 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMART: Decomposing Monolithic Meshes into Sim-ready Articulated Assets via MLLM
Mar 24, 2026High-quality articulated 3D assets are indispensable for embodied AI and physical simulation, yet 3D generation still focuses on static meshes, leaving a gap in "sim-ready" interactive objects. Most recent articulated object creation methods rely on multi-stage pipelines that accumulate errors across decoupled modules. Alternatively, unified MLLMs offer a single-stage path to joint static asset understanding and sim-ready asset generation. However dense voxel-based 3D tokenization yields long 3D token sequences and high memory overhead, limiting scalability to complex articulated objects. To address this, we propose SIMART, a unified MLLM framework that jointly performs part-level decomposition and kinematic prediction. By introducing a Sparse 3D VQ-VAE, SIMART reduces token counts by 70% vs. dense voxel tokens, enabling high-fidelity multi-part assemblies. SIMART achieves state-of-the-art performance on PartNet-Mobility and in-the-wild AIGC datasets, and enables physics-based robotic simulation.
When Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
Mar 22, 2026Recent progress in multimodal large language models has led to strong performance on reasoning tasks, but these improvements largely rely on high-quality annotated data or teacher-model distillation, both of which are costly and difficult to scale.To address this, we propose an unsupervised self-evolution training framework for multimodal reasoning that achieves stable performance improvements without using human-annotated answers or external reward models. For each input, we sample multiple reasoning trajectories and jointly model their within group structure.We use the Actor's self-consistency signal as a training prior, and introduce a bounded Judge based modulation to continuously reweight trajectories of different quality.We further model the modulated scores as a group level distribution and convert absolute scores into relative advantages within each group, enabling more robust policy updates. Trained with Group Relative Policy Optimization (GRPO) on unlabeled data, our method consistently improves reasoning performance and generalization on five mathematical reasoning benchmarks, offering a scalable path toward self-evolving multimodal models.The code are available at https://dingwu1021.github.io/SelfJudge/.
UniPR: Unified Object-level Real-to-Sim Perception and Reconstruction from a Single Stereo Pair
Mar 20, 2026Perceiving and reconstructing objects from images are critical for real-to-sim transfer tasks, which are widely used in the robotics community. Existing methods rely on multiple submodules such as detection, segmentation, shape reconstruction, and pose estimation to complete the pipeline. However, such modular pipelines suffer from inefficiency and cumulative error, as each stage operates on only partial or locally refined information while discarding global context. To address these limitations, we propose UniPR, the first end-to-end object-level real-to-sim perception and reconstruction framework. Operating directly on a single stereo image pair, UniPR leverages geometric constraints to resolve the scale ambiguity. We introduce Pose-Aware Shape Representation to eliminate the need for per-category canonical definitions and to bridge the gap between reconstruction and pose estimation tasks. Furthermore, we construct a large-vocabulary stereo dataset, LVS6D, comprising over 6,300 objects, to facilitate large-scale research in this area. Extensive experiments demonstrate that UniPR reconstructs all objects in a scene in parallel within a single forward pass, achieving significant efficiency gains and preserves true physical proportions across diverse object types, highlighting its potential for practical robotic applications.
Language-Guided and Motion-Aware Gait Representation for Generalizable Recognition
Jan 17, 2026Gait recognition is emerging as a promising technology and an innovative field within computer vision. However, existing methods typically rely on complex architectures to directly extract features from images and apply pooling operations to obtain sequence-level representations. Such designs often lead to overfitting on static noise (e.g., clothing), while failing to effectively capture dynamic motion regions.To address the above challenges, we present a Language guided and Motion-aware gait recognition framework, named LMGait.In particular, we utilize designed gait-related language cues to capture key motion features in gait sequences.
DAGait: Generalized Skeleton-Guided Data Alignment for Gait Recognition
Mar 24, 2025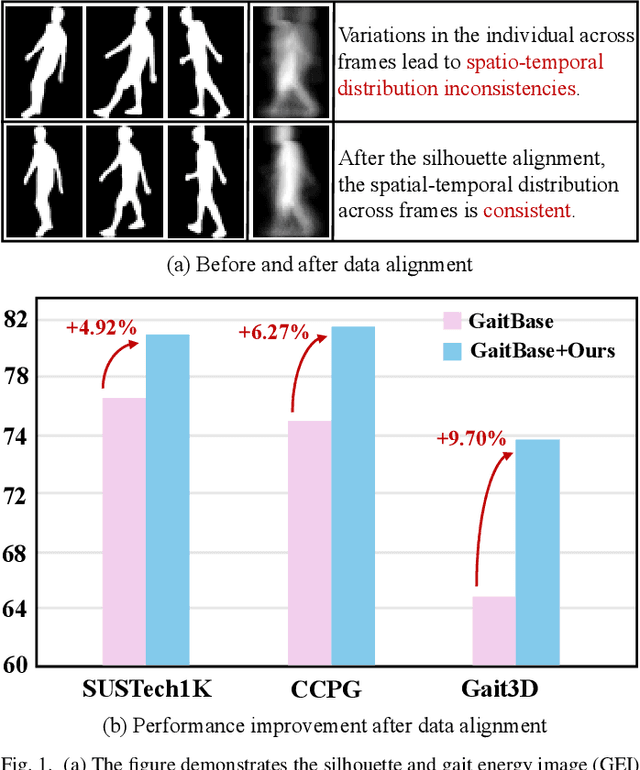
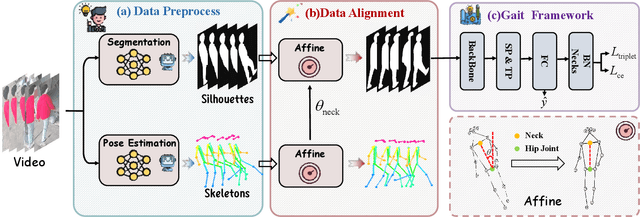
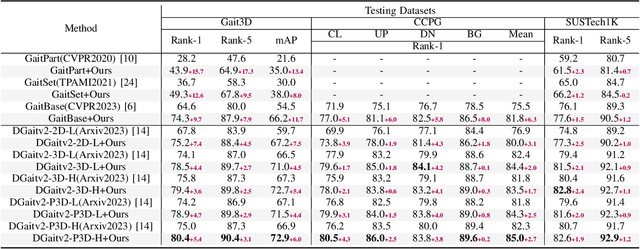
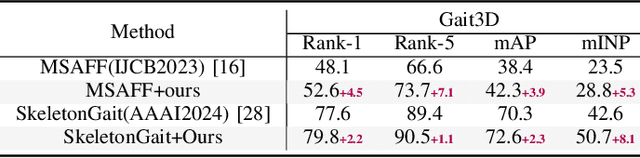
Gait recognition is emerging as a promising and innovative area within the field of computer vision, widely applied to remote person identification. Although existing gait recognition methods have achieved substantial success in controlled laboratory datasets, their performance often declines significantly when transitioning to wild datasets.We argue that the performance gap can be primarily attributed to the spatio-temporal distribution inconsistencies present in wild datasets, where subjects appear at varying angles, positions, and distances across the frames. To achieve accurate gait recognition in the wild, we propose a skeleton-guided silhouette alignment strategy, which uses prior knowledge of the skeletons to perform affine transformations on the corresponding silhouettes.To the best of our knowledge, this is the first study to explore the impact of data alignment on gait recognition. We conducted extensive experiments across multiple datasets and network architectures, and the results demonstrate the significant advantages of our proposed alignment strategy.Specifically, on the challenging Gait3D dataset, our method achieved an average performance improvement of 7.9% across all evaluated networks. Furthermore, our method achieves substantial improvements on cross-domain datasets, with accuracy improvements of up to 24.0%.
PSGait: Multimodal Gait Recognition using Parsing Skeleton
Mar 15, 2025Gait recognition has emerged as a robust biometric modality due to its non-intrusive nature and resilience to occlusion. Conventional gait recognition methods typically rely on silhouettes or skeletons. Despite their success in gait recognition for controlled laboratory environments, they usually fail in real-world scenarios due to their limited information entropy for gait representations. To achieve accurate gait recognition in the wild, we propose a novel gait representation, named Parsing Skeleton. This representation innovatively introduces the skeleton-guided human parsing method to capture fine-grained body dynamics, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the parsing skeleton representation, we propose a novel parsing skeleton-based gait recognition framework, named PSGait, which takes parsing skeletons and silhouettes as input. By fusing these two modalities, the resulting image sequences are fed into gait recognition models for enhanced individual differentiation. We conduct comprehensive benchmarks on various datasets to evaluate our model. PSGait outperforms existing state-of-the-art multimodal methods. Furthermore, as a plug-and-play method, PSGait leads to a maximum improvement of 10.9% in Rank-1 accuracy across various gait recognition models. These results demonstrate the effectiveness and versatility of parsing skeletons for gait recognition in the wild, establishing PSGait as a new state-of-the-art approach for multimodal gait recognition.
MuDG: Taming Multi-modal Diffusion with Gaussian Splatting for Urban Scene Reconstruction
Mar 13, 2025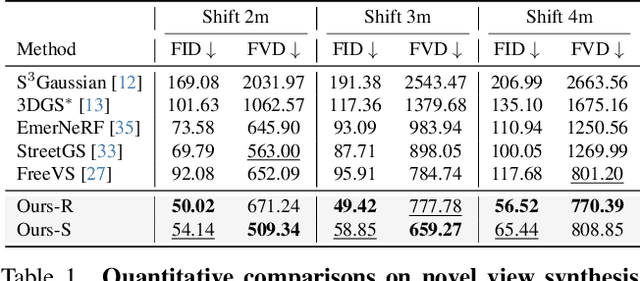
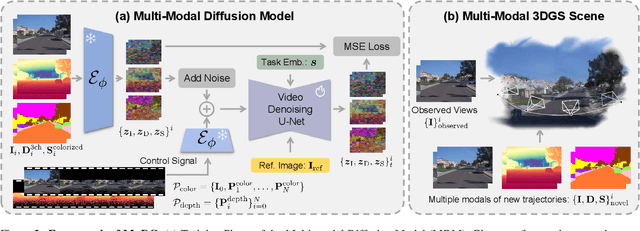
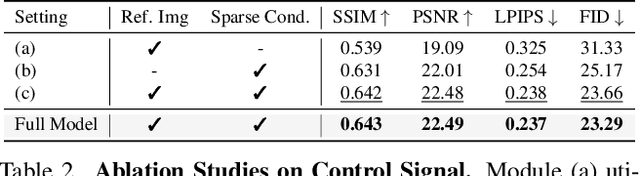
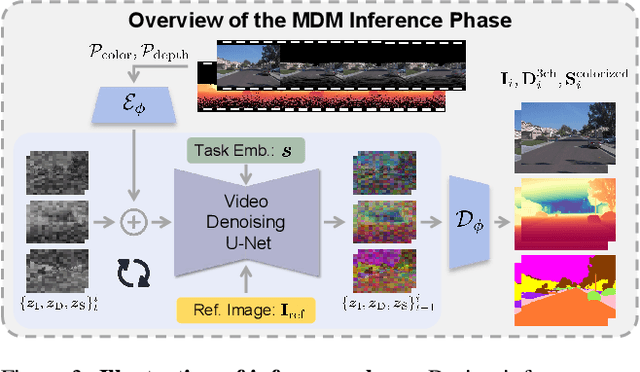
Recent breakthroughs in radiance fields have significantly advanced 3D scene reconstruction and novel view synthesis (NVS) in autonomous driving. Nevertheless, critical limitations persist: reconstruction-based methods exhibit substantial performance deterioration under significant viewpoint deviations from training trajectories, while generation-based techniques struggle with temporal coherence and precise scene controllability. To overcome these challenges, we present MuDG, an innovative framework that integrates Multi-modal Diffusion model with Gaussian Splatting (GS) for Urban Scene Reconstruction. MuDG leverages aggregated LiDAR point clouds with RGB and geometric priors to condition a multi-modal video diffusion model, synthesizing photorealistic RGB, depth, and semantic outputs for novel viewpoints. This synthesis pipeline enables feed-forward NVS without computationally intensive per-scene optimization, providing comprehensive supervision signals to refine 3DGS representations for rendering robustness enhancement under extreme viewpoint changes. Experiments on the Open Waymo Dataset demonstrate that MuDG outperforms existing methods in both reconstruction and synthesis quality.
TranSplat: Generalizable 3D Gaussian Splatting from Sparse Multi-View Images with Transformers
Aug 25, 2024



Compared with previous 3D reconstruction methods like Nerf, recent Generalizable 3D Gaussian Splatting (G-3DGS) methods demonstrate impressive efficiency even in the sparse-view setting. However, the promising reconstruction performance of existing G-3DGS methods relies heavily on accurate multi-view feature matching, which is quite challenging. Especially for the scenes that have many non-overlapping areas between various views and contain numerous similar regions, the matching performance of existing methods is poor and the reconstruction precision is limited. To address this problem, we develop a strategy that utilizes a predicted depth confidence map to guide accurate local feature matching. In addition, we propose to utilize the knowledge of existing monocular depth estimation models as prior to boost the depth estimation precision in non-overlapping areas between views. Combining the proposed strategies, we present a novel G-3DGS method named TranSplat, which obtains the best performance on both the RealEstate10K and ACID benchmarks while maintaining competitive speed and presenting strong cross-dataset generalization ability. Our code, and demos will be available at: https://xingyoujun.github.io/transplat.
Category-level Object Detection, Pose Estimation and Reconstruction from Stereo Images
Jul 09, 2024We study the 3D object understanding task for manipulating everyday objects with different material properties (diffuse, specular, transparent and mixed). Existing monocular and RGB-D methods suffer from scale ambiguity due to missing or imprecise depth measurements. We present CODERS, a one-stage approach for Category-level Object Detection, pose Estimation and Reconstruction from Stereo images. The base of our pipeline is an implicit stereo matching module that combines stereo image features with 3D position information. Concatenating this presented module and the following transform-decoder architecture leads to end-to-end learning of multiple tasks required by robot manipulation. Our approach significantly outperforms all competing methods in the public TOD dataset. Furthermore, trained on simulated data, CODERS generalize well to unseen category-level object instances in real-world robot manipulation experiments. Our dataset, code, and demos will be available on our project page.
VoxelFormer: Bird's-Eye-View Feature Generation based on Dual-view Attention for Multi-view 3D Object Detection
Apr 03, 2023In recent years, transformer-based detectors have demonstrated remarkable performance in 2D visual perception tasks. However, their performance in multi-view 3D object detection remains inferior to the state-of-the-art (SOTA) of convolutional neural network based detectors. In this work, we investigate this issue from the perspective of bird's-eye-view (BEV) feature generation. Specifically, we examine the BEV feature generation method employed by the transformer-based SOTA, BEVFormer, and identify its two limitations: (i) it only generates attention weights from BEV, which precludes the use of lidar points for supervision, and (ii) it aggregates camera view features to the BEV through deformable sampling, which only selects a small subset of features and fails to exploit all information. To overcome these limitations, we propose a novel BEV feature generation method, dual-view attention, which generates attention weights from both the BEV and camera view. This method encodes all camera features into the BEV feature. By combining dual-view attention with the BEVFormer architecture, we build a new detector named VoxelFormer. Extensive experiments are conducted on the nuScenes benchmark to verify the superiority of dual-view attention and VoxelForer. We observe that even only adopting 3 encoders and 1 historical frame during training, VoxelFormer still outperforms BEVFormer significantly. When trained in the same setting, VoxelFormer can surpass BEVFormer by 4.9% NDS point. Code is available at: https://github.com/Lizhuoling/VoxelFormer-public.git.