 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing initial human-AI proof formalization workflows
Jun 02, 2026For centuries, human mathematicians have written proofs to substantiate their mathematical arguments; yet, the ability to automatically verify the validity of proofs has long been a challenge. Advances in AI systems' ability to generate code and engage in increasingly high-level mathematical reasoning promise to transform people's ability to formalize and thereby verify proofs. While many works focus on benchmarking the current frontier, we instead study how people use these tools. We conduct a mixed-methods analysis into the initial impact of AI on people's formalization workflows: what people claim they want, what they see as the barriers to those visions, and how they actually use and adapt AI in practice. A qualitative survey shows that people's preferences are diverse, but with a general desire for AI assistance in formalization that preserves high-level human control over the proof discovery process. To assess how people actually engage with AI for formalization under such limitations, we conduct a controlled user study in which participants formalize informal math problems and their proofs, with and without AI, across a range of mathematical problems at varying levels of difficulty and domains. Despite limitations of the tools at the time for autoformalization, participants tend to attain higher formalization accuracy when allowed access to AI tools than when formalizing on their own, with most participants flexibly choosing to use multiple different AI tools. Taken together, our work sheds light on the early stages of AI integration into formalization workflows, involving an intimate interplay of human and AI engagement.
Learning to Orchestrate Agents under Uncertainty
May 26, 2026Adaptive orchestration of heterogeneous agents requires making sequential delegation decisions under uncertain and evolving agent behaviour, e.g., coordinating specialised AI models with varying reliability, cost, and response quality. While prior work on agent orchestration focuses on performance or cost, uncertainty in agent reliability and output distributions is typically not modelled explicitly at the orchestration level. In this work, we study the problem of adaptive orchestration of heterogeneous agents under uncertainty, where a meta-controller must decide when to delegate to an agent, accounting for reliability, cost, and uncertainty. We propose BOT-Orch, a lightweight framework that recasts orchestration as a bandit problem over agents, regularized by OT distances between agent output distributions and task-specific reference distributions. We show that the regularised orchestration enjoys $\mathcal{O}(\sqrt{T})$ regret under standard assumptions, and provably induces preference ordering among agents with identical mean rewards but differing distributional alignment. Empirically, we demonstrate that BOT-Orch outperforms standard bandit and heuristic baselines in synthetic but adversarial task allocation settings with heterogeneous, non-i.i.d. agent behaviour.
RCTs & Human Uplift Studies: Methodological Challenges and Practical Solutions for Frontier AI Evaluation
Mar 11, 2026Human uplift studies - or studies that measure AI effects on human performance relative to a status quo, typically using randomized controlled trial (RCT) methodology - are increasingly used to inform deployment, governance, and safety decisions for frontier AI systems. While the methods underlying these studies are well-established, their interaction with the distinctive properties of frontier AI systems remains underexamined, particularly when results are used to inform high-stakes decisions. We present findings from interviews with 16 expert practitioners with experience conducting human uplift studies in domains including biosecurity, cybersecurity, education, and labor. Across interviews, experts described a recurring tension between standard causal inference assumptions and the object of study itself. Rapidly evolving AI systems, shifting baselines, heterogeneous and changing user proficiency, and porous real-world settings strain assumptions underlying internal, external, and construct validity, complicating the interpretation and appropriate use of uplift evidence. We synthesize these challenges across key stages of the human uplift research lifecycle and map them to practitioner-reported solutions, clarifying both the limits and the appropriate uses of evidence from human uplift studies in high-stakes decision-making.
Belief Offloading in Human-AI Interaction
Feb 09, 2026What happens when people's beliefs are derived from information provided by an LLM? People's use of LLM chatbots as thought partners can contribute to cognitive offloading, which can have adverse effects on cognitive skills in cases of over-reliance. This paper defines and investigates a particular kind of cognitive offloading in human-AI interaction, "belief offloading," in which people's processes of forming and upholding beliefs are offloaded onto an AI system with downstream consequences on their behavior and the nature of their system of beliefs. Drawing on philosophy, psychology, and computer science research, we clarify the boundary conditions under which belief offloading occurs and provide a descriptive taxonomy of belief offloading and its normative implications. We close with directions for future work to assess the potential for and consequences of belief offloading in human-AI interaction.
Unequal Uncertainty: Rethinking Algorithmic Interventions for Mitigating Discrimination from AI
Aug 11, 2025Uncertainty in artificial intelligence (AI) predictions poses urgent legal and ethical challenges for AI-assisted decision-making. We examine two algorithmic interventions that act as guardrails for human-AI collaboration: selective abstention, which withholds high-uncertainty predictions from human decision-makers, and selective friction, which delivers those predictions together with salient warnings or disclosures that slow the decision process. Research has shown that selective abstention based on uncertainty can inadvertently exacerbate disparities and disadvantage under-represented groups that disproportionately receive uncertain predictions. In this paper, we provide the first integrated socio-technical and legal analysis of uncertainty-based algorithmic interventions. Through two case studies, AI-assisted consumer credit decisions and AI-assisted content moderation, we demonstrate how the seemingly neutral use of uncertainty thresholds can trigger discriminatory impacts. We argue that, although both interventions pose risks of unlawful discrimination under UK law, selective frictions offer a promising pathway toward fairer and more accountable AI-assisted decision-making by preserving transparency and encouraging more cautious human judgment.
When Should We Orchestrate Multiple Agents?
Mar 17, 2025Strategies for orchestrating the interactions between multiple agents, both human and artificial, can wildly overestimate performance and underestimate the cost of orchestration. We design a framework to orchestrate agents under realistic conditions, such as inference costs or availability constraints. We show theoretically that orchestration is only effective if there are performance or cost differentials between agents. We then empirically demonstrate how orchestration between multiple agents can be helpful for selecting agents in a simulated environment, picking a learning strategy in the infamous Rogers' Paradox from social science, and outsourcing tasks to other agents during a question-answer task in a user study.
Faster, Cheaper, Better: Multi-Objective Hyperparameter Optimization for LLM and RAG Systems
Feb 25, 2025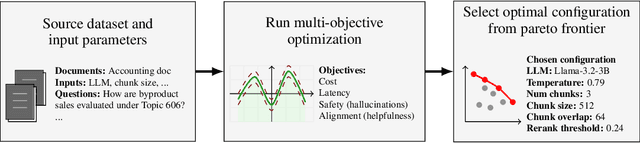



While Retrieval Augmented Generation (RAG) has emerged as a popular technique for improving Large Language Model (LLM) systems, it introduces a large number of choices, parameters and hyperparameters that must be made or tuned. This includes the LLM, embedding, and ranker models themselves, as well as hyperparameters governing individual RAG components. Yet, collectively optimizing the entire configuration in a RAG or LLM system remains under-explored - especially in multi-objective settings - due to intractably large solution spaces, noisy objective evaluations, and the high cost of evaluations. In this work, we introduce the first approach for multi-objective parameter optimization of cost, latency, safety and alignment over entire LLM and RAG systems. We find that Bayesian optimization methods significantly outperform baseline approaches, obtaining a superior Pareto front on two new RAG benchmark tasks. We conclude our work with important considerations for practitioners who are designing multi-objective RAG systems, highlighting nuances such as how optimal configurations may not generalize across tasks and objectives.
Building Machines that Learn and Think with People
Jul 22, 2024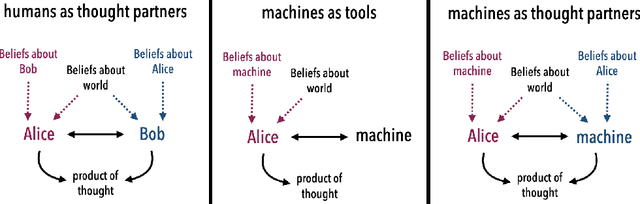
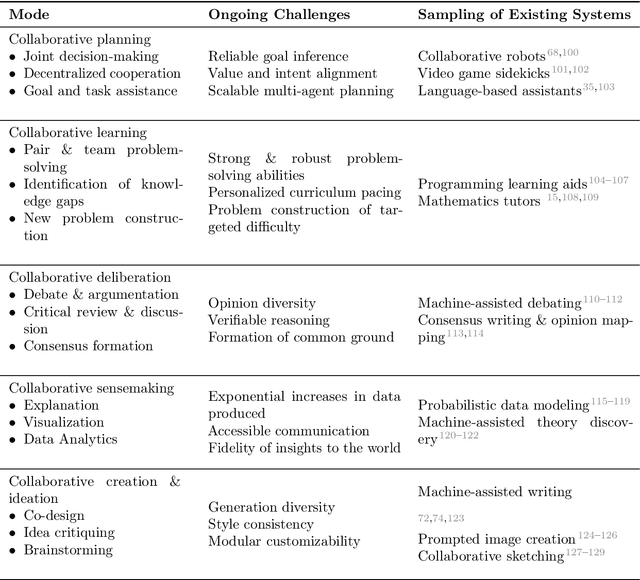
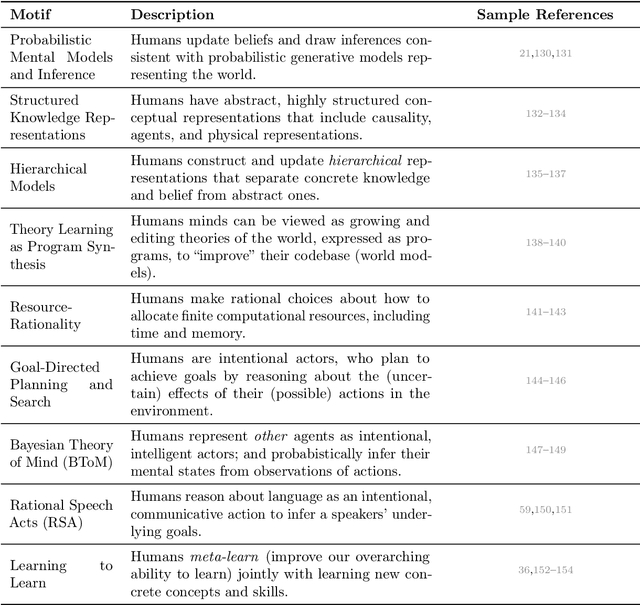
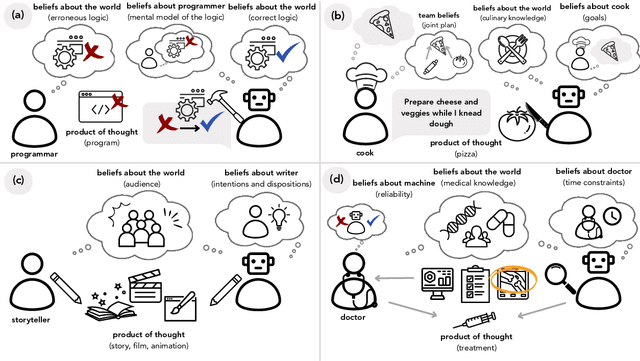
What do we want from machine intelligence? We envision machines that are not just tools for thought, but partners in thought: reasonable, insightful, knowledgeable, reliable, and trustworthy systems that think with us. Current artificial intelligence (AI) systems satisfy some of these criteria, some of the time. In this Perspective, we show how the science of collaborative cognition can be put to work to engineer systems that really can be called ``thought partners,'' systems built to meet our expectations and complement our limitations. We lay out several modes of collaborative thought in which humans and AI thought partners can engage and propose desiderata for human-compatible thought partnerships. Drawing on motifs from computational cognitive science, we motivate an alternative scaling path for the design of thought partners and ecosystems around their use through a Bayesian lens, whereby the partners we construct actively build and reason over models of the human and world.
Large Language Models Must Be Taught to Know What They Don't Know
Jun 12, 2024



When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
Representational Alignment Supports Effective Machine Teaching
Jun 06, 2024



A good teacher should not only be knowledgeable; but should be able to communicate in a way that the student understands -- to share the student's representation of the world. In this work, we integrate insights from machine teaching and pragmatic communication with the burgeoning literature on representational alignment to characterize a utility curve defining a relationship between representational alignment and teacher capability for promoting student learning. To explore the characteristics of this utility curve, we design a supervised learning environment that disentangles representational alignment from teacher accuracy. We conduct extensive computational experiments with machines teaching machines, complemented by a series of experiments in which machines teach humans. Drawing on our findings that improved representational alignment with a student improves student learning outcomes (i.e., task accuracy), we design a classroom matching procedure that assigns students to teachers based on the utility curve. If we are to design effective machine teachers, it is not enough to build teachers that are accurate -- we want teachers that can align, representationally, to their students too.