scalability. We extend existing automatic scenario generation methods to optimize warehouse layouts. Results show that our optimized warehouse layouts (1) reduce traffic congestion and thus improve throughput, (2) improve the scalability of the automated warehouses by doubling the number of robots in some cases, and (3) are capable of generating layouts with user-specified diversity measures. We include the source code at: https://github.com/lunjohnzhang/warehouse_env_gen_public
Surrogate Assisted Generation of Human-Robot Interaction Scenarios
May 11, 2023



As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
Deep Surrogate Assisted Generation of Environments
Jun 14, 2022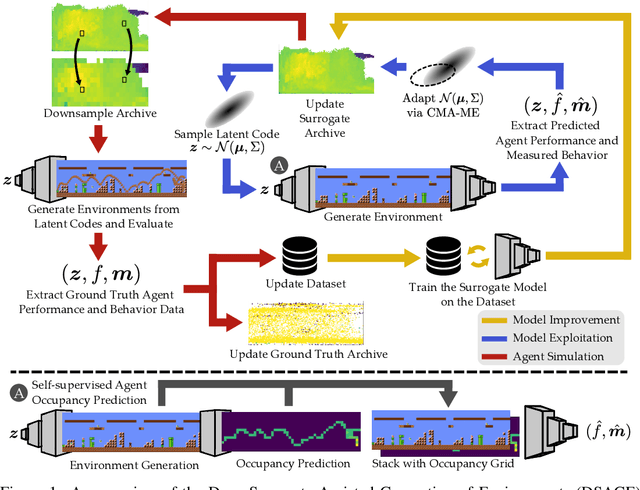
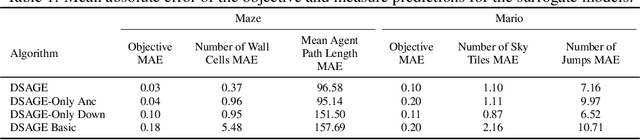
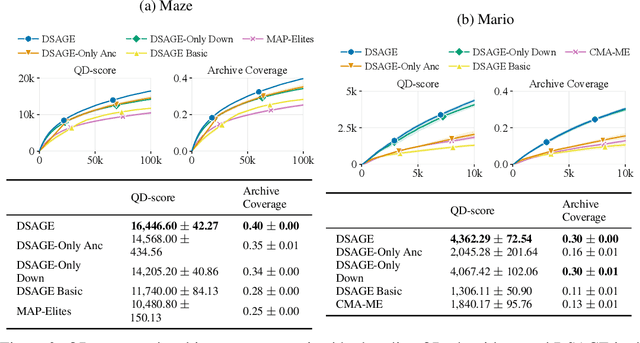

Recent progress in reinforcement learning (RL) has started producing generally capable agents that can solve a distribution of complex environments. These agents are typically tested on fixed, human-authored environments. On the other hand, quality diversity (QD) optimization has been proven to be an effective component of environment generation algorithms, which can generate collections of high-quality environments that are diverse in the resulting agent behaviors. However, these algorithms require potentially expensive simulations of agents on newly generated environments. We propose Deep Surrogate Assisted Generation of Environments (DSAGE), a sample-efficient QD environment generation algorithm that maintains a deep surrogate model for predicting agent behaviors in new environments. Results in two benchmark domains show that DSAGE significantly outperforms existing QD environment generation algorithms in discovering collections of environments that elicit diverse behaviors of a state-of-the-art RL agent and a planning agent.
Inference-Based Deterministic Messaging For Multi-Agent Communication
Mar 03, 2021
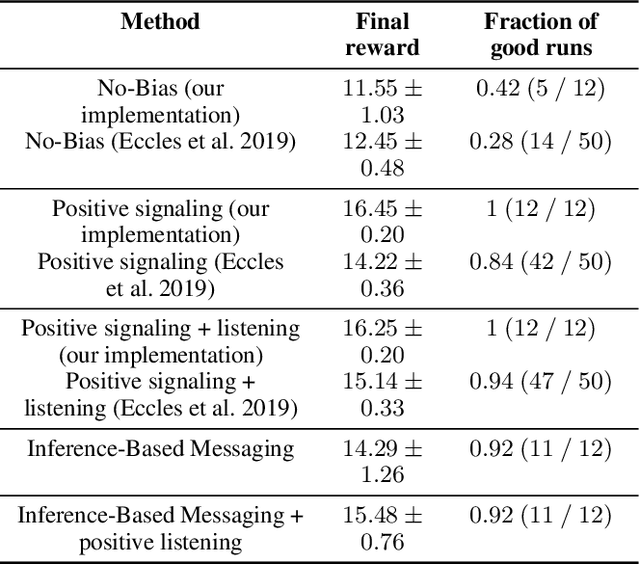
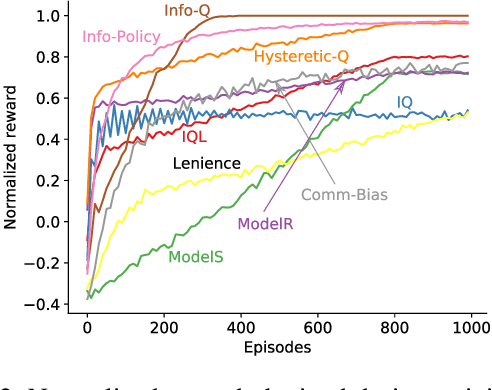
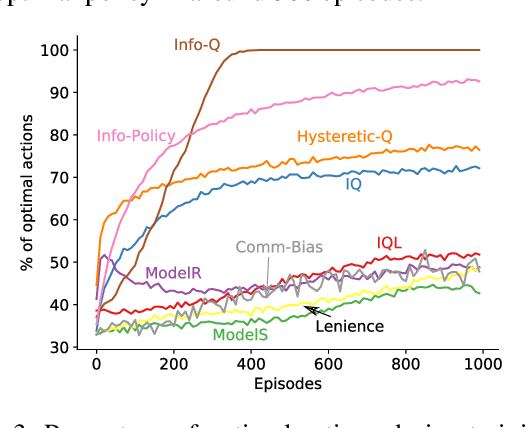
Communication is essential for coordination among humans and animals. Therefore, with the introduction of intelligent agents into the world, agent-to-agent and agent-to-human communication becomes necessary. In this paper, we first study learning in matrix-based signaling games to empirically show that decentralized methods can converge to a suboptimal policy. We then propose a modification to the messaging policy, in which the sender deterministically chooses the best message that helps the receiver to infer the sender's observation. Using this modification, we see, empirically, that the agents converge to the optimal policy in nearly all the runs. We then apply this method to a partially observable gridworld environment which requires cooperation between two agents and show that, with appropriate approximation methods, the proposed sender modification can enhance existing decentralized training methods for more complex domains as well.
An Analysis of Frame-skipping in Reinforcement Learning
Feb 07, 2021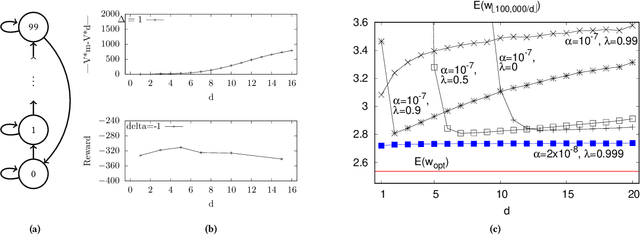
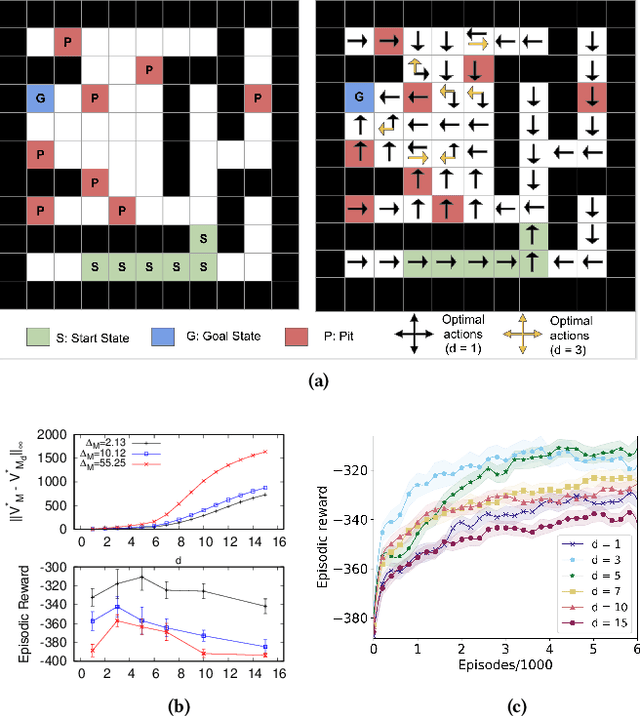
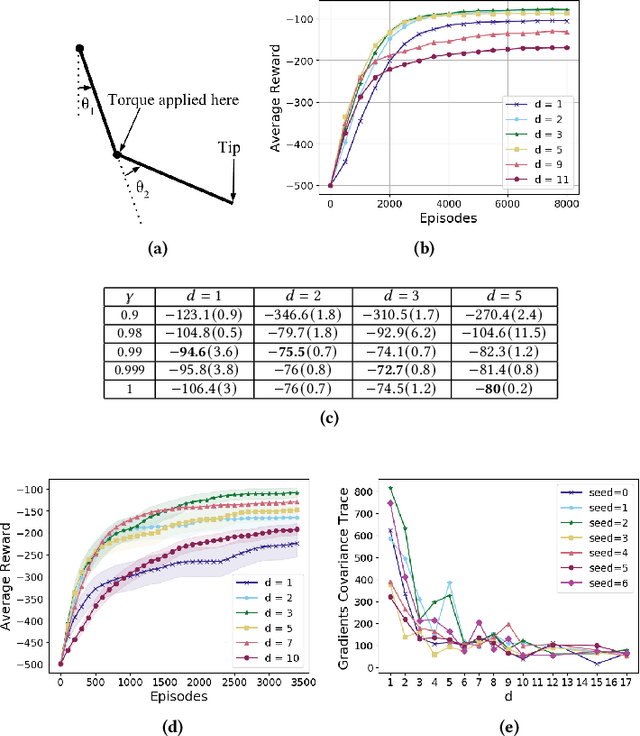
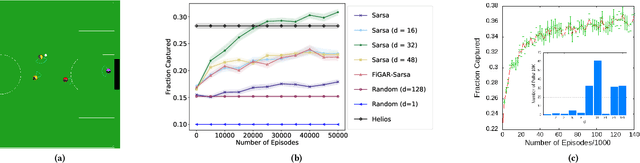
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.