 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Streaming Video Geometry via Dynamic Feature Normalization
May 25, 2026Consistent 3D geometry estimation from streaming RGB input is crucial for real-world applications such as autonomous driving, embodied AI, and large-scale reconstruction. While modern monocular geometry foundation models achieve strong single-image accuracy, they exhibit severe temporal inconsistency on continuous input, notably dominated by scale--shift drifting. Through targeted empirical analysis, we trace this instability to its root cause: fluctuations in latent feature statistics, whose mean and variance directly determine the predicted depth's scale and shift. Building on this insight, we introduce Dynamic Feature Normalization (DyFN), a lightweight, causal recurrent module that dynamically and robustly modulates feature statistics to maintain stable geometry over time. We adapt powerful pretrained monocular geometry models for streaming by finetuning only DyFN, a mere 2\% additional parameters, while keeping the backbone frozen, thereby achieving temporal consistency without compromising single-image accuracy. Extensive experiments across four benchmarks show that DyFN effectively eliminates temporal artifacts such as disjointed layering and positional jitter, and achieves state-of-the-art temporal stability, improving over prior streaming methods by up to 14\% and even outperforming heavier non-causal video baselines. Project Page: https://shawlyu.github.io/DyFN
Articraft: An Agentic System for Scalable Articulated 3D Asset Generation
May 14, 2026A bottleneck in learning to understand articulated 3D objects is the lack of large and diverse datasets. In this paper, we propose to leverage large language models (LLMs) to close this gap and generate articulated assets at scale. We reduce the problem of generating an articulated 3D asset to that of writing a program that builds it. We then introduce a new agentic system, Articraft, that writes such programs automatically. We design a programmatic interface and harness to help the LLM do so effectively. The LLM writes code against a domain-specific SDK for defining parts, composing geometry, specifying joints, and writing tests to validate the resulting assets. The harness exposes a restricted workspace and interface to the LLM, validates the resulting assets, and returns structured feedback. In this way, the LLM is not distracted by details such as authoring a URDF file or managing a complex software environment. We show that this produces higher-quality assets than both state-of-the-art articulated-asset generators and general-purpose coding agents. Using Articraft, we build Articraft-10K, a curated dataset of over 10K articulated assets spanning 245 categories, and show its utility both for training models of articulated assets and in downstream applications such as robotics simulation and virtual reality.
LiFR-Seg: Anytime High-Frame-Rate Segmentation via Event-Guided Propagation
Mar 22, 2026Dense semantic segmentation in dynamic environments is fundamentally limited by the low-frame-rate (LFR) nature of standard cameras, which creates critical perceptual gaps between frames. To solve this, we introduce Anytime Interframe Semantic Segmentation: a new task for predicting segmentation at any arbitrary time using only a single past RGB frame and a stream of asynchronous event data. This task presents a core challenge: how to robustly propagate dense semantic features using a motion field derived from sparse and often noisy event data, all while mitigating feature degradation in highly dynamic scenes. We propose LiFR-Seg, a novel framework that directly addresses these challenges by propagating deep semantic features through time. The core of our method is an uncertainty-aware warping process, guided by an event-driven motion field and its learned, explicit confidence. A temporal memory attention module further ensures coherence in dynamic scenarios. We validate our method on the DSEC dataset and a new high-frequency synthetic benchmark (SHF-DSEC) we contribute. Remarkably, our LFR system achieves performance (73.82% mIoU on DSEC) that is statistically indistinguishable from an HFR upper-bound (within 0.09%) that has full access to the target frame. This work presents a new, efficient paradigm for achieving robust, high-frame-rate perception with low-frame-rate hardware. Project Page: https://candy-crusher.github.io/LiFR_Seg_Proj/#; Code: https://github.com/Candy-Crusher/LiFR-Seg.git.
UniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
Nov 06, 2025Feed-forward 3D reconstruction for autonomous driving has advanced rapidly, yet existing methods struggle with the joint challenges of sparse, non-overlapping camera views and complex scene dynamics. We present UniSplat, a general feed-forward framework that learns robust dynamic scene reconstruction through unified latent spatio-temporal fusion. UniSplat constructs a 3D latent scaffold, a structured representation that captures geometric and semantic scene context by leveraging pretrained foundation models. To effectively integrate information across spatial views and temporal frames, we introduce an efficient fusion mechanism that operates directly within the 3D scaffold, enabling consistent spatio-temporal alignment. To ensure complete and detailed reconstructions, we design a dual-branch decoder that generates dynamic-aware Gaussians from the fused scaffold by combining point-anchored refinement with voxel-based generation, and maintain a persistent memory of static Gaussians to enable streaming scene completion beyond current camera coverage. Extensive experiments on real-world datasets demonstrate that UniSplat achieves state-of-the-art performance in novel view synthesis, while providing robust and high-quality renderings even for viewpoints outside the original camera coverage.
DiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
Mar 19, 2025



Current generative models struggle to synthesize dynamic 4D driving scenes that simultaneously support temporal extrapolation and spatial novel view synthesis (NVS) without per-scene optimization. A key challenge lies in finding an efficient and generalizable geometric representation that seamlessly connects temporal and spatial synthesis. To address this, we propose DiST-4D, the first disentangled spatiotemporal diffusion framework for 4D driving scene generation, which leverages metric depth as the core geometric representation. DiST-4D decomposes the problem into two diffusion processes: DiST-T, which predicts future metric depth and multi-view RGB sequences directly from past observations, and DiST-S, which enables spatial NVS by training only on existing viewpoints while enforcing cycle consistency. This cycle consistency mechanism introduces a forward-backward rendering constraint, reducing the generalization gap between observed and unseen viewpoints. Metric depth is essential for both accurate reliable forecasting and accurate spatial NVS, as it provides a view-consistent geometric representation that generalizes well to unseen perspectives. Experiments demonstrate that DiST-4D achieves state-of-the-art performance in both temporal prediction and NVS tasks, while also delivering competitive performance in planning-related evaluations.
MuDG: Taming Multi-modal Diffusion with Gaussian Splatting for Urban Scene Reconstruction
Mar 13, 2025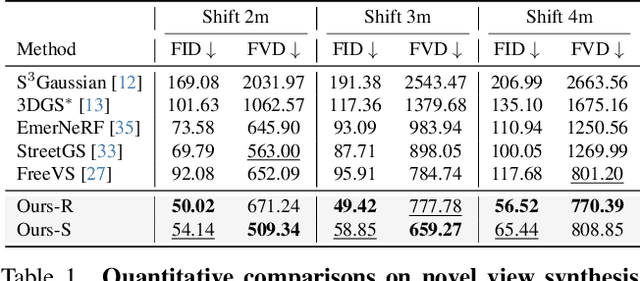
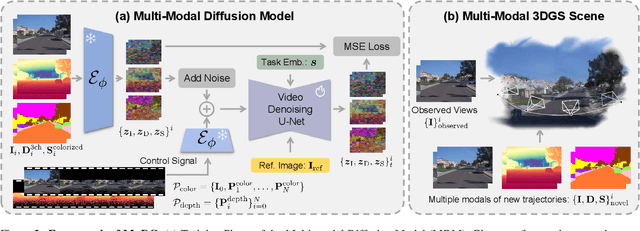
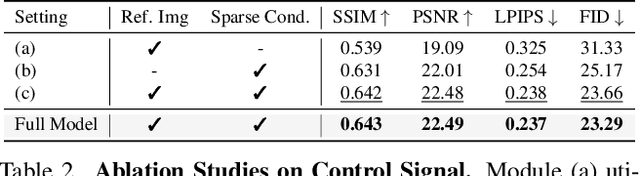
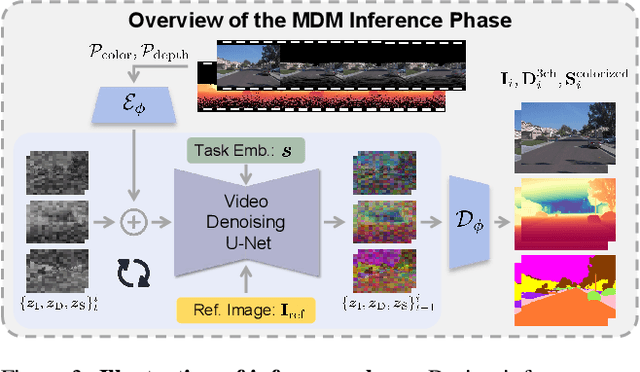
Recent breakthroughs in radiance fields have significantly advanced 3D scene reconstruction and novel view synthesis (NVS) in autonomous driving. Nevertheless, critical limitations persist: reconstruction-based methods exhibit substantial performance deterioration under significant viewpoint deviations from training trajectories, while generation-based techniques struggle with temporal coherence and precise scene controllability. To overcome these challenges, we present MuDG, an innovative framework that integrates Multi-modal Diffusion model with Gaussian Splatting (GS) for Urban Scene Reconstruction. MuDG leverages aggregated LiDAR point clouds with RGB and geometric priors to condition a multi-modal video diffusion model, synthesizing photorealistic RGB, depth, and semantic outputs for novel viewpoints. This synthesis pipeline enables feed-forward NVS without computationally intensive per-scene optimization, providing comprehensive supervision signals to refine 3DGS representations for rendering robustness enhancement under extreme viewpoint changes. Experiments on the Open Waymo Dataset demonstrate that MuDG outperforms existing methods in both reconstruction and synthesis quality.
Re$^3$Sim: Generating High-Fidelity Simulation Data via 3D-Photorealistic Real-to-Sim for Robotic Manipulation
Feb 12, 2025Real-world data collection for robotics is costly and resource-intensive, requiring skilled operators and expensive hardware. Simulations offer a scalable alternative but often fail to achieve sim-to-real generalization due to geometric and visual gaps. To address these challenges, we propose a 3D-photorealistic real-to-sim system, namely, RE$^3$SIM, addressing geometric and visual sim-to-real gaps. RE$^3$SIM employs advanced 3D reconstruction and neural rendering techniques to faithfully recreate real-world scenarios, enabling real-time rendering of simulated cross-view cameras within a physics-based simulator. By utilizing privileged information to collect expert demonstrations efficiently in simulation, and train robot policies with imitation learning, we validate the effectiveness of the real-to-sim-to-real pipeline across various manipulation task scenarios. Notably, with only simulated data, we can achieve zero-shot sim-to-real transfer with an average success rate exceeding 58%. To push the limit of real-to-sim, we further generate a large-scale simulation dataset, demonstrating how a robust policy can be built from simulation data that generalizes across various objects. Codes and demos are available at: http://xshenhan.github.io/Re3Sim/.
Deformable Radial Kernel Splatting
Dec 16, 2024



Recently, Gaussian splatting has emerged as a robust technique for representing 3D scenes, enabling real-time rasterization and high-fidelity rendering. However, Gaussians' inherent radial symmetry and smoothness constraints limit their ability to represent complex shapes, often requiring thousands of primitives to approximate detailed geometry. We introduce Deformable Radial Kernel (DRK), which extends Gaussian splatting into a more general and flexible framework. Through learnable radial bases with adjustable angles and scales, DRK efficiently models diverse shape primitives while enabling precise control over edge sharpness and boundary curvature. iven DRK's planar nature, we further develop accurate ray-primitive intersection computation for depth sorting and introduce efficient kernel culling strategies for improved rasterization efficiency. Extensive experiments demonstrate that DRK outperforms existing methods in both representation efficiency and rendering quality, achieving state-of-the-art performance while dramatically reducing primitive count.
What Matters in Detecting AI-Generated Videos like Sora?
Jun 27, 2024Recent advancements in diffusion-based video generation have showcased remarkable results, yet the gap between synthetic and real-world videos remains under-explored. In this study, we examine this gap from three fundamental perspectives: appearance, motion, and geometry, comparing real-world videos with those generated by a state-of-the-art AI model, Stable Video Diffusion. To achieve this, we train three classifiers using 3D convolutional networks, each targeting distinct aspects: vision foundation model features for appearance, optical flow for motion, and monocular depth for geometry. Each classifier exhibits strong performance in fake video detection, both qualitatively and quantitatively. This indicates that AI-generated videos are still easily detectable, and a significant gap between real and fake videos persists. Furthermore, utilizing the Grad-CAM, we pinpoint systematic failures of AI-generated videos in appearance, motion, and geometry. Finally, we propose an Ensemble-of-Experts model that integrates appearance, optical flow, and depth information for fake video detection, resulting in enhanced robustness and generalization ability. Our model is capable of detecting videos generated by Sora with high accuracy, even without exposure to any Sora videos during training. This suggests that the gap between real and fake videos can be generalized across various video generative models. Project page: https://justin-crchang.github.io/3DCNNDetection.github.io/
Splatter a Video: Video Gaussian Representation for Versatile Processing
Jun 19, 2024



Video representation is a long-standing problem that is crucial for various down-stream tasks, such as tracking,depth prediction,segmentation,view synthesis,and editing. However, current methods either struggle to model complex motions due to the absence of 3D structure or rely on implicit 3D representations that are ill-suited for manipulation tasks. To address these challenges, we introduce a novel explicit 3D representation-video Gaussian representation -- that embeds a video into 3D Gaussians. Our proposed representation models video appearance in a 3D canonical space using explicit Gaussians as proxies and associates each Gaussian with 3D motions for video motion. This approach offers a more intrinsic and explicit representation than layered atlas or volumetric pixel matrices. To obtain such a representation, we distill 2D priors, such as optical flow and depth, from foundation models to regularize learning in this ill-posed setting. Extensive applications demonstrate the versatility of our new video representation. It has been proven effective in numerous video processing tasks, including tracking, consistent video depth and feature refinement, motion and appearance editing, and stereoscopic video generation. Project page: https://sunyangtian.github.io/spatter_a_video_web/