 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
Mar 02, 2026This report presents CharacterFlywheel, an iterative flywheel process for improving large language models (LLMs) in production social chat applications across Instagram, WhatsApp, and Messenger. Starting from LLaMA 3.1, we refined models across 15 generations using data from both internal and external real-user traffic. Through continuous deployments from July 2024 to April 2025, we conducted controlled 7-day A/B tests showing consistent engagement improvements: 7 of 8 newly deployed models demonstrated positive lift over the baseline, with the strongest performers achieving up to 8.8% improvement in engagement breadth and 19.4% in engagement depth. We also observed substantial gains in steerability, with instruction following increasing from 59.2% to 84.8% and instruction violations decreasing from 26.6% to 5.8%. We detail the CharacterFlywheel process which integrates data curation, reward modeling to estimate and interpolate the landscape of engagement metrics, supervised fine-tuning (SFT), reinforcement learning (RL), and both offline and online evaluation to ensure reliable progress at each optimization step. We also discuss our methods for overfitting prevention and navigating production dynamics at scale. These contributions advance the scientific rigor and understanding of LLMs in social applications serving millions of users.
ROICtrl: Boosting Instance Control for Visual Generation
Nov 27, 2024



Natural language often struggles to accurately associate positional and attribute information with multiple instances, which limits current text-based visual generation models to simpler compositions featuring only a few dominant instances. To address this limitation, this work enhances diffusion models by introducing regional instance control, where each instance is governed by a bounding box paired with a free-form caption. Previous methods in this area typically rely on implicit position encoding or explicit attention masks to separate regions of interest (ROIs), resulting in either inaccurate coordinate injection or large computational overhead. Inspired by ROI-Align in object detection, we introduce a complementary operation called ROI-Unpool. Together, ROI-Align and ROI-Unpool enable explicit, efficient, and accurate ROI manipulation on high-resolution feature maps for visual generation. Building on ROI-Unpool, we propose ROICtrl, an adapter for pretrained diffusion models that enables precise regional instance control. ROICtrl is compatible with community-finetuned diffusion models, as well as with existing spatial-based add-ons (\eg, ControlNet, T2I-Adapter) and embedding-based add-ons (\eg, IP-Adapter, ED-LoRA), extending their applications to multi-instance generation. Experiments show that ROICtrl achieves superior performance in regional instance control while significantly reducing computational costs.
Universal Pyramid Adversarial Training for Improved ViT Performance
Dec 26, 2023



Recently, Pyramid Adversarial training (Herrmann et al., 2022) has been shown to be very effective for improving clean accuracy and distribution-shift robustness of vision transformers. However, due to the iterative nature of adversarial training, the technique is up to 7 times more expensive than standard training. To make the method more efficient, we propose Universal Pyramid Adversarial training, where we learn a single pyramid adversarial pattern shared across the whole dataset instead of the sample-wise patterns. With our proposed technique, we decrease the computational cost of Pyramid Adversarial training by up to 70% while retaining the majority of its benefit on clean performance and distribution-shift robustness. In addition, to the best of our knowledge, we are also the first to find that universal adversarial training can be leveraged to improve clean model performance.
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
Dec 05, 2023



Current diffusion-based video editing primarily focuses on structure-preserved editing by utilizing various dense correspondences to ensure temporal consistency and motion alignment. However, these approaches are often ineffective when the target edit involves a shape change. To embark on video editing with shape change, we explore customized video subject swapping in this work, where we aim to replace the main subject in a source video with a target subject having a distinct identity and potentially different shape. In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape. We also introduce various user-point interactions (\eg, removing points and dragging points) to address various semantic point correspondence. Extensive experiments demonstrate state-of-the-art video subject swapping results across a variety of real-world videos.
VoxelFormer: Bird's-Eye-View Feature Generation based on Dual-view Attention for Multi-view 3D Object Detection
Apr 03, 2023In recent years, transformer-based detectors have demonstrated remarkable performance in 2D visual perception tasks. However, their performance in multi-view 3D object detection remains inferior to the state-of-the-art (SOTA) of convolutional neural network based detectors. In this work, we investigate this issue from the perspective of bird's-eye-view (BEV) feature generation. Specifically, we examine the BEV feature generation method employed by the transformer-based SOTA, BEVFormer, and identify its two limitations: (i) it only generates attention weights from BEV, which precludes the use of lidar points for supervision, and (ii) it aggregates camera view features to the BEV through deformable sampling, which only selects a small subset of features and fails to exploit all information. To overcome these limitations, we propose a novel BEV feature generation method, dual-view attention, which generates attention weights from both the BEV and camera view. This method encodes all camera features into the BEV feature. By combining dual-view attention with the BEVFormer architecture, we build a new detector named VoxelFormer. Extensive experiments are conducted on the nuScenes benchmark to verify the superiority of dual-view attention and VoxelForer. We observe that even only adopting 3 encoders and 1 historical frame during training, VoxelFormer still outperforms BEVFormer significantly. When trained in the same setting, VoxelFormer can surpass BEVFormer by 4.9% NDS point. Code is available at: https://github.com/Lizhuoling/VoxelFormer-public.git.
A Unified Model for Tracking and Image-Video Detection Has More Power
Nov 20, 2022



Objection detection (OD) has been one of the most fundamental tasks in computer vision. Recent developments in deep learning have pushed the performance of image OD to new heights by learning-based, data-driven approaches. On the other hand, video OD remains less explored, mostly due to much more expensive data annotation needs. At the same time, multi-object tracking (MOT) which requires reasoning about track identities and spatio-temporal trajectories, shares similar spirits with video OD. However, most MOT datasets are class-specific (e.g., person-annotated only), which constrains a model's flexibility to perform tracking on other objects. We propose TrIVD (Tracking and Image-Video Detection), the first framework that unifies image OD, video OD, and MOT within one end-to-end model. To handle the discrepancies and semantic overlaps across datasets, TrIVD formulates detection/tracking as grounding and reasons about object categories via visual-text alignments. The unified formulation enables cross-dataset, multi-task training, and thus equips TrIVD with the ability to leverage frame-level features, video-level spatio-temporal relations, as well as track identity associations. With such joint training, we can now extend the knowledge from OD data, that comes with much richer object category annotations, to MOT and achieve zero-shot tracking capability. Experiments demonstrate that TrIVD achieves state-of-the-art performances across all image/video OD and MOT tasks.
Self-appearance-aided Differential Evolution for Motion Transfer
Oct 09, 2021
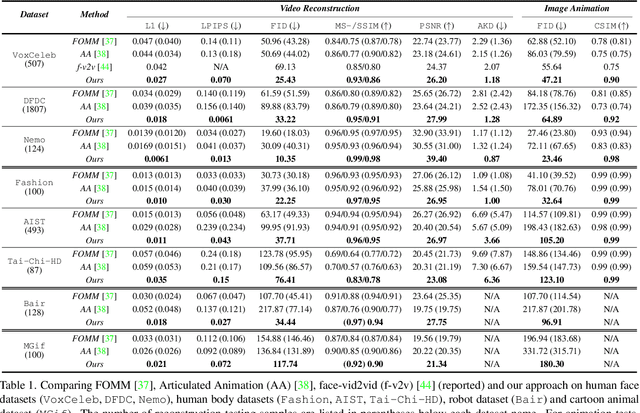
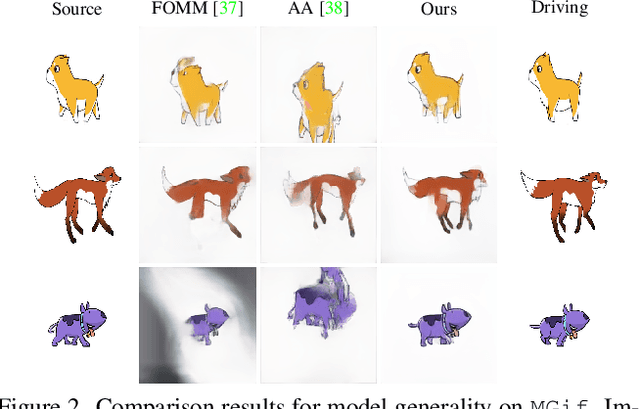
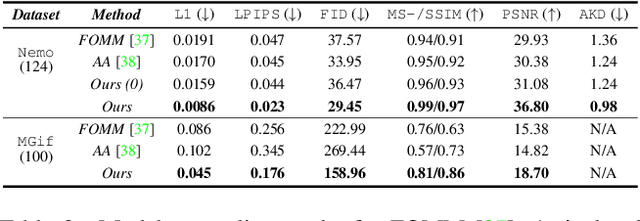
Image animation transfers the motion of a driving video to a static object in a source image, while keeping the source identity unchanged. Great progress has been made in unsupervised motion transfer recently, where no labelled data or ground truth domain priors are needed. However, current unsupervised approaches still struggle when there are large motion or viewpoint discrepancies between the source and driving images. In this paper, we introduce three measures that we found to be effective for overcoming such large viewpoint changes. Firstly, to achieve more fine-grained motion deformation fields, we propose to apply Neural-ODEs for parametrizing the evolution dynamics of the motion transfer from source to driving. Secondly, to handle occlusions caused by large viewpoint and motion changes, we take advantage of the appearance flow obtained from the source image itself ("self-appearance"), which essentially "borrows" similar structures from other regions of an image to inpaint missing regions. Finally, our framework is also able to leverage the information from additional reference views which help to drive the source identity in spite of varying motion state. Extensive experiments demonstrate that our approach outperforms the state-of-the-arts by a significant margin (~40%), across six benchmarks varying from human faces, human bodies to robots and cartoon characters. Model generality analysis indicates that our approach generalises the best across different object categories as well.
Dance Dance Generation: Motion Transfer for Internet Videos
Mar 30, 2019
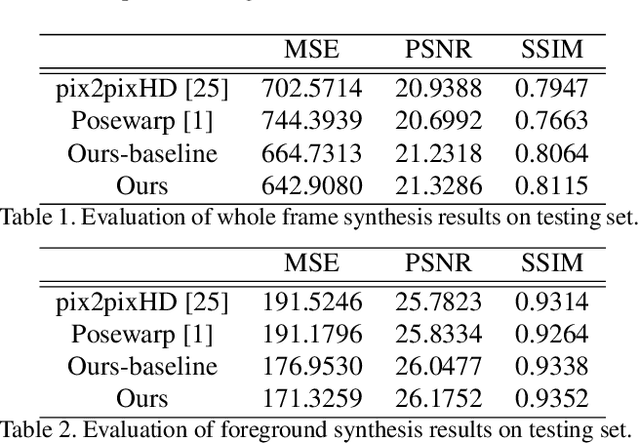

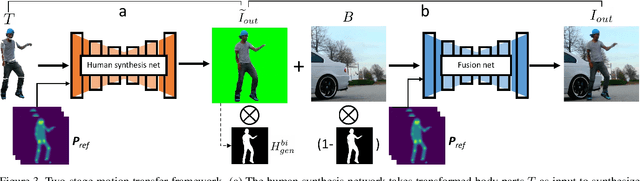
This work presents computational methods for transferring body movements from one person to another with videos collected in the wild. Specifically, we train a personalized model on a single video from the Internet which can generate videos of this target person driven by the motions of other people. Our model is built on two generative networks: a human (foreground) synthesis net which generates photo-realistic imagery of the target person in a novel pose, and a fusion net which combines the generated foreground with the scene (background), adding shadows or reflections as needed to enhance realism. We validate the the efficacy of our proposed models over baselines with qualitative and quantitative evaluations as well as a subjective test.
Visual to Sound: Generating Natural Sound for Videos in the Wild
Jun 01, 2018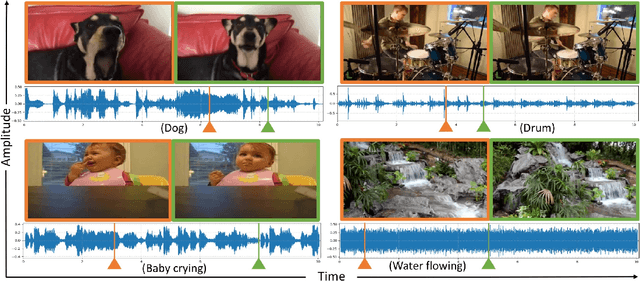

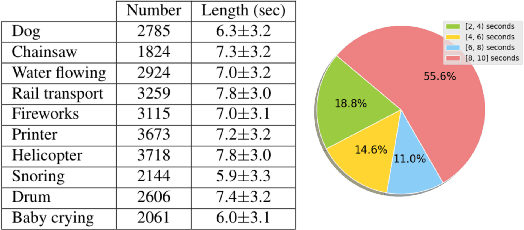
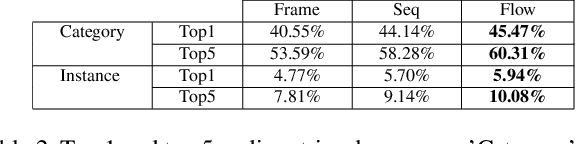
As two of the five traditional human senses (sight, hearing, taste, smell, and touch), vision and sound are basic sources through which humans understand the world. Often correlated during natural events, these two modalities combine to jointly affect human perception. In this paper, we pose the task of generating sound given visual input. Such capabilities could help enable applications in virtual reality (generating sound for virtual scenes automatically) or provide additional accessibility to images or videos for people with visual impairments. As a first step in this direction, we apply learning-based methods to generate raw waveform samples given input video frames. We evaluate our models on a dataset of videos containing a variety of sounds (such as ambient sounds and sounds from people/animals). Our experiments show that the generated sounds are fairly realistic and have good temporal synchronization with the visual inputs.
Image2GIF: Generating Cinemagraphs using Recurrent Deep Q-Networks
Jan 27, 2018

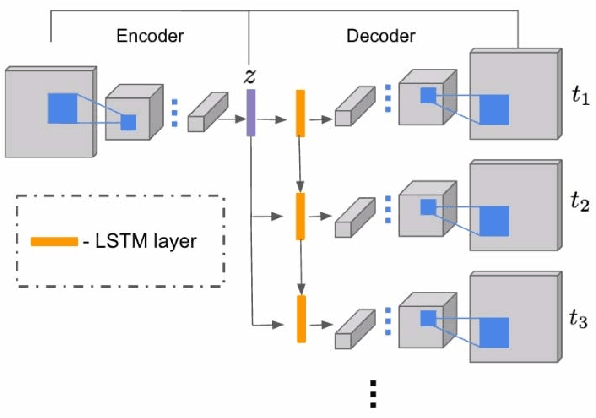

Given a still photograph, one can imagine how dynamic objects might move against a static background. This idea has been actualized in the form of cinemagraphs, where the motion of particular objects within a still image is repeated, giving the viewer a sense of animation. In this paper, we learn computational models that can generate cinemagraph sequences automatically given a single image. To generate cinemagraphs, we explore combining generative models with a recurrent neural network and deep Q-networks to enhance the power of sequence generation. To enable and evaluate these models we make use of two datasets, one synthetically generated and the other containing real video generated cinemagraphs. Both qualitative and quantitative evaluations demonstrate the effectiveness of our models on the synthetic and real datasets.