 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence
May 27, 2024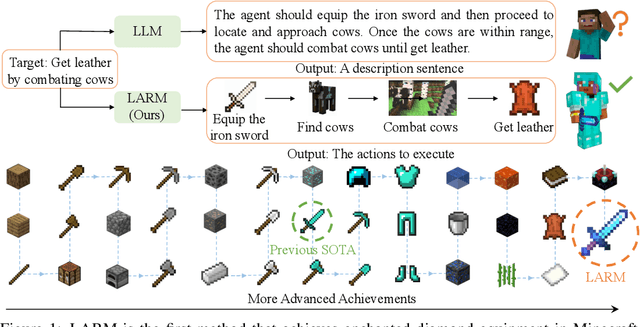
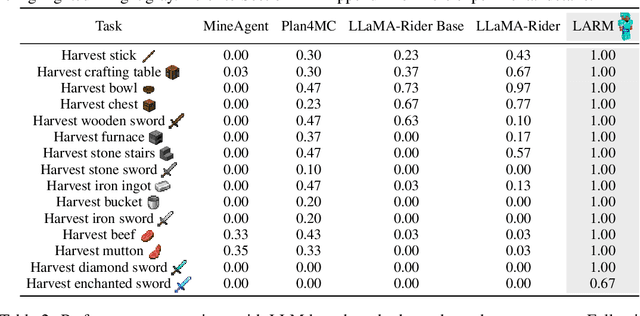
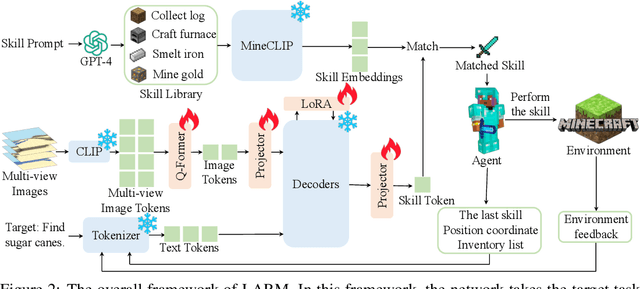

Due to the need to interact with the real world, embodied agents are required to possess comprehensive prior knowledge, long-horizon planning capability, and a swift response speed. Despite recent large language model (LLM) based agents achieving promising performance, they still exhibit several limitations. For instance, the output of LLMs is a descriptive sentence, which is ambiguous when determining specific actions. To address these limitations, we introduce the large auto-regressive model (LARM). LARM leverages both text and multi-view images as input and predicts subsequent actions in an auto-regressive manner. To train LARM, we develop a novel data format named auto-regressive node transmission structure and assemble a corresponding dataset. Adopting a two-phase training regimen, LARM successfully harvests enchanted equipment in Minecraft, which demands significantly more complex decision-making chains than the highest achievements of prior best methods. Besides, the speed of LARM is 6.8x faster.
UniMODE: Unified Monocular 3D Object Detection
Feb 28, 2024
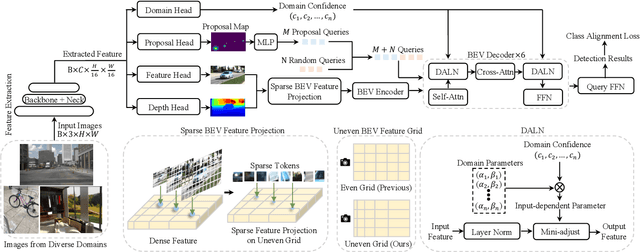
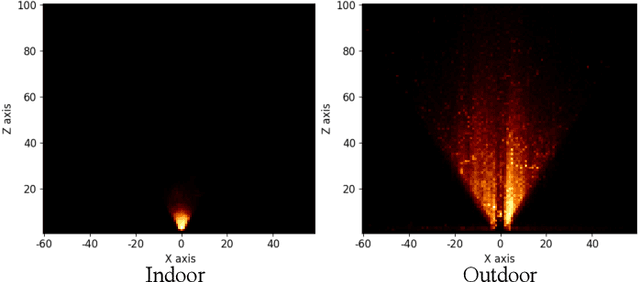

Realizing unified monocular 3D object detection, including both indoor and outdoor scenes, holds great importance in applications like robot navigation. However, involving various scenarios of data to train models poses challenges due to their significantly different characteristics, e.g., diverse geometry properties and heterogeneous domain distributions. To address these challenges, we build a detector based on the bird's-eye-view (BEV) detection paradigm, where the explicit feature projection is beneficial to addressing the geometry learning ambiguity when employing multiple scenarios of data to train detectors. Then, we split the classical BEV detection architecture into two stages and propose an uneven BEV grid design to handle the convergence instability caused by the aforementioned challenges. Moreover, we develop a sparse BEV feature projection strategy to reduce computational cost and a unified domain alignment method to handle heterogeneous domains. Combining these techniques, a unified detector UniMODE is derived, which surpasses the previous state-of-the-art on the challenging Omni3D dataset (a large-scale dataset including both indoor and outdoor scenes) by 4.9% AP_3D, revealing the first successful generalization of a BEV detector to unified 3D object detection.
VoxelFormer: Bird's-Eye-View Feature Generation based on Dual-view Attention for Multi-view 3D Object Detection
Apr 03, 2023In recent years, transformer-based detectors have demonstrated remarkable performance in 2D visual perception tasks. However, their performance in multi-view 3D object detection remains inferior to the state-of-the-art (SOTA) of convolutional neural network based detectors. In this work, we investigate this issue from the perspective of bird's-eye-view (BEV) feature generation. Specifically, we examine the BEV feature generation method employed by the transformer-based SOTA, BEVFormer, and identify its two limitations: (i) it only generates attention weights from BEV, which precludes the use of lidar points for supervision, and (ii) it aggregates camera view features to the BEV through deformable sampling, which only selects a small subset of features and fails to exploit all information. To overcome these limitations, we propose a novel BEV feature generation method, dual-view attention, which generates attention weights from both the BEV and camera view. This method encodes all camera features into the BEV feature. By combining dual-view attention with the BEVFormer architecture, we build a new detector named VoxelFormer. Extensive experiments are conducted on the nuScenes benchmark to verify the superiority of dual-view attention and VoxelForer. We observe that even only adopting 3 encoders and 1 historical frame during training, VoxelFormer still outperforms BEVFormer significantly. When trained in the same setting, VoxelFormer can surpass BEVFormer by 4.9% NDS point. Code is available at: https://github.com/Lizhuoling/VoxelFormer-public.git.
Robustness and Generalization via Generative Adversarial Training
Sep 06, 2021

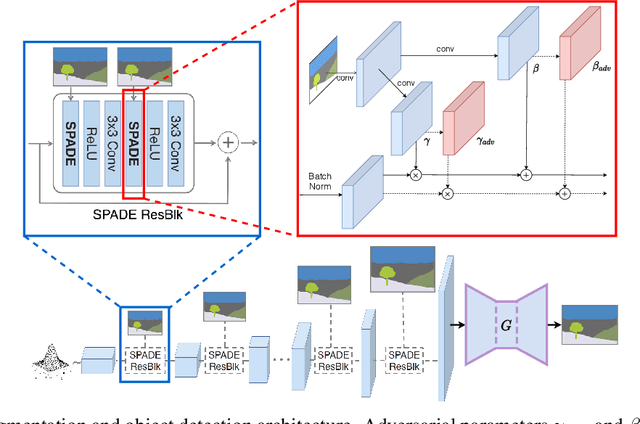
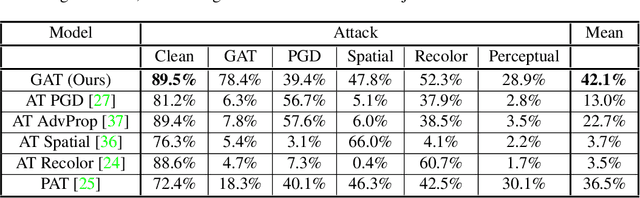
While deep neural networks have achieved remarkable success in various computer vision tasks, they often fail to generalize to new domains and subtle variations of input images. Several defenses have been proposed to improve the robustness against these variations. However, current defenses can only withstand the specific attack used in training, and the models often remain vulnerable to other input variations. Moreover, these methods often degrade performance of the model on clean images and do not generalize to out-of-domain samples. In this paper we present Generative Adversarial Training, an approach to simultaneously improve the model's generalization to the test set and out-of-domain samples as well as its robustness to unseen adversarial attacks. Instead of altering a low-level pre-defined aspect of images, we generate a spectrum of low-level, mid-level and high-level changes using generative models with a disentangled latent space. Adversarial training with these examples enable the model to withstand a wide range of attacks by observing a variety of input alterations during training. We show that our approach not only improves performance of the model on clean images and out-of-domain samples but also makes it robust against unforeseen attacks and outperforms prior work. We validate effectiveness of our method by demonstrating results on various tasks such as classification, segmentation and object detection.