 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainFlow-VLA: Causal Flow Planning with Vision-Language Models
May 22, 2026Current end-to-end autonomous driving systems are fundamentally limited by a mismatch between temporal causal reasoning and global trajectory consistency. Autoregressive (AR) models capture interaction-aware temporal dependencies via causal factorization, but their step-wise decoding leads to error accumulation and suboptimal global structure. In contrast, diffusion models optimize trajectories globally but lack explicit causal constraints, making them unreliable in interactive and safety-critical scenarios. This dichotomy reveals a deeper issue: existing methods treat causal modeling and global optimization as separate paradigms, without a principled way to unify them within a single trajectory distribution. To address this, we propose ChainFlow-VLA, which unifies causal generation and global refinement within a unified probabilistic framework. We formulate planning as a mixture over AR-induced modes and learn Vision-Language Model (VLM)-conditioned residual distributions over these modes. An autoregressive generator (Chain) produces a discrete set of causal trajectory modes, followed by a diffusion-based refiner (Flow) that leverages VLM hidden states as semantic priors to perform mode-conditioned correction in residual space while preserving causal structure. This straightforward conditioning seamlessly injects high-level scene understanding into fine-grained trajectory adjustments. Experiments demonstrate that ChainFlow-VLA achieves robust planning in ambiguous and long-tail scenarios, achieving a state-of-the-art score of 94.85 on the NAVSIM v1 leaderboard, matching human-level performance (94.8). Code will be available at https://github.com/AFARI-Research/ChainFlow-VLA.
CoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving
May 11, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for end-to-end autonomous driving. However, existing reasoning mechanisms still struggle to provide planning-oriented intermediate representations: textual Chain-of-Thought (CoT) fails to preserve continuous spatiotemporal structure, while latent world reasoning remains difficult to use as a direct condition for action generation. In this paper, we propose CoWorld-VLA, a multi-expert world reasoning framework for autonomous driving, where world representations serve as explicit conditions to guide action planning. CoWorld-VLA extracts complementary world information through multi-source supervision and encodes it into expert tokens within the VLA, thereby providing planner-accessible conditioning signals. Specifically, we construct four types of tokens: semantic interaction, geometric structure, dynamic evolution, and ego trajectory tokens, which respectively model interaction intent, spatial structure, future temporal dynamics, and behavioral goals. During action generation, CoWorld-VLA employs a diffusion-based hierarchical multi-expert fusion planner, which is coupled with scene context throughout the joint denoising process to generate continuous ego trajectories. Experiments show that CoWorld-VLA achieves competitive results in both future scene generation and planning on the NAVSIM v1 benchmark, demonstrating strong performance in collision avoidance and trajectory accuracy. Ablation studies further validate the complementarity of expert tokens and their effectiveness as planning conditions for action generation. Code will be available at https://github.com/potatochip1211/CoWorld-VLA.
Bridging Scene Generation and Planning: Driving with World Model via Unifying Vision and Motion Representation
Mar 16, 2026End-to-end autonomous driving aims to generate safe and plausible planning policies from raw sensor input. Driving world models have shown great potential in learning rich representations by predicting the future evolution of a driving scene. However, existing driving world models primarily focus on visual scene representation, and motion representation is not explicitly designed to be planner-shared and inheritable, leaving a schism between the optimization of visual scene generation and the requirements of precise motion planning. We present WorldDrive, a holistic framework that couples scene generation and real-time planning via unifying vision and motion representation. We first introduce a Trajectory-aware Driving World Model, which conditions on a trajectory vocabulary to enforce consistency between visual dynamics and motion intentions, enabling the generation of diverse and plausible future scenes conditioned on a specific trajectory. We transfer the vision and motion encoders to a downstream Multi-modal Planner, ensuring the driving policy operates on mature representations pre-optimized by scene generation. A simple interaction between motion representation, visual representation, and ego status can generate high-quality, multi-modal trajectories. Furthermore, to exploit the world model's foresight, we propose a Future-aware Rewarder, which distills future latent representation from the frozen world model to evaluate and select optimal trajectories in real-time. Extensive experiments on the NAVSIM, NAVSIM-v2, and nuScenes benchmarks demonstrate that WorldDrive achieves leading planning performance among vision-only methods while maintaining high-fidelity action-controlled video generation capabilities, providing strong evidence for the effectiveness of unifying vision and motion representation for robust autonomous driving.
CLAIM: Camera-LiDAR Alignment with Intensity and Monodepth
Dec 16, 2025In this paper, we unleash the potential of the powerful monodepth model in camera-LiDAR calibration and propose CLAIM, a novel method of aligning data from the camera and LiDAR. Given the initial guess and pairs of images and LiDAR point clouds, CLAIM utilizes a coarse-to-fine searching method to find the optimal transformation minimizing a patched Pearson correlation-based structure loss and a mutual information-based texture loss. These two losses serve as good metrics for camera-LiDAR alignment results and require no complicated steps of data processing, feature extraction, or feature matching like most methods, rendering our method simple and adaptive to most scenes. We validate CLAIM on public KITTI, Waymo, and MIAS-LCEC datasets, and the experimental results demonstrate its superior performance compared with the state-of-the-art methods. The code is available at https://github.com/Tompson11/claim.
Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
Jul 03, 2025Video generation models have demonstrated remarkable performance, yet their broader adoption remains constrained by slow inference speeds and substantial computational costs, primarily due to the iterative nature of the denoising process. Addressing this bottleneck is essential for democratizing advanced video synthesis technologies and enabling their integration into real-world applications. This work proposes EasyCache, a training-free acceleration framework for video diffusion models. EasyCache introduces a lightweight, runtime-adaptive caching mechanism that dynamically reuses previously computed transformation vectors, avoiding redundant computations during inference. Unlike prior approaches, EasyCache requires no offline profiling, pre-computation, or extensive parameter tuning. We conduct comprehensive studies on various large-scale video generation models, including OpenSora, Wan2.1, and HunyuanVideo. Our method achieves leading acceleration performance, reducing inference time by up to 2.1-3.3$\times$ compared to the original baselines while maintaining high visual fidelity with a significant up to 36% PSNR improvement compared to the previous SOTA method. This improvement makes our EasyCache a efficient and highly accessible solution for high-quality video generation in both research and practical applications. The code is available at https://github.com/H-EmbodVis/EasyCache.
DiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
Mar 19, 2025



Current generative models struggle to synthesize dynamic 4D driving scenes that simultaneously support temporal extrapolation and spatial novel view synthesis (NVS) without per-scene optimization. A key challenge lies in finding an efficient and generalizable geometric representation that seamlessly connects temporal and spatial synthesis. To address this, we propose DiST-4D, the first disentangled spatiotemporal diffusion framework for 4D driving scene generation, which leverages metric depth as the core geometric representation. DiST-4D decomposes the problem into two diffusion processes: DiST-T, which predicts future metric depth and multi-view RGB sequences directly from past observations, and DiST-S, which enables spatial NVS by training only on existing viewpoints while enforcing cycle consistency. This cycle consistency mechanism introduces a forward-backward rendering constraint, reducing the generalization gap between observed and unseen viewpoints. Metric depth is essential for both accurate reliable forecasting and accurate spatial NVS, as it provides a view-consistent geometric representation that generalizes well to unseen perspectives. Experiments demonstrate that DiST-4D achieves state-of-the-art performance in both temporal prediction and NVS tasks, while also delivering competitive performance in planning-related evaluations.
MuDG: Taming Multi-modal Diffusion with Gaussian Splatting for Urban Scene Reconstruction
Mar 13, 2025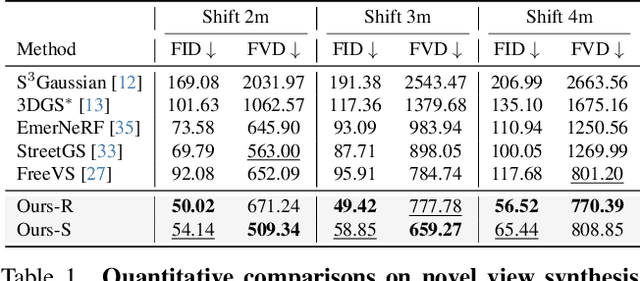
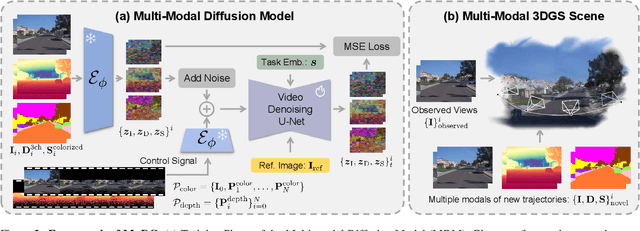
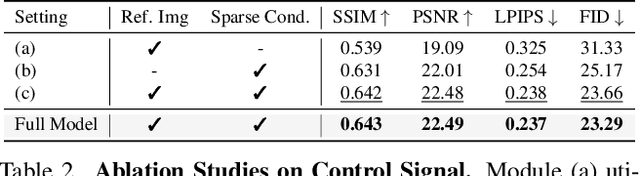
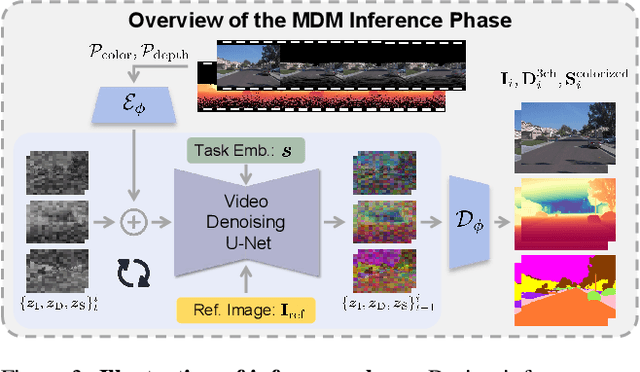
Recent breakthroughs in radiance fields have significantly advanced 3D scene reconstruction and novel view synthesis (NVS) in autonomous driving. Nevertheless, critical limitations persist: reconstruction-based methods exhibit substantial performance deterioration under significant viewpoint deviations from training trajectories, while generation-based techniques struggle with temporal coherence and precise scene controllability. To overcome these challenges, we present MuDG, an innovative framework that integrates Multi-modal Diffusion model with Gaussian Splatting (GS) for Urban Scene Reconstruction. MuDG leverages aggregated LiDAR point clouds with RGB and geometric priors to condition a multi-modal video diffusion model, synthesizing photorealistic RGB, depth, and semantic outputs for novel viewpoints. This synthesis pipeline enables feed-forward NVS without computationally intensive per-scene optimization, providing comprehensive supervision signals to refine 3DGS representations for rendering robustness enhancement under extreme viewpoint changes. Experiments on the Open Waymo Dataset demonstrate that MuDG outperforms existing methods in both reconstruction and synthesis quality.
HERMES: A Unified Self-Driving World Model for Simultaneous 3D Scene Understanding and Generation
Jan 24, 2025



Driving World Models (DWMs) have become essential for autonomous driving by enabling future scene prediction. However, existing DWMs are limited to scene generation and fail to incorporate scene understanding, which involves interpreting and reasoning about the driving environment. In this paper, we present a unified Driving World Model named HERMES. We seamlessly integrate 3D scene understanding and future scene evolution (generation) through a unified framework in driving scenarios. Specifically, HERMES leverages a Bird's-Eye View (BEV) representation to consolidate multi-view spatial information while preserving geometric relationships and interactions. We also introduce world queries, which incorporate world knowledge into BEV features via causal attention in the Large Language Model (LLM), enabling contextual enrichment for understanding and generation tasks. We conduct comprehensive studies on nuScenes and OmniDrive-nuScenes datasets to validate the effectiveness of our method. HERMES achieves state-of-the-art performance, reducing generation error by 32.4% and improving understanding metrics such as CIDEr by 8.0%. The model and code will be publicly released at https://github.com/LMD0311/HERMES.
UniScene: Unified Occupancy-centric Driving Scene Generation
Dec 06, 2024Generating high-fidelity, controllable, and annotated training data is critical for autonomous driving. Existing methods typically generate a single data form directly from a coarse scene layout, which not only fails to output rich data forms required for diverse downstream tasks but also struggles to model the direct layout-to-data distribution. In this paper, we introduce UniScene, the first unified framework for generating three key data forms - semantic occupancy, video, and LiDAR - in driving scenes. UniScene employs a progressive generation process that decomposes the complex task of scene generation into two hierarchical steps: (a) first generating semantic occupancy from a customized scene layout as a meta scene representation rich in both semantic and geometric information, and then (b) conditioned on occupancy, generating video and LiDAR data, respectively, with two novel transfer strategies of Gaussian-based Joint Rendering and Prior-guided Sparse Modeling. This occupancy-centric approach reduces the generation burden, especially for intricate scenes, while providing detailed intermediate representations for the subsequent generation stages. Extensive experiments demonstrate that UniScene outperforms previous SOTAs in the occupancy, video, and LiDAR generation, which also indeed benefits downstream driving tasks.
SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.