 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Guidance via Robust Feature Attribution
Jun 24, 2025Controlling the patterns a model learns is essential to preventing reliance on irrelevant or misleading features. Such reliance on irrelevant features, often called shortcut features, has been observed across domains, including medical imaging and natural language processing, where it may lead to real-world harms. A common mitigation strategy leverages annotations (provided by humans or machines) indicating which features are relevant or irrelevant. These annotations are compared to model explanations, typically in the form of feature salience, and used to guide the loss function during training. Unfortunately, recent works have demonstrated that feature salience methods are unreliable and therefore offer a poor signal to optimize. In this work, we propose a simplified objective that simultaneously optimizes for explanation robustness and mitigation of shortcut learning. Unlike prior objectives with similar aims, we demonstrate theoretically why our approach ought to be more effective. Across a comprehensive series of experiments, we show that our approach consistently reduces test-time misclassifications by 20% compared to state-of-the-art methods. We also extend prior experimental settings to include natural language processing tasks. Additionally, we conduct novel ablations that yield practical insights, including the relative importance of annotation quality over quantity. Code for our method and experiments is available at: https://github.com/Mihneaghitu/ModelGuidanceViaRobustFeatureAttribution.
Estimation of Concept Explanations Should be Uncertainty Aware
Dec 13, 2023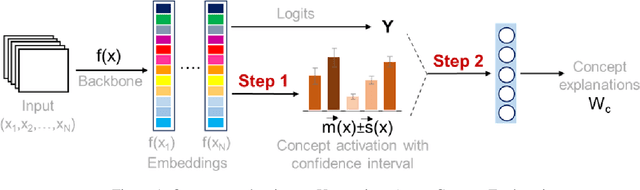
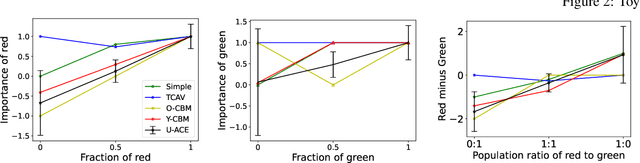
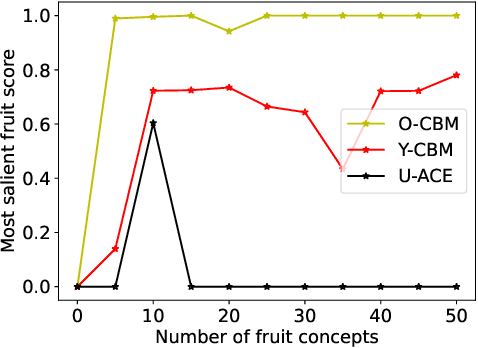

Model explanations are very valuable for interpreting and debugging prediction models. We study a specific kind of global explanations called Concept Explanations, where the goal is to interpret a model using human-understandable concepts. Recent advances in multi-modal learning rekindled interest in concept explanations and led to several label-efficient proposals for estimation. However, existing estimation methods are unstable to the choice of concepts or dataset that is used for computing explanations. We observe that instability in explanations is due to high variance in point estimation of importance scores. We propose an uncertainty aware Bayesian estimation method, which readily improved reliability of the concept explanations. We demonstrate with theoretical analysis and empirical evaluation that explanations computed by our method are more reliable while also being label-efficient and faithful.
Robust Learning from Explanations
Mar 11, 2023Machine learning from explanations (MLX) is an approach to learning that uses human-provided annotations of relevant features for each input to ensure that model predictions are right for the right reasons. Existing MLX approaches rely heavily on a specific model interpretation approach and require strong parameter regularization to align model and human explanations, leading to sub-optimal performance. We recast MLX as an adversarial robustness problem, where human explanations specify a lower dimensional manifold from which perturbations can be drawn, and show both theoretically and empirically how this approach alleviates the need for strong parameter regularization. We consider various approaches to achieving robustness, leading to improved performance over prior MLX methods. Finally, we combine robustness with an earlier MLX method, yielding state-of-the-art results on both synthetic and real-world benchmarks.
Robustness, Evaluation and Adaptation of Machine Learning Models in the Wild
Mar 05, 2023

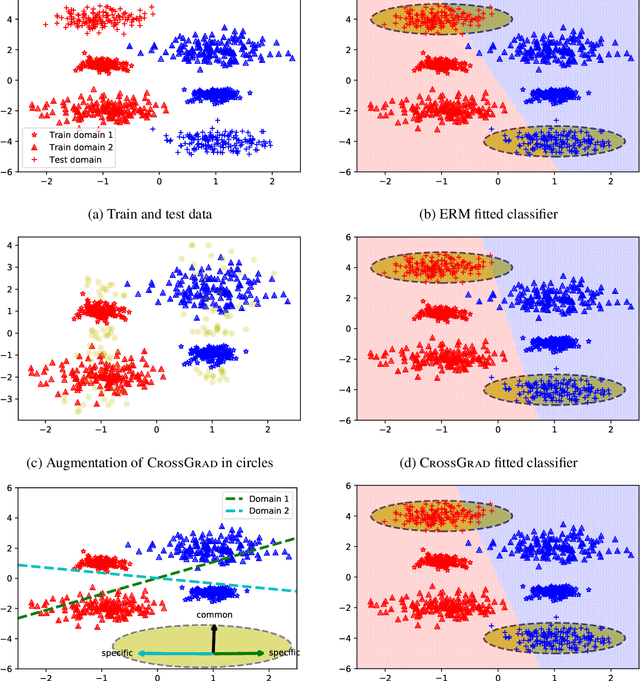
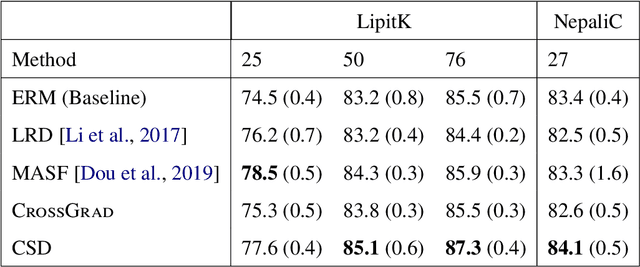
Our goal is to improve reliability of Machine Learning (ML) systems deployed in the wild. ML models perform exceedingly well when test examples are similar to train examples. However, real-world applications are required to perform on any distribution of test examples. Current ML systems can fail silently on test examples with distribution shifts. In order to improve reliability of ML models due to covariate or domain shift, we propose algorithms that enable models to: (a) generalize to a larger family of test distributions, (b) evaluate accuracy under distribution shifts, (c) adapt to a target distribution. We study causes of impaired robustness to domain shifts and present algorithms for training domain robust models. A key source of model brittleness is due to domain overfitting, which our new training algorithms suppress and instead encourage domain-general hypotheses. While we improve robustness over standard training methods for certain problem settings, performance of ML systems can still vary drastically with domain shifts. It is crucial for developers and stakeholders to understand model vulnerabilities and operational ranges of input, which could be assessed on the fly during the deployment, albeit at a great cost. Instead, we advocate for proactively estimating accuracy surfaces over any combination of prespecified and interpretable domain shifts for performance forecasting. We present a label-efficient estimation to address estimation over a combinatorial space of domain shifts. Further, when a model's performance on a target domain is found to be poor, traditional approaches adapt the model using the target domain's resources. Standard adaptation methods assume access to sufficient labeled resources, which may be impractical for deployed models. We initiate a study of lightweight adaptation techniques with only unlabeled data resources with a focus on language applications.
Implicit Training of Energy Model for Structure Prediction
Nov 21, 2022Most deep learning research has focused on developing new model and training procedures. On the other hand the training objective has usually been restricted to combinations of standard losses. When the objective aligns well with the evaluation metric, this is not a major issue. However when dealing with complex structured outputs, the ideal objective can be hard to optimize and the efficacy of usual objectives as a proxy for the true objective can be questionable. In this work, we argue that the existing inference network based structure prediction methods ( Tu and Gimpel 2018; Tu, Pang, and Gimpel 2020) are indirectly learning to optimize a dynamic loss objective parameterized by the energy model. We then explore using implicit-gradient based technique to learn the corresponding dynamic objectives. Our experiments show that implicitly learning a dynamic loss landscape is an effective method for improving model performance in structure prediction.
Web-based Elicitation of Human Perception on mixup Data
Nov 02, 2022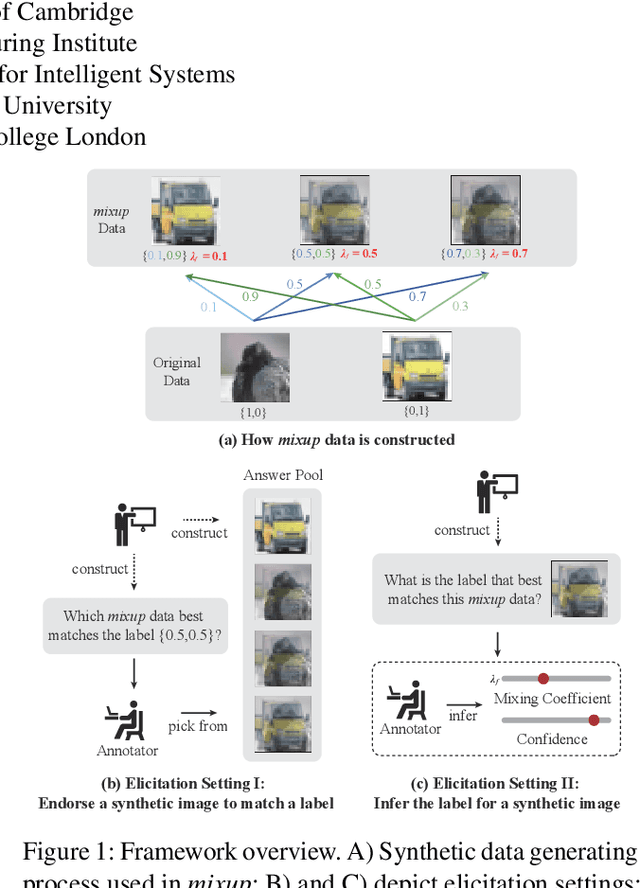
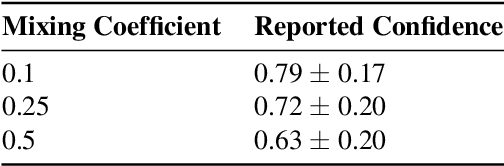
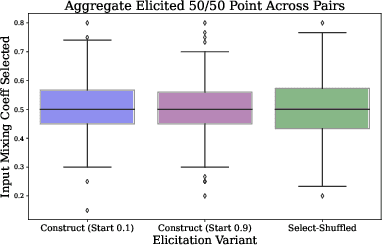
Synthetic data is proliferating on the web and powering many advances in machine learning. However, it is not always clear if synthetic labels are perceptually sensible to humans. The web provides us with a platform to take a step towards addressing this question through online elicitation. We design a series of elicitation interfaces, which we release as \texttt{HILL MixE Suite}, and recruit 159 participants, to provide perceptual judgments over the kinds of synthetic data constructed during \textit{mixup} training: a powerful regularizer shown to improve model robustness, generalization, and calibration. We find that human perception does not consistently align with the labels traditionally used for synthetic points and begin to demonstrate the applicability of these findings to potentially increase the reliability of downstream models. We release all elicited judgments in a new data hub we call \texttt{H-Mix}.
Focus on the Common Good: Group Distributional Robustness Follows
Oct 06, 2021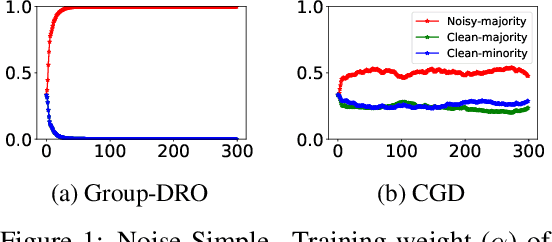


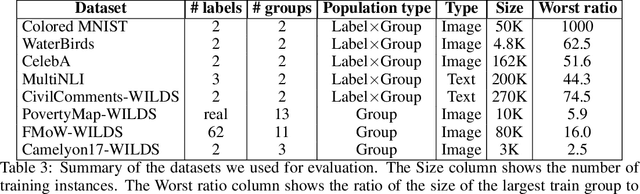
We consider the problem of training a classification model with group annotated training data. Recent work has established that, if there is distribution shift across different groups, models trained using the standard empirical risk minimization (ERM) objective suffer from poor performance on minority groups and that group distributionally robust optimization (Group-DRO) objective is a better alternative. The starting point of this paper is the observation that though Group-DRO performs better than ERM on minority groups for some benchmark datasets, there are several other datasets where it performs much worse than ERM. Inspired by ideas from the closely related problem of domain generalization, this paper proposes a new and simple algorithm that explicitly encourages learning of features that are shared across various groups. The key insight behind our proposed algorithm is that while Group-DRO focuses on groups with worst regularized loss, focusing instead, on groups that enable better performance even on other groups, could lead to learning of shared/common features, thereby enhancing minority performance beyond what is achieved by Group-DRO. Empirically, we show that our proposed algorithm matches or achieves better performance compared to strong contemporary baselines including ERM and Group-DRO on standard benchmarks on both minority groups and across all groups. Theoretically, we show that the proposed algorithm is a descent method and finds first order stationary points of smooth nonconvex functions.
Training for the Future: A Simple Gradient Interpolation Loss to Generalize Along Time
Aug 15, 2021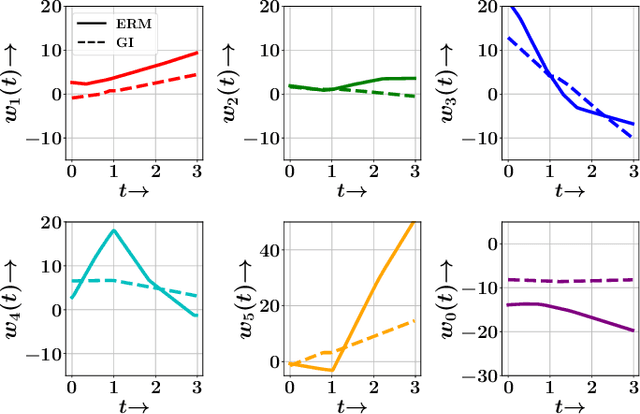
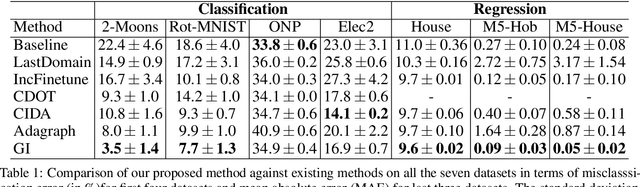
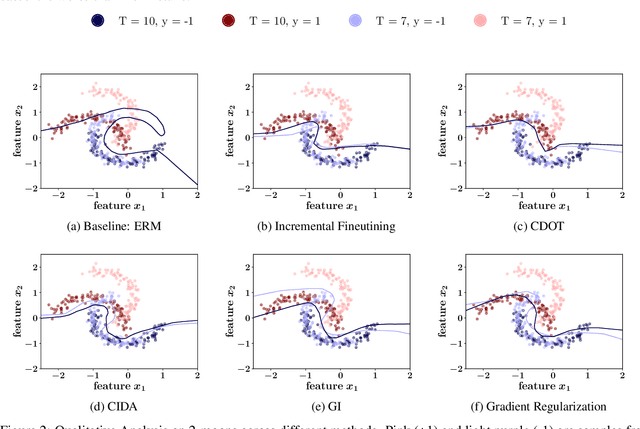
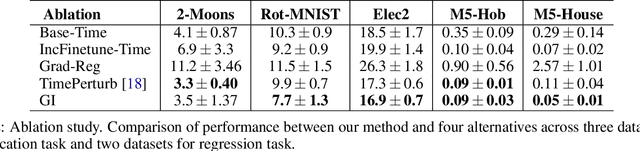
In several real world applications, machine learning models are deployed to make predictions on data whose distribution changes gradually along time, leading to a drift between the train and test distributions. Such models are often re-trained on new data periodically, and they hence need to generalize to data not too far into the future. In this context, there is much prior work on enhancing temporal generalization, e.g. continuous transportation of past data, kernel smoothed time-sensitive parameters and more recently, adversarial learning of time-invariant features. However, these methods share several limitations, e.g, poor scalability, training instability, and dependence on unlabeled data from the future. Responding to the above limitations, we propose a simple method that starts with a model with time-sensitive parameters but regularizes its temporal complexity using a Gradient Interpolation (GI) loss. GI allows the decision boundary to change along time and can still prevent overfitting to the limited training time snapshots by allowing task-specific control over changes along time. We compare our method to existing baselines on multiple real-world datasets, which show that GI outperforms more complicated generative and adversarial approaches on the one hand, and simpler gradient regularization methods on the other.
Active Assessment of Prediction Services as Accuracy Surface Over Attribute Combinations
Aug 14, 2021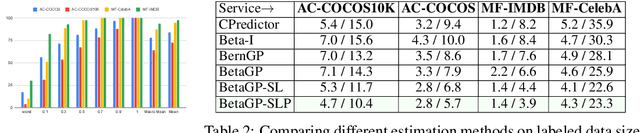



Our goal is to evaluate the accuracy of a black-box classification model, not as a single aggregate on a given test data distribution, but as a surface over a large number of combinations of attributes characterizing multiple test data distributions. Such attributed accuracy measures become important as machine learning models get deployed as a service, where the training data distribution is hidden from clients, and different clients may be interested in diverse regions of the data distribution. We present Attributed Accuracy Assay (AAA)--a Gaussian Process (GP)--based probabilistic estimator for such an accuracy surface. Each attribute combination, called an 'arm', is associated with a Beta density from which the service's accuracy is sampled. We expect the GP to smooth the parameters of the Beta density over related arms to mitigate sparsity. We show that obvious application of GPs cannot address the challenge of heteroscedastic uncertainty over a huge attribute space that is sparsely and unevenly populated. In response, we present two enhancements: pooling sparse observations, and regularizing the scale parameter of the Beta densities. After introducing these innovations, we establish the effectiveness of AAA in terms of both its estimation accuracy and exploration efficiency, through extensive experiments and analysis.
An Analysis of Frame-skipping in Reinforcement Learning
Feb 07, 2021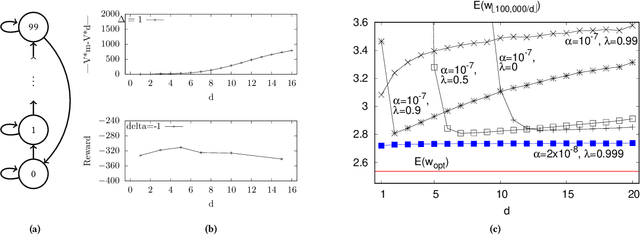
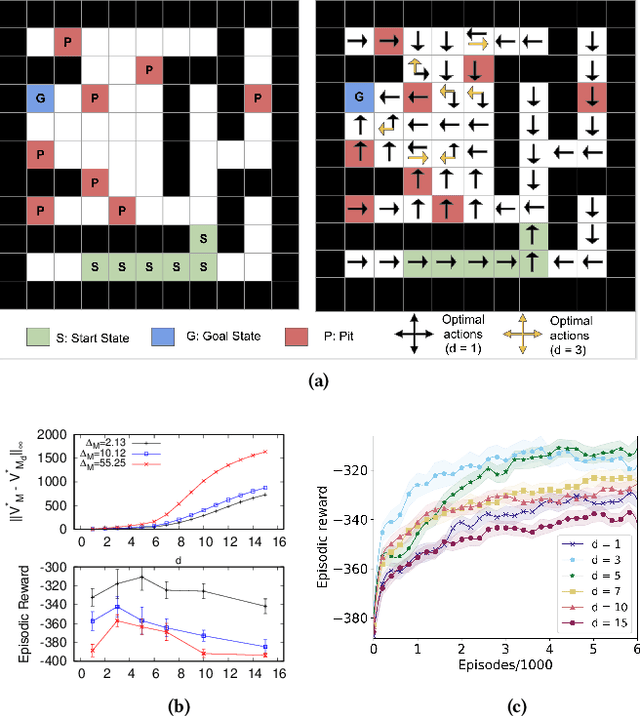
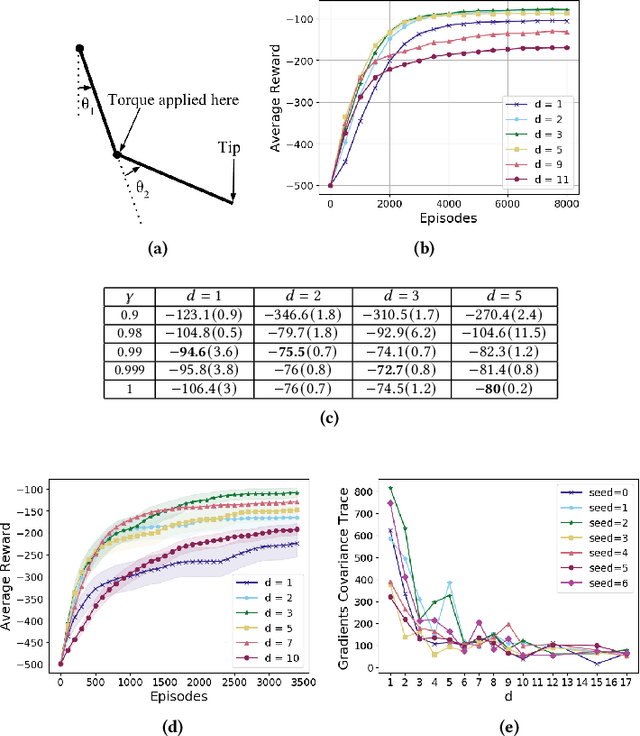
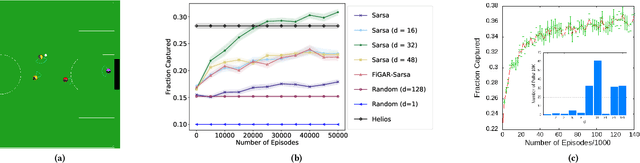
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.