 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You Like: Generating Explainable Topical Recommendations for Twitter Using Social Annotations
Dec 23, 2022



With over 500 million tweets posted per day, in Twitter, it is difficult for Twitter users to discover interesting content from the deluge of uninteresting posts. In this work, we present a novel, explainable, topical recommendation system, that utilizes social annotations, to help Twitter users discover tweets, on topics of their interest. A major challenge in using traditional rating dependent recommendation systems, like collaborative filtering and content based systems, in high volume social networks is that, due to attention scarcity most items do not get any ratings. Additionally, the fact that most Twitter users are passive consumers, with 44% users never tweeting, makes it very difficult to use user ratings for generating recommendations. Further, a key challenge in developing recommendation systems is that in many cases users reject relevant recommendations if they are totally unfamiliar with the recommended item. Providing a suitable explanation, for why the item is recommended, significantly improves the acceptability of recommendation. By virtue of being a topical recommendation system our method is able to present simple topical explanations for the generated recommendations. Comparisons with state-of-the-art matrix factorization based collaborative filtering, content based and social recommendations demonstrate the efficacy of the proposed approach.
Deepfake Text Detection: Limitations and Opportunities
Oct 17, 2022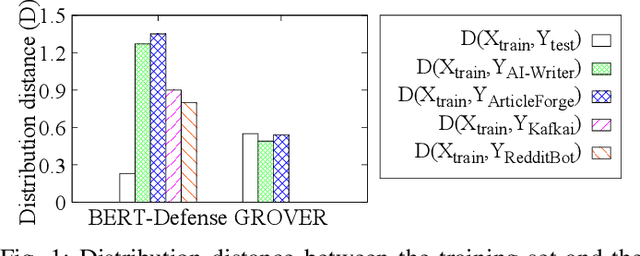
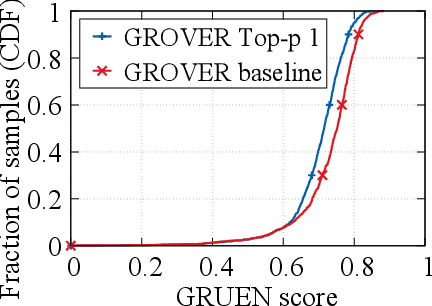
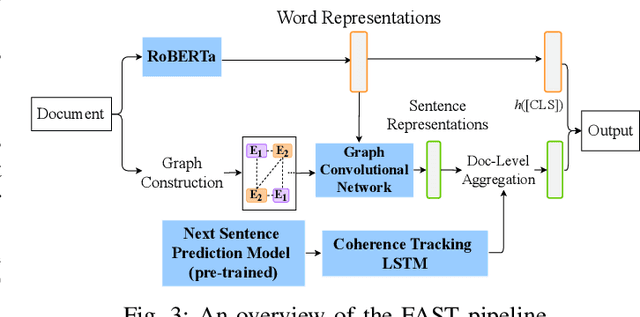
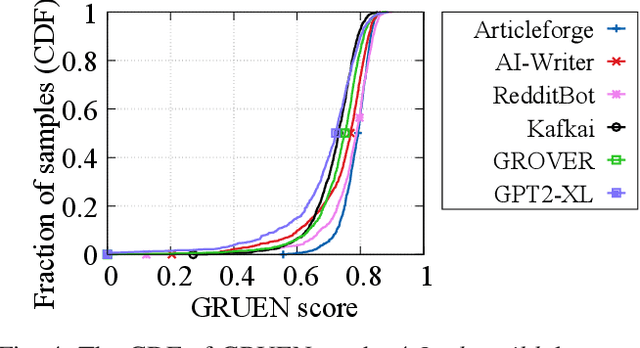
Recent advances in generative models for language have enabled the creation of convincing synthetic text or deepfake text. Prior work has demonstrated the potential for misuse of deepfake text to mislead content consumers. Therefore, deepfake text detection, the task of discriminating between human and machine-generated text, is becoming increasingly critical. Several defenses have been proposed for deepfake text detection. However, we lack a thorough understanding of their real-world applicability. In this paper, we collect deepfake text from 4 online services powered by Transformer-based tools to evaluate the generalization ability of the defenses on content in the wild. We develop several low-cost adversarial attacks, and investigate the robustness of existing defenses against an adaptive attacker. We find that many defenses show significant degradation in performance under our evaluation scenarios compared to their original claimed performance. Our evaluation shows that tapping into the semantic information in the text content is a promising approach for improving the robustness and generalization performance of deepfake text detection schemes.
Jekyll: Attacking Medical Image Diagnostics using Deep Generative Models
Apr 05, 2021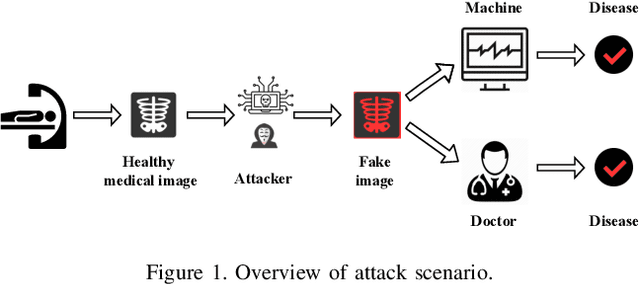
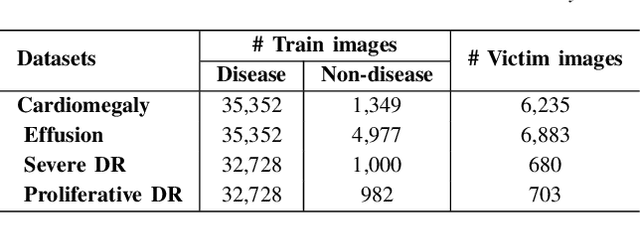
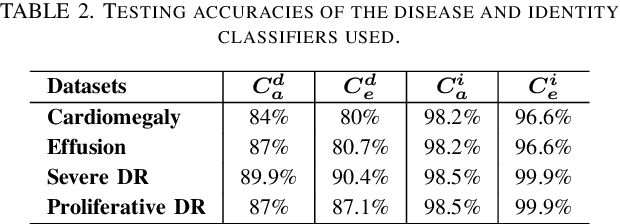
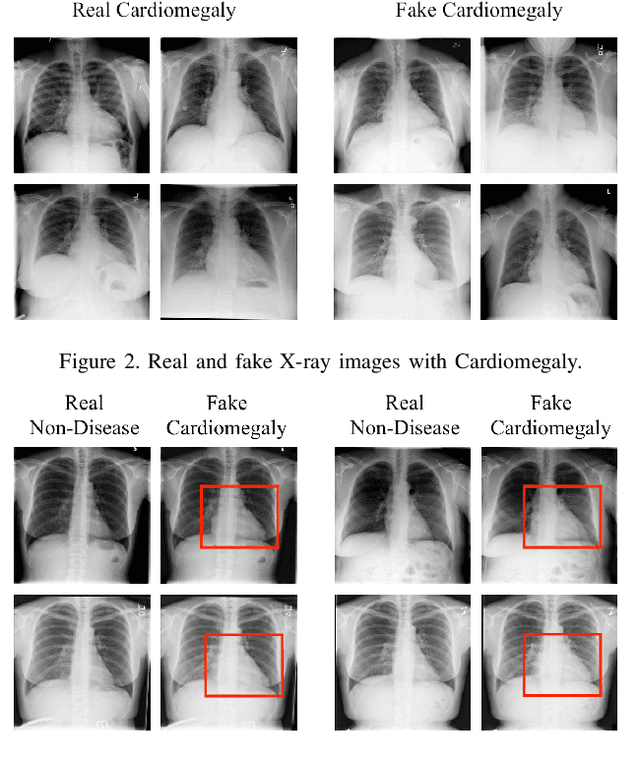
Advances in deep neural networks (DNNs) have shown tremendous promise in the medical domain. However, the deep learning tools that are helping the domain, can also be used against it. Given the prevalence of fraud in the healthcare domain, it is important to consider the adversarial use of DNNs in manipulating sensitive data that is crucial to patient healthcare. In this work, we present the design and implementation of a DNN-based image translation attack on biomedical imagery. More specifically, we propose Jekyll, a neural style transfer framework that takes as input a biomedical image of a patient and translates it to a new image that indicates an attacker-chosen disease condition. The potential for fraudulent claims based on such generated 'fake' medical images is significant, and we demonstrate successful attacks on both X-rays and retinal fundus image modalities. We show that these attacks manage to mislead both medical professionals and algorithmic detection schemes. Lastly, we also investigate defensive measures based on machine learning to detect images generated by Jekyll.
Deepfake Videos in the Wild: Analysis and Detection
Mar 11, 2021
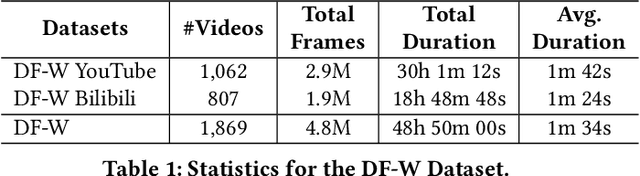

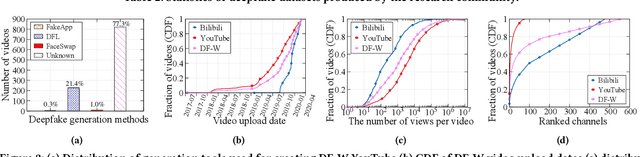
AI-manipulated videos, commonly known as deepfakes, are an emerging problem. Recently, researchers in academia and industry have contributed several (self-created) benchmark deepfake datasets, and deepfake detection algorithms. However, little effort has gone towards understanding deepfake videos in the wild, leading to a limited understanding of the real-world applicability of research contributions in this space. Even if detection schemes are shown to perform well on existing datasets, it is unclear how well the methods generalize to real-world deepfakes. To bridge this gap in knowledge, we make the following contributions: First, we collect and present the largest dataset of deepfake videos in the wild, containing 1,869 videos from YouTube and Bilibili, and extract over 4.8M frames of content. Second, we present a comprehensive analysis of the growth patterns, popularity, creators, manipulation strategies, and production methods of deepfake content in the real-world. Third, we systematically evaluate existing defenses using our new dataset, and observe that they are not ready for deployment in the real-world. Fourth, we explore the potential for transfer learning schemes and competition-winning techniques to improve defenses.