 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT
Feb 03, 2026To enable personalized and context-aware interactions, conversational AI systems have introduced a new mechanism: Memory. Memory creates what we refer to as the Algorithmic Self-portrait - a new form of personalization derived from users' self-disclosed information divulged within private conversations. While memory enables more coherent exchanges, the underlying processes of memory creation remain opaque, raising critical questions about data sensitivity, user agency, and the fidelity of the resulting portrait. To bridge this research gap, we analyze 2,050 memory entries from 80 real-world ChatGPT users. Our analyses reveal three key findings: (1) A striking 96% of memories in our dataset are created unilaterally by the conversational system, potentially shifting agency away from the user; (2) Memories, in our dataset, contain a rich mix of GDPR-defined personal data (in 28% memories) along with psychological insights about participants (in 52% memories); and (3)~A significant majority of the memories (84%) are directly grounded in user context, indicating faithful representation of the conversations. Finally, we introduce a framework-Attribution Shield-that anticipates these inferences, alerts about potentially sensitive memory inferences, and suggests query reformulations to protect personal information without sacrificing utility.
Do LLM hallucination detectors suffer from low-resource effect?
Jan 23, 2026LLMs, while outperforming humans in a wide range of tasks, can still fail in unanticipated ways. We focus on two pervasive failure modes: (i) hallucinations, where models produce incorrect information about the world, and (ii) the low-resource effect, where the models show impressive performance in high-resource languages like English but the performance degrades significantly in low-resource languages like Bengali. We study the intersection of these issues and ask: do hallucination detectors suffer from the low-resource effect? We conduct experiments on five tasks across three domains (factual recall, STEM, and Humanities). Experiments with four LLMs and three hallucination detectors reveal a curious finding: As expected, the task accuracies in low-resource languages experience large drops (compared to English). However, the drop in detectors' accuracy is often several times smaller than the drop in task accuracy. Our findings suggest that even in low-resource languages, the internal mechanisms of LLMs might encode signals about their uncertainty. Further, the detectors are robust within language (even for non-English) and in multilingual setups, but not in cross-lingual settings without in-language supervision.
Rote Learning Considered Useful: Generalizing over Memorized Data in LLMs
Jul 29, 2025Rote learning is a memorization technique based on repetition. It is commonly believed to hinder generalization by encouraging verbatim memorization rather than deeper understanding. This insight holds for even learning factual knowledge that inevitably requires a certain degree of memorization. In this work, we demonstrate that LLMs can be trained to generalize from rote memorized data. We introduce a two-phase memorize-then-generalize framework, where the model first rote memorizes factual subject-object associations using a semantically meaningless token and then learns to generalize by fine-tuning on a small set of semantically meaningful prompts. Extensive experiments over 8 LLMs show that the models can reinterpret rote memorized data through the semantically meaningful prompts, as evidenced by the emergence of structured, semantically aligned latent representations between the two. This surprising finding opens the door to both effective and efficient knowledge injection and possible risks of repurposing the memorized data for malicious usage.
Position is Power: System Prompts as a Mechanism of Bias in Large Language Models (LLMs)
May 27, 2025



System prompts in Large Language Models (LLMs) are predefined directives that guide model behaviour, taking precedence over user inputs in text processing and generation. LLM deployers increasingly use them to ensure consistent responses across contexts. While model providers set a foundation of system prompts, deployers and third-party developers can append additional prompts without visibility into others' additions, while this layered implementation remains entirely hidden from end-users. As system prompts become more complex, they can directly or indirectly introduce unaccounted for side effects. This lack of transparency raises fundamental questions about how the position of information in different directives shapes model outputs. As such, this work examines how the placement of information affects model behaviour. To this end, we compare how models process demographic information in system versus user prompts across six commercially available LLMs and 50 demographic groups. Our analysis reveals significant biases, manifesting in differences in user representation and decision-making scenarios. Since these variations stem from inaccessible and opaque system-level configurations, they risk representational, allocative and potential other biases and downstream harms beyond the user's ability to detect or correct. Our findings draw attention to these critical issues, which have the potential to perpetuate harms if left unexamined. Further, we argue that system prompt analysis must be incorporated into AI auditing processes, particularly as customisable system prompts become increasingly prevalent in commercial AI deployments.
When Should We Orchestrate Multiple Agents?
Mar 17, 2025Strategies for orchestrating the interactions between multiple agents, both human and artificial, can wildly overestimate performance and underestimate the cost of orchestration. We design a framework to orchestrate agents under realistic conditions, such as inference costs or availability constraints. We show theoretically that orchestration is only effective if there are performance or cost differentials between agents. We then empirically demonstrate how orchestration between multiple agents can be helpful for selecting agents in a simulated environment, picking a learning strategy in the infamous Rogers' Paradox from social science, and outsourcing tasks to other agents during a question-answer task in a user study.
Can LLMs Explain Themselves Counterfactually?
Feb 25, 2025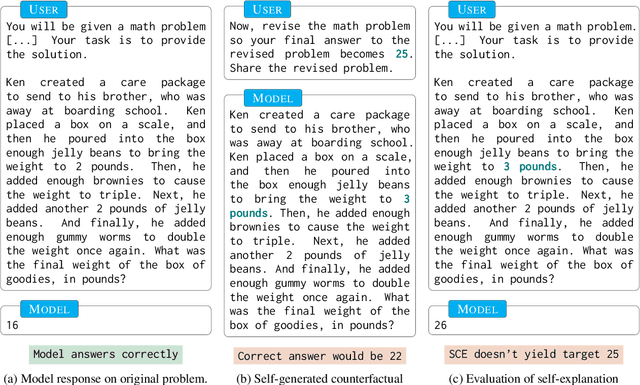
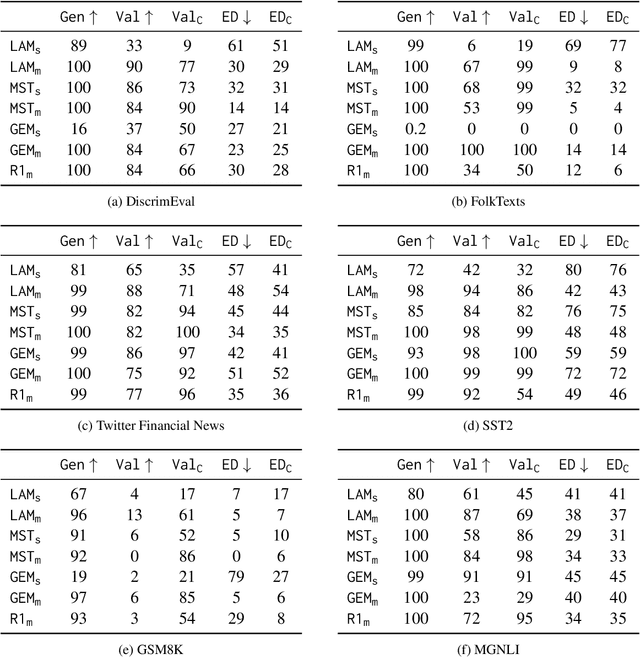
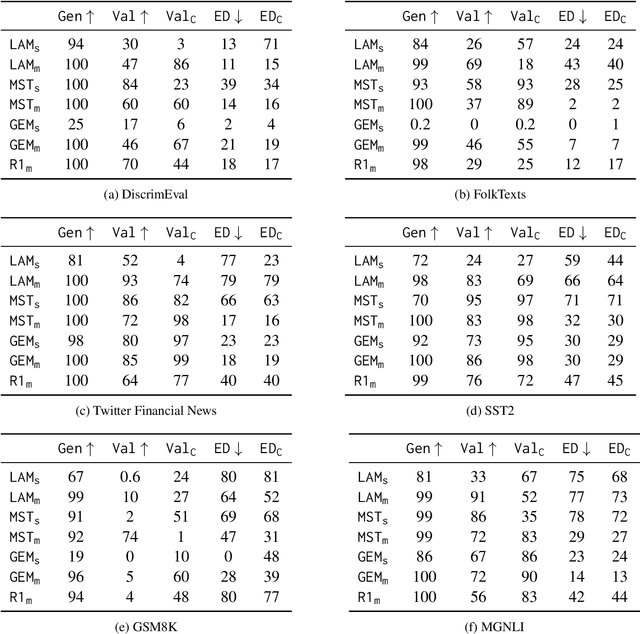
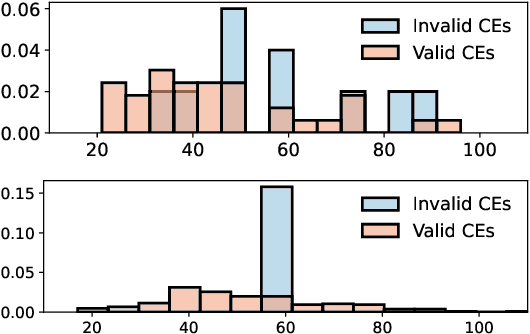
Explanations are an important tool for gaining insights into the behavior of ML models, calibrating user trust and ensuring regulatory compliance. Past few years have seen a flurry of post-hoc methods for generating model explanations, many of which involve computing model gradients or solving specially designed optimization problems. However, owing to the remarkable reasoning abilities of Large Language Model (LLMs), self-explanation, that is, prompting the model to explain its outputs has recently emerged as a new paradigm. In this work, we study a specific type of self-explanations, self-generated counterfactual explanations (SCEs). We design tests for measuring the efficacy of LLMs in generating SCEs. Analysis over various LLM families, model sizes, temperature settings, and datasets reveals that LLMs sometimes struggle to generate SCEs. Even when they do, their prediction often does not agree with their own counterfactual reasoning.
The Impact of Inference Acceleration Strategies on Bias of LLMs
Oct 29, 2024



Last few years have seen unprecedented advances in capabilities of Large Language Models (LLMs). These advancements promise to deeply benefit a vast array of application domains. However, due to their immense size, performing inference with LLMs is both costly and slow. Consequently, a plethora of recent work has proposed strategies to enhance inference efficiency, e.g., quantization, pruning, and caching. These acceleration strategies reduce the inference cost and latency, often by several factors, while maintaining much of the predictive performance measured via common benchmarks. In this work, we explore another critical aspect of LLM performance: demographic bias in model generations due to inference acceleration optimizations. Using a wide range of metrics, we probe bias in model outputs from a number of angles. Analysis of outputs before and after inference acceleration shows significant change in bias. Worryingly, these bias effects are complex and unpredictable. A combination of an acceleration strategy and bias type may show little bias change in one model but may lead to a large effect in another. Our results highlight a need for in-depth and case-by-case evaluation of model bias after it has been modified to accelerate inference.
Evaluating Large Language Models with fmeval
Jul 15, 2024



fmeval is an open source library to evaluate large language models (LLMs) in a range of tasks. It helps practitioners evaluate their model for task performance and along multiple responsible AI dimensions. This paper presents the library and exposes its underlying design principles: simplicity, coverage, extensibility and performance. We then present how these were implemented in the scientific and engineering choices taken when developing fmeval. A case study demonstrates a typical use case for the library: picking a suitable model for a question answering task. We close by discussing limitations and further work in the development of the library. fmeval can be found at https://github.com/aws/fmeval.
On Early Detection of Hallucinations in Factual Question Answering
Dec 27, 2023



While large language models (LLMs) have taken great strides towards helping humans with a plethora of tasks like search and summarization, hallucinations remain a major impediment towards gaining user trust. The fluency and coherence of model generations even when hallucinating makes it difficult to detect whether or not a model is hallucinating. In this work, we explore if the artifacts associated with the model generations can provide hints that the generation will contain hallucinations. Specifically, we probe LLMs at 1) the inputs via Integrated Gradients based token attribution, 2) the outputs via the Softmax probabilities, and 3) the internal state via self-attention and fully-connected layer activations for signs of hallucinations on open-ended question answering tasks. Our results show that the distributions of these artifacts differ between hallucinated and non-hallucinated generations. Building on this insight, we train binary classifiers that use these artifacts as input features to classify model generations into hallucinations and non-hallucinations. These hallucination classifiers achieve up to 0.80 AUROC. We further show that tokens preceding a hallucination can predict the subsequent hallucination before it occurs.
Efficient fair PCA for fair representation learning
Feb 26, 2023We revisit the problem of fair principal component analysis (PCA), where the goal is to learn the best low-rank linear approximation of the data that obfuscates demographic information. We propose a conceptually simple approach that allows for an analytic solution similar to standard PCA and can be kernelized. Our methods have the same complexity as standard PCA, or kernel PCA, and run much faster than existing methods for fair PCA based on semidefinite programming or manifold optimization, while achieving similar results.