 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexusformer: Nonlinear Attention Expansion for Stable and Inheritable Transformer Scaling
Apr 21, 2026Scaling Transformers typically necessitates training larger models from scratch, as standard architectures struggle to expand without discarding learned representations. We identify the primary bottleneck in the attention mechanism's linear projections, which strictly confine feature extraction to fixed-dimensional subspaces, limiting both expressivity and incremental capacity. To address this, we introduce Nexusformer, which replaces linear $Q/K/V$ projections with a Nexus-Rank layer, a three-stage nonlinear mapping driven by dual activations in progressively higher dimensional spaces. This design overcomes the linearity constraint and enables lossless structured growth: new capacity can be injected along two axes via zero-initialized blocks that preserve pretrained knowledge. Experiments on language modeling and reasoning benchmarks demonstrate that Nexusformer matches Tokenformer's perplexity using up to 41.5\% less training compute during progressive scaling (240M to 440M). Furthermore, our analysis of growth dynamics reveals that zero initialization induces a stable convergence trajectory, allowing us to derive a geometric scaling law that accurately predicts performance across expansion scales.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
Re$^3$Sim: Generating High-Fidelity Simulation Data via 3D-Photorealistic Real-to-Sim for Robotic Manipulation
Feb 12, 2025Real-world data collection for robotics is costly and resource-intensive, requiring skilled operators and expensive hardware. Simulations offer a scalable alternative but often fail to achieve sim-to-real generalization due to geometric and visual gaps. To address these challenges, we propose a 3D-photorealistic real-to-sim system, namely, RE$^3$SIM, addressing geometric and visual sim-to-real gaps. RE$^3$SIM employs advanced 3D reconstruction and neural rendering techniques to faithfully recreate real-world scenarios, enabling real-time rendering of simulated cross-view cameras within a physics-based simulator. By utilizing privileged information to collect expert demonstrations efficiently in simulation, and train robot policies with imitation learning, we validate the effectiveness of the real-to-sim-to-real pipeline across various manipulation task scenarios. Notably, with only simulated data, we can achieve zero-shot sim-to-real transfer with an average success rate exceeding 58%. To push the limit of real-to-sim, we further generate a large-scale simulation dataset, demonstrating how a robust policy can be built from simulation data that generalizes across various objects. Codes and demos are available at: http://xshenhan.github.io/Re3Sim/.
Gated Slot Attention for Efficient Linear-Time Sequence Modeling
Sep 11, 2024



Linear attention Transformers and their gated variants, celebrated for enabling parallel training and efficient recurrent inference, still fall short in recall-intensive tasks compared to traditional Transformers and demand significant resources for training from scratch. This paper introduces Gated Slot Attention (GSA), which enhances Attention with Bounded-memory-Control (ABC) by incorporating a gating mechanism inspired by Gated Linear Attention (GLA). Essentially, GSA comprises a two-layer GLA linked via softmax, utilizing context-aware memory reading and adaptive forgetting to improve memory capacity while maintaining compact recurrent state size. This design greatly enhances both training and inference efficiency through GLA's hardware-efficient training algorithm and reduced state size. Additionally, retaining the softmax operation is particularly beneficial in "finetuning pretrained Transformers to RNNs" (T2R) settings, reducing the need for extensive training from scratch. Extensive experiments confirm GSA's superior performance in scenarios requiring in-context recall and in T2R settings.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
Deepfake Videos in the Wild: Analysis and Detection
Mar 11, 2021
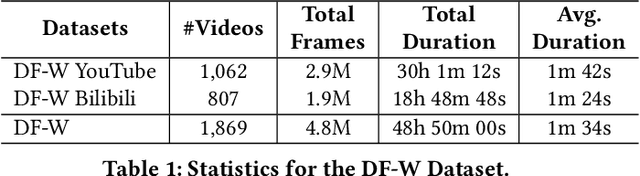

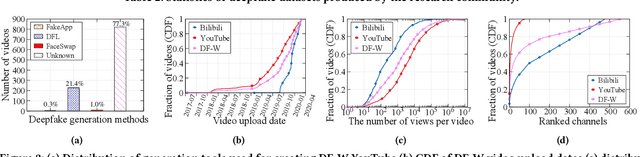
AI-manipulated videos, commonly known as deepfakes, are an emerging problem. Recently, researchers in academia and industry have contributed several (self-created) benchmark deepfake datasets, and deepfake detection algorithms. However, little effort has gone towards understanding deepfake videos in the wild, leading to a limited understanding of the real-world applicability of research contributions in this space. Even if detection schemes are shown to perform well on existing datasets, it is unclear how well the methods generalize to real-world deepfakes. To bridge this gap in knowledge, we make the following contributions: First, we collect and present the largest dataset of deepfake videos in the wild, containing 1,869 videos from YouTube and Bilibili, and extract over 4.8M frames of content. Second, we present a comprehensive analysis of the growth patterns, popularity, creators, manipulation strategies, and production methods of deepfake content in the real-world. Third, we systematically evaluate existing defenses using our new dataset, and observe that they are not ready for deployment in the real-world. Fourth, we explore the potential for transfer learning schemes and competition-winning techniques to improve defenses.
Gotta Catch 'Em All: Using Concealed Trapdoors to Detect Adversarial Attacks on Neural Networks
Apr 18, 2019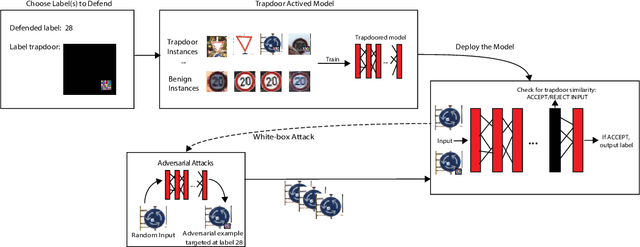
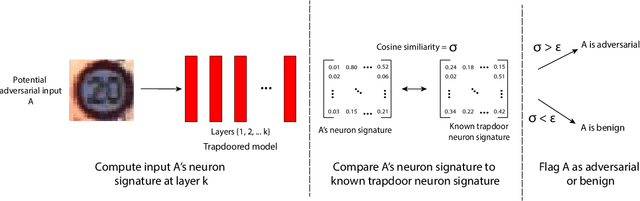
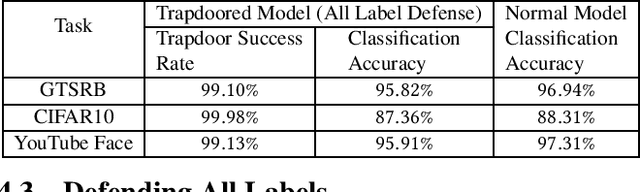
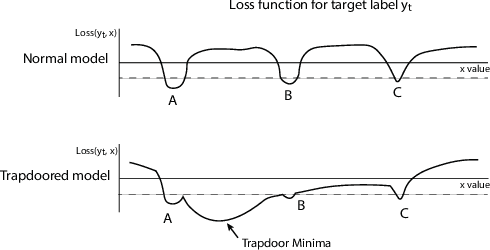
Deep neural networks are vulnerable to adversarial attacks. Numerous efforts have focused on defenses that either try to patch `holes' in trained models or try to make it difficult or costly to compute adversarial examples exploiting these holes. In our work, we explore a counter-intuitive approach of constructing "adversarial trapdoors. Unlike prior works that try to patch or disguise vulnerable points in the manifold, we intentionally inject `trapdoors,' artificial weaknesses in the manifold that attract optimized perturbation into certain pre-embedded local optima. As a result, the adversarial generation functions naturally gravitate towards our trapdoors, producing adversarial examples that the model owner can recognize through a known neuron activation signature. In this paper, we introduce trapdoors and describe an implementation of trapdoors using similar strategies to backdoor/Trojan attacks. We show that by proactively injecting trapdoors into the models (and extracting their neuron activation signature), we can detect adversarial examples generated by the state of the art attacks (Projected Gradient Descent, Optimization based CW, and Elastic Net) with high detection success rate and negligible impact on normal inputs. These results also generalize across multiple classification domains (image recognition, face recognition and traffic sign recognition). We explore different properties of trapdoors, and discuss potential countermeasures (adaptive attacks) and mitigations.