 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSRank: Learning Relevance from Representational Shifts
Jun 16, 2026As enterprises deploy RAG-based systems to provide grounded responses to user queries, reranking has become a critical component for the final filtering step that separates relevant from distracting or irrelevant documents. Existing rerankers often rely on heuristic thresholds to achieve optimal filtering. Moreover, for relevance scoring, state-of-the-art methods use a language model's logit signals, which are designed for next-token prediction, not for assessing relevance. To address these limitations, we identify a principled signal for relevance: the representational shift (RS) induced in a query's internal state when conditioned on a document. We observe that the alignment between (a) RS induced by a candidate document and (b) RS induced by an oracle document-set provides a robust indicator of relevance. Building on this insight, we introduce a lightweight training framework that learns projections mapping RS to calibrated relevance scores. Our training objectives naturally filter irrelevant content at a zero threshold, reducing dependence on heuristic tuning. Across diverse retrieval datasets, our method delivers gains over SOTA rerankers.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Virtual Traffic Lights for Multi-Robot Navigation: Decentralized Planning with Centralized Conflict Resolution
Nov 11, 2025We present a hybrid multi-robot coordination framework that combines decentralized path planning with centralized conflict resolution. In our approach, each robot autonomously plans its path and shares this information with a centralized node. The centralized system detects potential conflicts and allows only one of the conflicting robots to proceed at a time, instructing others to stop outside the conflicting area to avoid deadlocks. Unlike traditional centralized planning methods, our system does not dictate robot paths but instead provides stop commands, functioning as a virtual traffic light. In simulation experiments with multiple robots, our approach increased the success rate of robots reaching their goals while reducing deadlocks. Furthermore, we successfully validated the system in real-world experiments with two quadruped robots and separately with wheeled Duckiebots.
Fibonacci-Net: A Lightweight CNN model for Automatic Brain Tumor Classification
Mar 18, 2025This research proposes a very lightweight model "Fibonacci-Net" along with a novel pooling technique, for automatic brain tumor classification from imbalanced Magnetic Resonance Imaging (MRI) datasets. Automatic brain tumor detection from MRI dataset has garnered significant attention in the research community, since the inception of Convolutional Neural Network (CNN) models. However, the performance of conventional CNN models is hindered due to class imbalance problems. The novelties of this work are as follows: (I) A lightweight CNN model is proposed in which the number of filters in different convolutional layers is chosen according to the numbers of Fibonacci series. (II) In the last two blocks of the proposed model, depth-wise separable convolution (DWSC) layers are employed to considerably reduce the computational complexity of the model. (III) Two parallel concatenations (or, skip connections) are deployed from 2nd to 4th, and 3rd to 5th convolutional block in the proposed Fibonacci-Net. This skip connection encompasses a novel Average-2Max pooling layer that produces two stacks of convoluted output, having a bit different statistics. Therefore, this parallel concatenation block works as an efficient feature augmenter inside the model, thus, automatically alleviating the class imbalance problem to a certain extent. For validity purpose, we have implemented the proposed framework on three MRI datasets which are highly class-imbalanced. (a) The first dataset has four classes, i.e., glioma tumor, meningioma tumor, pituitary tumor, and no-tumor. (b) Second and third MRI datasets have 15 and 44 classes respectively. Experimental results reveal that, after employing the proposed Fibonacci-Net we have achieved 96.2% accuracy, 97.17% precision, 95.9% recall, 96.5% F1 score, and 99.9% specificity on the most challenging ``44-classes MRI dataset''.
Edge Attention Module for Object Classification
Feb 05, 2025A novel ``edge attention-based Convolutional Neural Network (CNN)'' is proposed in this research for object classification task. With the advent of advanced computing technology, CNN models have achieved to remarkable success, particularly in computer vision applications. Nevertheless, the efficacy of the conventional CNN is often hindered due to class imbalance and inter-class similarity problems, which are particularly prominent in the computer vision field. In this research, we introduce for the first time an ``Edge Attention Module (EAM)'' consisting of a Max-Min pooling layer, followed by convolutional layers. This Max-Min pooling is entirely a novel pooling technique, specifically designed to capture only the edge information that is crucial for any object classification task. Therefore, by integrating this novel pooling technique into the attention module, the CNN network inherently prioritizes on essential edge features, thereby boosting the accuracy and F1-score of the model significantly. We have implemented our proposed EAM or 2EAMs on several standard pre-trained CNN models for Caltech-101, Caltech-256, CIFAR-100 and Tiny ImageNet-200 datasets. The extensive experiments reveal that our proposed framework (that is, EAM with CNN and 2EAMs with CNN), outperforms all pre-trained CNN models as well as recent trend models ``Pooling-based Vision Transformer (PiT)'', ``Convolutional Block Attention Module (CBAM)'', and ConvNext, by substantial margins. We have achieved the accuracy of 95.5% and 86% by the proposed framework on Caltech-101 and Caltech-256 datasets, respectively. So far, this is the best results on these datasets, to the best of our knowledge.
AD-Lite Net: A Lightweight and Concatenated CNN Model for Alzheimer's Detection from MRI Images
Sep 12, 2024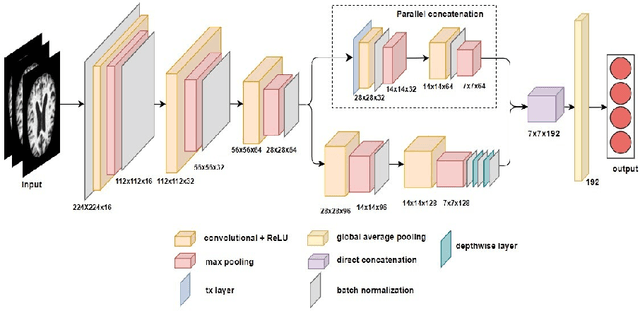
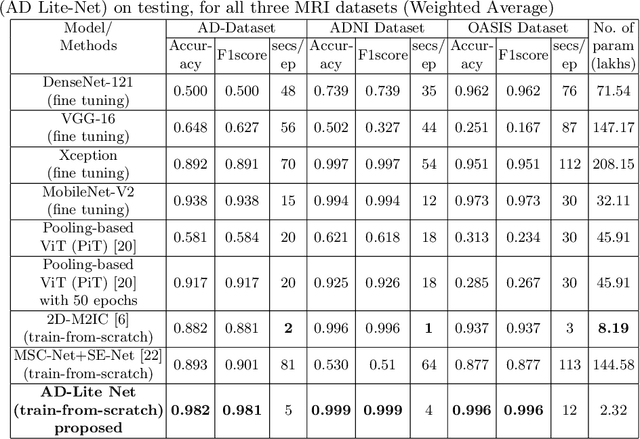


Alzheimer's Disease (AD) is a non-curable progressive neurodegenerative disorder that affects the human brain, leading to a decline in memory, cognitive abilities, and eventually, the ability to carry out daily tasks. Manual diagnosis of Alzheimer's disease from MRI images is fraught with less sensitivity and it is a very tedious process for neurologists. Therefore, there is a need for an automatic Computer Assisted Diagnosis (CAD) system, which can detect AD at early stages with higher accuracy. In this research, we have proposed a novel AD-Lite Net model (trained from scratch), that could alleviate the aforementioned problem. The novelties we bring here in this research are, (I) We have proposed a very lightweight CNN model by incorporating Depth Wise Separable Convolutional (DWSC) layers and Global Average Pooling (GAP) layers. (II) We have leveraged a ``parallel concatenation block'' (pcb), in the proposed AD-Lite Net model. This pcb consists of a Transformation layer (Tx-layer), followed by two convolutional layers, which are thereby concatenated with the original base model. This Tx-layer converts the features into very distinct kind of features, which are imperative for the Alzheimer's disease. As a consequence, the proposed AD-Lite Net model with ``parallel concatenation'' converges faster and automatically mitigates the class imbalance problem from the MRI datasets in a very generalized way. For the validity of our proposed model, we have implemented it on three different MRI datasets. Furthermore, we have combined the ADNI and AD datasets and subsequently performed a 10-fold cross-validation experiment to verify the model's generalization ability. Extensive experimental results showed that our proposed model has outperformed all the existing CNN models, and one recent trend Vision Transformer (ViT) model by a significant margin.
A Machine Learning Approach to Predicting Single Event Upsets
Oct 09, 2023A single event upset (SEU) is a critical soft error that occurs in semiconductor devices on exposure to ionising particles from space environments. SEUs cause bit flips in the memory component of semiconductors. This creates a multitude of safety hazards as stored information becomes less reliable. Currently, SEUs are only detected several hours after their occurrence. CREMER, the model presented in this paper, predicts SEUs in advance using machine learning. CREMER uses only positional data to predict SEU occurrence, making it robust, inexpensive and scalable. Upon implementation, the improved reliability of memory devices will create a digitally safer environment onboard space vehicles.
A Low-Cost Lane-Following Algorithm for Cyber-Physical Robots
Aug 23, 2022
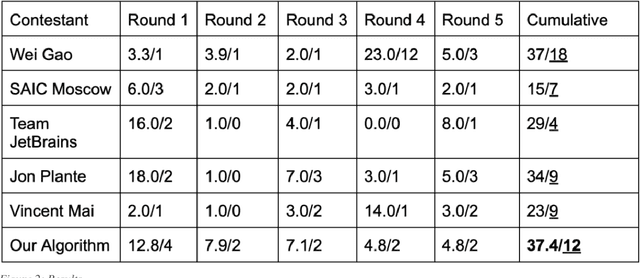
Duckiebots are low-cost mobile robots that are widely used in the fields of research and education. Although there are existing self-driving algorithms for the Duckietown platform, they are either too complex or perform too poorly to navigate a multi-lane track. Moreover, it is essential to give memory and computational resources to a Duckiebot so it can perform additional tasks such as out-of-distribution input detection. In order to satisfy these constraints, we built a low-cost autonomous driving algorithm capable of driving on a two-lane track. The algorithm uses traditional computer vision techniques to identify the central lane on the track and obtain the relevant steering angle. The steering is then controlled by a PID controller that smoothens the movement of the Duckiebot. The performance of the algorithm was compared to that of the NeurIPS 2018 AI Driving Olympics (AIDO) finalists, and it outperformed all but one finalists. The two main contributions of our algorithm are its low computational requirements and very quick set-up, with ongoing efforts to make it more reliable.
An Analysis of Frame-skipping in Reinforcement Learning
Feb 07, 2021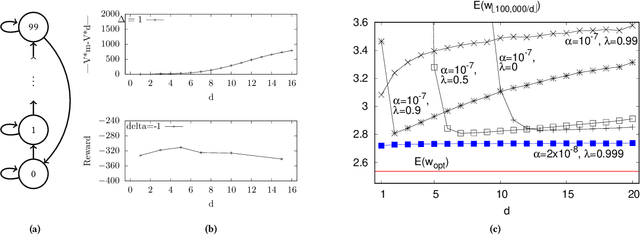
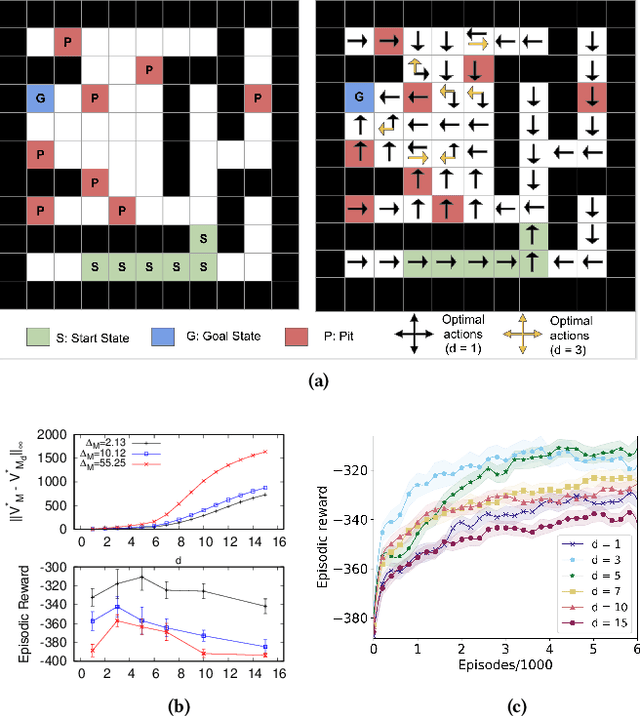
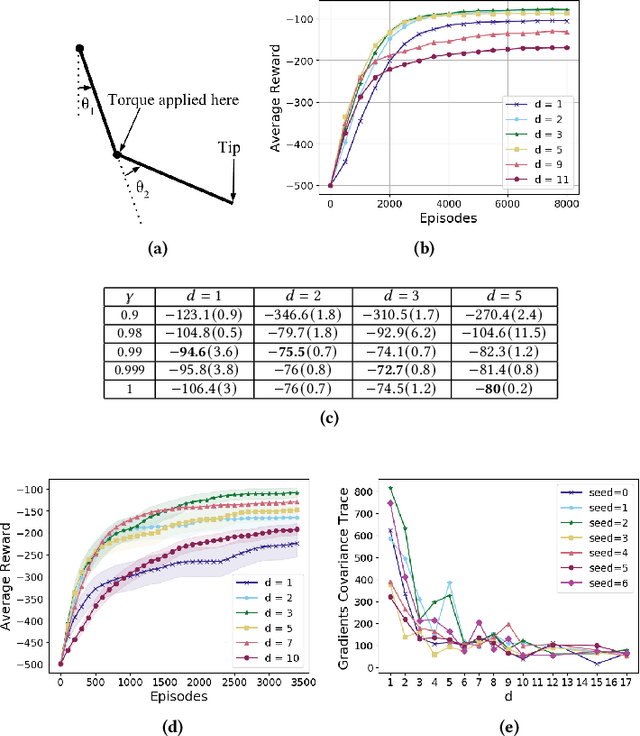
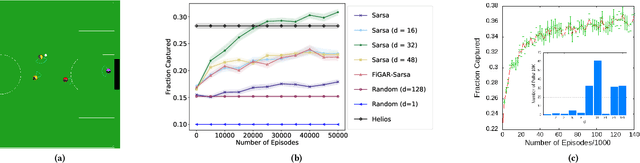
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.
Emotion Detection using Image Processing in Python
Dec 01, 2020

In this work, user's emotion using its facial expressions will be detected. These expressions can be derived from the live feed via system's camera or any pre-exisiting image available in the memory. Emotions possessed by humans can be recognized and has a vast scope of study in the computer vision industry upon which several researches have already been done. The work has been implemented using Python (2.7, Open Source Computer Vision Library (OpenCV) and NumPy. The scanned image(testing dataset) is being compared to the training dataset and thus emotion is predicted. The objective of this paper is to develop a system which can analyze the image and predict the expression of the person. The study proves that this procedure is workable and produces valid results.