 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Preference Optimization with Multi-Sample Comparisons
Oct 16, 2024Recent advancements in generative models, particularly large language models (LLMs) and diffusion models, have been driven by extensive pretraining on large datasets followed by post-training. However, current post-training methods such as reinforcement learning from human feedback (RLHF) and direct alignment from preference methods (DAP) primarily utilize single-sample comparisons. These approaches often fail to capture critical characteristics such as generative diversity and bias, which are more accurately assessed through multiple samples. To address these limitations, we introduce a novel approach that extends post-training to include multi-sample comparisons. To achieve this, we propose Multi-sample Direct Preference Optimization (mDPO) and Multi-sample Identity Preference Optimization (mIPO). These methods improve traditional DAP methods by focusing on group-wise characteristics. Empirically, we demonstrate that multi-sample comparison is more effective in optimizing collective characteristics~(e.g., diversity and bias) for generative models than single-sample comparison. Additionally, our findings suggest that multi-sample comparisons provide a more robust optimization framework, particularly for dataset with label noise.
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Apr 08, 2024



With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
A Unified Model for Tracking and Image-Video Detection Has More Power
Nov 20, 2022



Objection detection (OD) has been one of the most fundamental tasks in computer vision. Recent developments in deep learning have pushed the performance of image OD to new heights by learning-based, data-driven approaches. On the other hand, video OD remains less explored, mostly due to much more expensive data annotation needs. At the same time, multi-object tracking (MOT) which requires reasoning about track identities and spatio-temporal trajectories, shares similar spirits with video OD. However, most MOT datasets are class-specific (e.g., person-annotated only), which constrains a model's flexibility to perform tracking on other objects. We propose TrIVD (Tracking and Image-Video Detection), the first framework that unifies image OD, video OD, and MOT within one end-to-end model. To handle the discrepancies and semantic overlaps across datasets, TrIVD formulates detection/tracking as grounding and reasons about object categories via visual-text alignments. The unified formulation enables cross-dataset, multi-task training, and thus equips TrIVD with the ability to leverage frame-level features, video-level spatio-temporal relations, as well as track identity associations. With such joint training, we can now extend the knowledge from OD data, that comes with much richer object category annotations, to MOT and achieve zero-shot tracking capability. Experiments demonstrate that TrIVD achieves state-of-the-art performances across all image/video OD and MOT tasks.
Object-Centric Unsupervised Image Captioning
Dec 02, 2021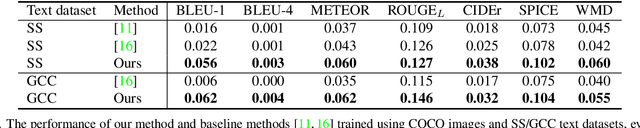



Training an image captioning model in an unsupervised manner without utilizing annotated image-caption pairs is an important step towards tapping into a wider corpus of text and images. In the supervised setting, image-caption pairs are "well-matched", where all objects mentioned in the sentence appear in the corresponding image. These pairings are, however, not available in the unsupervised setting. To overcome this, a main school of research that has been shown to be effective in overcoming this is to construct pairs from the images and texts in the training set according to their overlap of objects. Unlike in the supervised setting, these constructed pairings are however not guaranteed to have fully overlapping set of objects. Our work in this paper overcomes this by harvesting objects corresponding to a given sentence from the training set, even if they don't belong to the same image. When used as input to a transformer, such mixture of objects enable larger if not full object coverage, and when supervised by the corresponding sentence, produced results that outperform current state of the art unsupervised methods by a significant margin. Building upon this finding, we further show that (1) additional information on relationship between objects and attributes of objects also helps in boosting performance; and (2) our method also extends well to non-English image captioning, which usually suffers from a scarcer level of annotations. Our findings are supported by strong empirical results.
Self-appearance-aided Differential Evolution for Motion Transfer
Oct 09, 2021
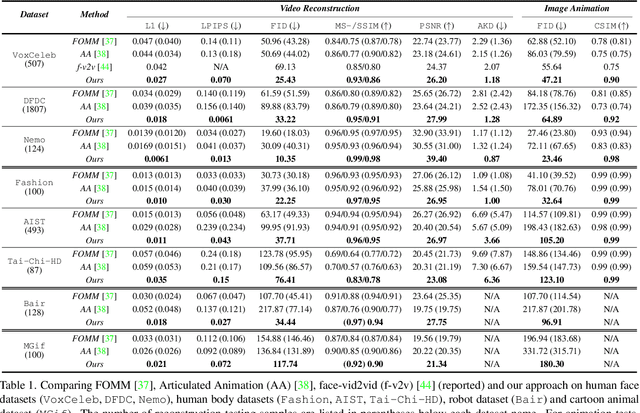
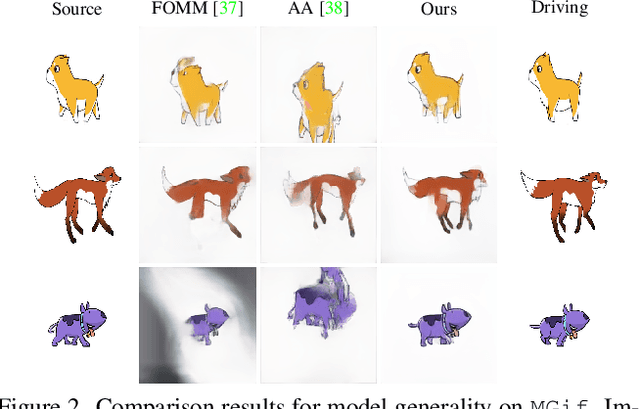
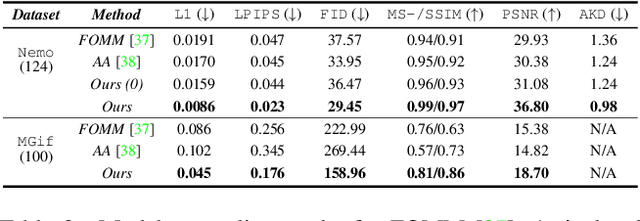
Image animation transfers the motion of a driving video to a static object in a source image, while keeping the source identity unchanged. Great progress has been made in unsupervised motion transfer recently, where no labelled data or ground truth domain priors are needed. However, current unsupervised approaches still struggle when there are large motion or viewpoint discrepancies between the source and driving images. In this paper, we introduce three measures that we found to be effective for overcoming such large viewpoint changes. Firstly, to achieve more fine-grained motion deformation fields, we propose to apply Neural-ODEs for parametrizing the evolution dynamics of the motion transfer from source to driving. Secondly, to handle occlusions caused by large viewpoint and motion changes, we take advantage of the appearance flow obtained from the source image itself ("self-appearance"), which essentially "borrows" similar structures from other regions of an image to inpaint missing regions. Finally, our framework is also able to leverage the information from additional reference views which help to drive the source identity in spite of varying motion state. Extensive experiments demonstrate that our approach outperforms the state-of-the-arts by a significant margin (~40%), across six benchmarks varying from human faces, human bodies to robots and cartoon characters. Model generality analysis indicates that our approach generalises the best across different object categories as well.
Unsupervised Deep Metric Learning via Auxiliary Rotation Loss
Nov 16, 2019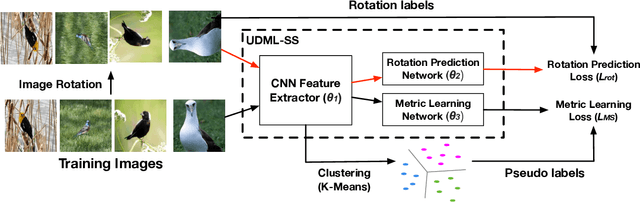
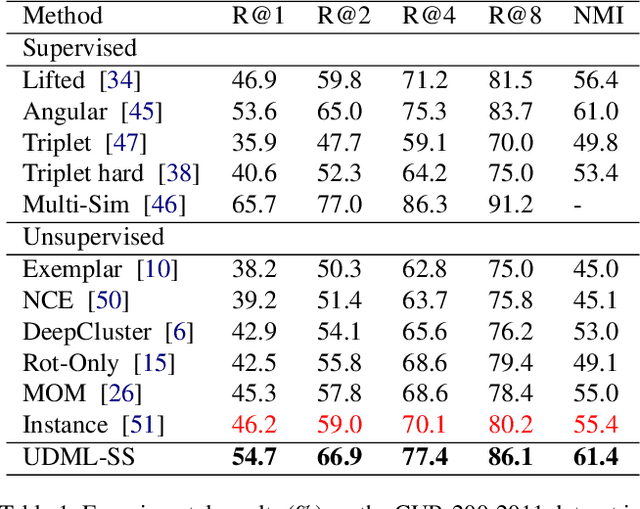

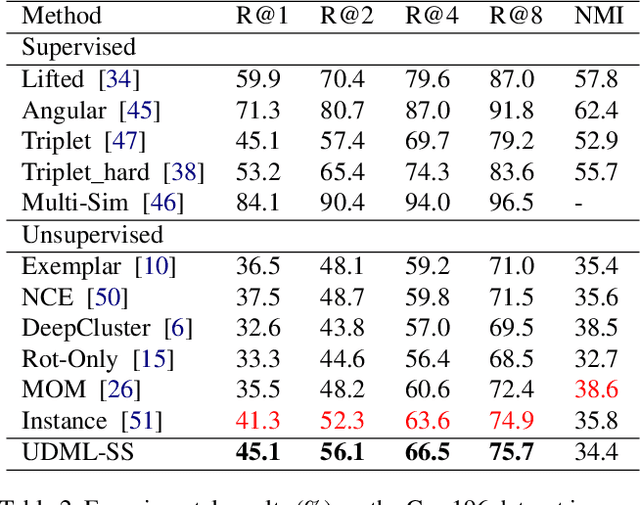
Deep metric learning is an important area due to its applicability to many domains such as image retrieval and person re-identification. The main drawback of such models is the necessity for labeled data. In this work, we propose to generate pseudo-labels for deep metric learning directly from clustering assignment and we introduce unsupervised deep metric learning (UDML) regularized by a self-supervision (SS) task. In particular, we propose to regularize the training process by predicting image rotations. Our method (UDML-SS) jointly learns discriminative embeddings, unsupervised clustering assignments of the embeddings, as well as a self-supervised pretext task. UDML-SS iteratively cluster embeddings using traditional clustering algorithm (e.g., k-means), and sampling training pairs based on the cluster assignment for metric learning, while optimizing self-supervised pretext task in a multi-task fashion. The role of self-supervision is to stabilize the training process and encourages the model to learn meaningful feature representations that are not distorted due to unreliable clustering assignments. The proposed method performs well on standard benchmarks for metric learning, where it outperforms current state-of-the-art approaches by a large margin and it also shows competitive performance with various metric learning loss functions.