 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Visual Delta Generator with Large Multi-modal Models for Semi-supervised Composed Image Retrieval
Apr 23, 2024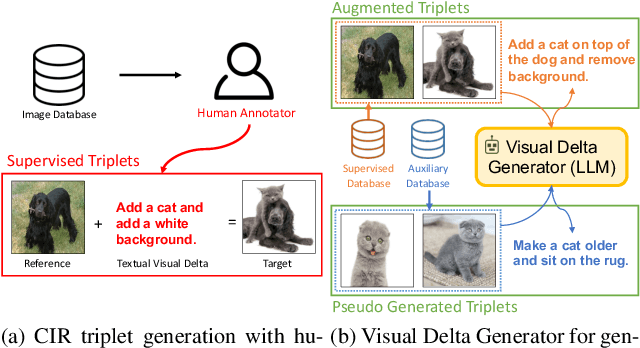
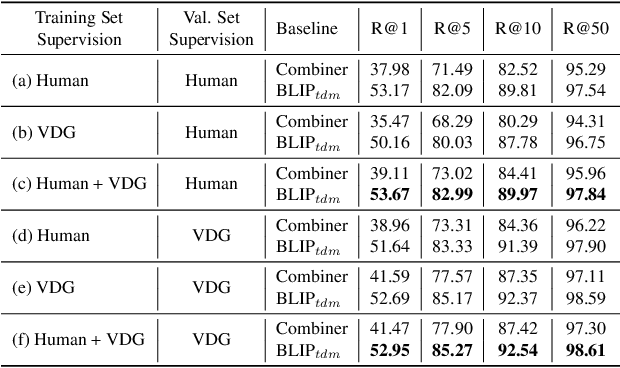
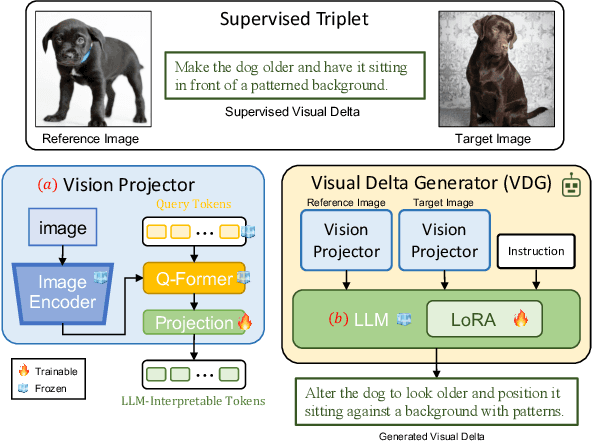
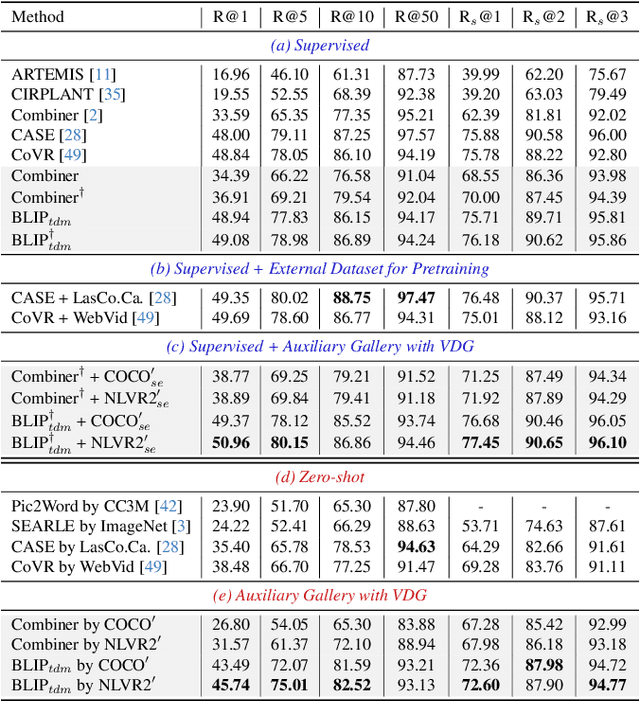
Composed Image Retrieval (CIR) is a task that retrieves images similar to a query, based on a provided textual modification. Current techniques rely on supervised learning for CIR models using labeled triplets of the reference image, text, target image. These specific triplets are not as commonly available as simple image-text pairs, limiting the widespread use of CIR and its scalability. On the other hand, zero-shot CIR can be relatively easily trained with image-caption pairs without considering the image-to-image relation, but this approach tends to yield lower accuracy. We propose a new semi-supervised CIR approach where we search for a reference and its related target images in auxiliary data and learn our large language model-based Visual Delta Generator (VDG) to generate text describing the visual difference (i.e., visual delta) between the two. VDG, equipped with fluent language knowledge and being model agnostic, can generate pseudo triplets to boost the performance of CIR models. Our approach significantly improves the existing supervised learning approaches and achieves state-of-the-art results on the CIR benchmarks.
On the Versatile Uses of Partial Distance Correlation in Deep Learning
Jul 20, 2022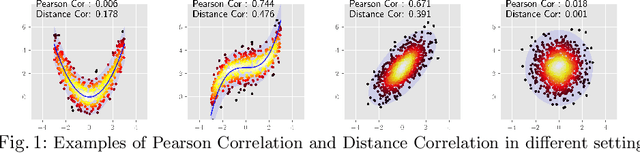
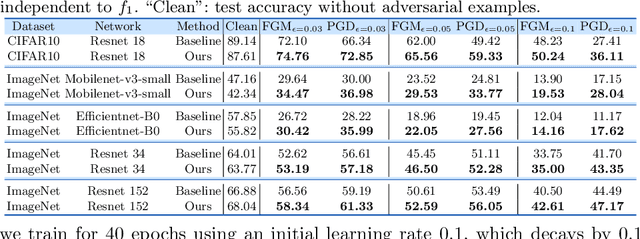
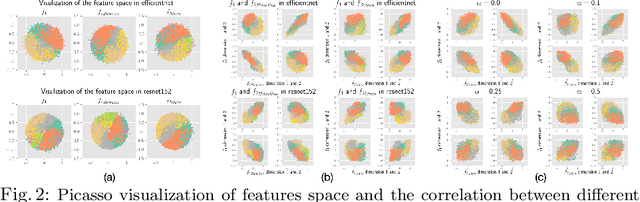
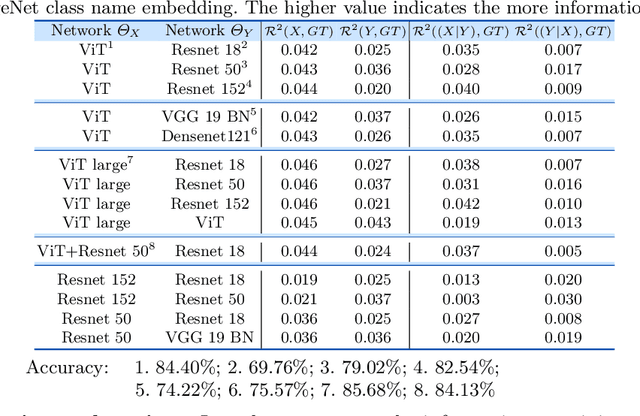
Comparing the functional behavior of neural network models, whether it is a single network over time or two (or more networks) during or post-training, is an essential step in understanding what they are learning (and what they are not), and for identifying strategies for regularization or efficiency improvements. Despite recent progress, e.g., comparing vision transformers to CNNs, systematic comparison of function, especially across different networks, remains difficult and is often carried out layer by layer. Approaches such as canonical correlation analysis (CCA) are applicable in principle, but have been sparingly used so far. In this paper, we revisit a (less widely known) from statistics, called distance correlation (and its partial variant), designed to evaluate correlation between feature spaces of different dimensions. We describe the steps necessary to carry out its deployment for large scale models -- this opens the door to a surprising array of applications ranging from conditioning one deep model w.r.t. another, learning disentangled representations as well as optimizing diverse models that would directly be more robust to adversarial attacks. Our experiments suggest a versatile regularizer (or constraint) with many advantages, which avoids some of the common difficulties one faces in such analyses. Code is at https://github.com/zhenxingjian/Partial_Distance_Correlation.
Object-Centric Unsupervised Image Captioning
Dec 02, 2021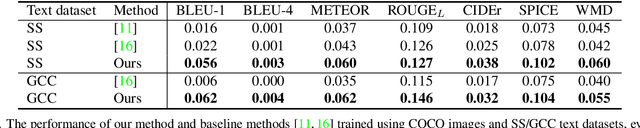



Training an image captioning model in an unsupervised manner without utilizing annotated image-caption pairs is an important step towards tapping into a wider corpus of text and images. In the supervised setting, image-caption pairs are "well-matched", where all objects mentioned in the sentence appear in the corresponding image. These pairings are, however, not available in the unsupervised setting. To overcome this, a main school of research that has been shown to be effective in overcoming this is to construct pairs from the images and texts in the training set according to their overlap of objects. Unlike in the supervised setting, these constructed pairings are however not guaranteed to have fully overlapping set of objects. Our work in this paper overcomes this by harvesting objects corresponding to a given sentence from the training set, even if they don't belong to the same image. When used as input to a transformer, such mixture of objects enable larger if not full object coverage, and when supervised by the corresponding sentence, produced results that outperform current state of the art unsupervised methods by a significant margin. Building upon this finding, we further show that (1) additional information on relationship between objects and attributes of objects also helps in boosting performance; and (2) our method also extends well to non-English image captioning, which usually suffers from a scarcer level of annotations. Our findings are supported by strong empirical results.
Neural TMDlayer: Modeling Instantaneous flow of features via SDE Generators
Aug 19, 2021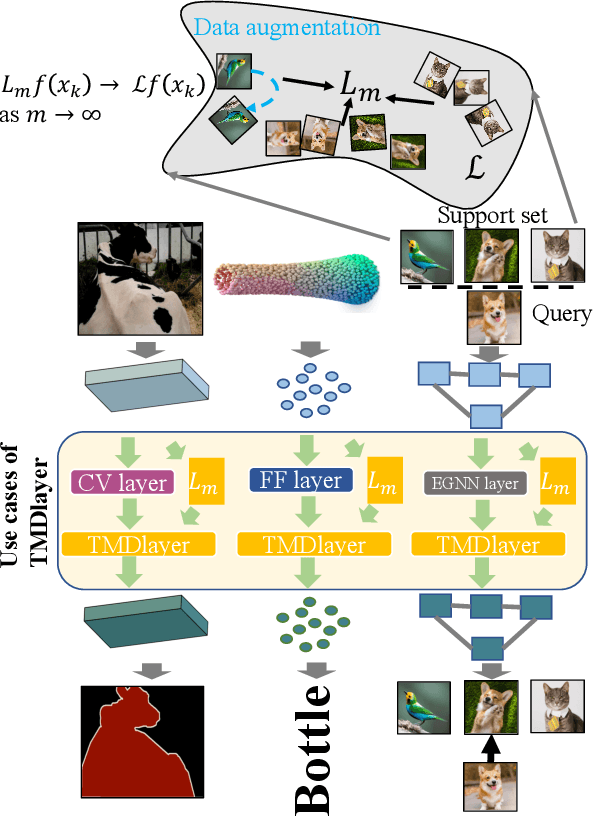



We study how stochastic differential equation (SDE) based ideas can inspire new modifications to existing algorithms for a set of problems in computer vision. Loosely speaking, our formulation is related to both explicit and implicit strategies for data augmentation and group equivariance, but is derived from new results in the SDE literature on estimating infinitesimal generators of a class of stochastic processes. If and when there is nominal agreement between the needs of an application/task and the inherent properties and behavior of the types of processes that we can efficiently handle, we obtain a very simple and efficient plug-in layer that can be incorporated within any existing network architecture, with minimal modification and only a few additional parameters. We show promising experiments on a number of vision tasks including few shot learning, point cloud transformers and deep variational segmentation obtaining efficiency or performance improvements.
An Online Riemannian PCA for Stochastic Canonical Correlation Analysis
Jun 08, 2021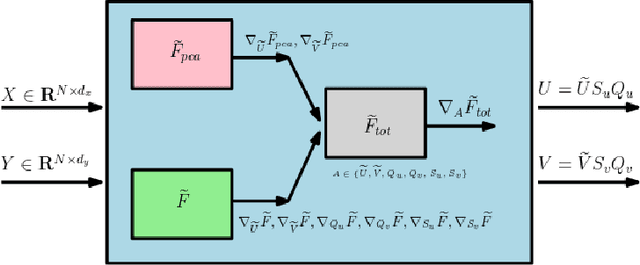
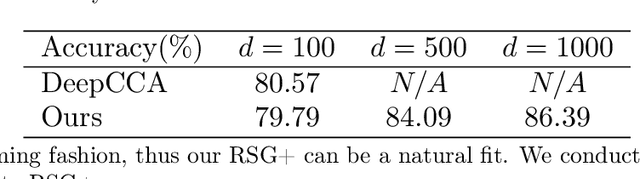
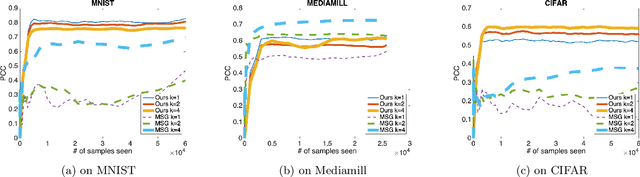
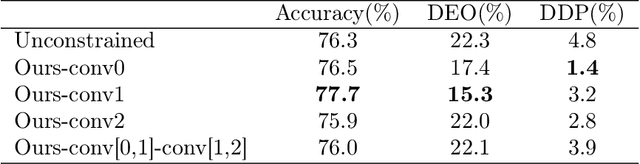
We present an efficient stochastic algorithm (RSG+) for canonical correlation analysis (CCA) using a reparametrization of the projection matrices. We show how this reparametrization (into structured matrices), simple in hindsight, directly presents an opportunity to repurpose/adjust mature techniques for numerical optimization on Riemannian manifolds. Our developments nicely complement existing methods for this problem which either require $O(d^3)$ time complexity per iteration with $O(\frac{1}{\sqrt{t}})$ convergence rate (where $d$ is the dimensionality) or only extract the top $1$ component with $O(\frac{1}{t})$ convergence rate. In contrast, our algorithm offers a strict improvement for this classical problem: it achieves $O(d^2k)$ runtime complexity per iteration for extracting the top $k$ canonical components with $O(\frac{1}{t})$ convergence rate. While the paper primarily focuses on the formulation and technical analysis of its properties, our experiments show that the empirical behavior on common datasets is quite promising. We also explore a potential application in training fair models where the label of protected attribute is missing or otherwise unavailable.
Connecting What to Say With Where to Look by Modeling Human Attention Traces
May 12, 2021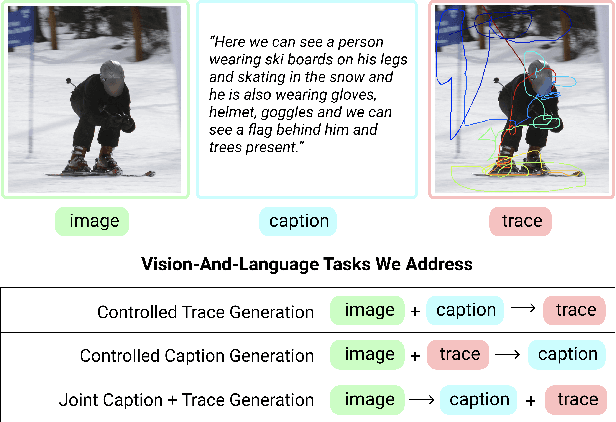

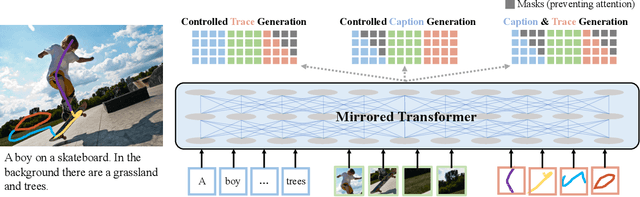
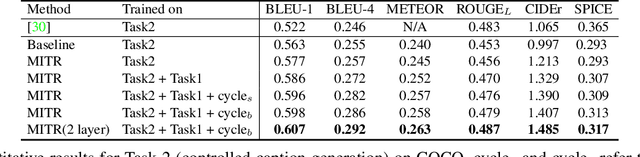
We introduce a unified framework to jointly model images, text, and human attention traces. Our work is built on top of the recent Localized Narratives annotation framework [30], where each word of a given caption is paired with a mouse trace segment. We propose two novel tasks: (1) predict a trace given an image and caption (i.e., visual grounding), and (2) predict a caption and a trace given only an image. Learning the grounding of each word is challenging, due to noise in the human-provided traces and the presence of words that cannot be meaningfully visually grounded. We present a novel model architecture that is jointly trained on dual tasks (controlled trace generation and controlled caption generation). To evaluate the quality of the generated traces, we propose a local bipartite matching (LBM) distance metric which allows the comparison of two traces of different lengths. Extensive experiments show our model is robust to the imperfect training data and outperforms the baselines by a clear margin. Moreover, we demonstrate that our model pre-trained on the proposed tasks can be also beneficial to the downstream task of COCO's guided image captioning. Our code and project page are publicly available.
Graph Neural Networks to Predict Customer Satisfaction Following Interactions with a Corporate Call Center
Jan 31, 2021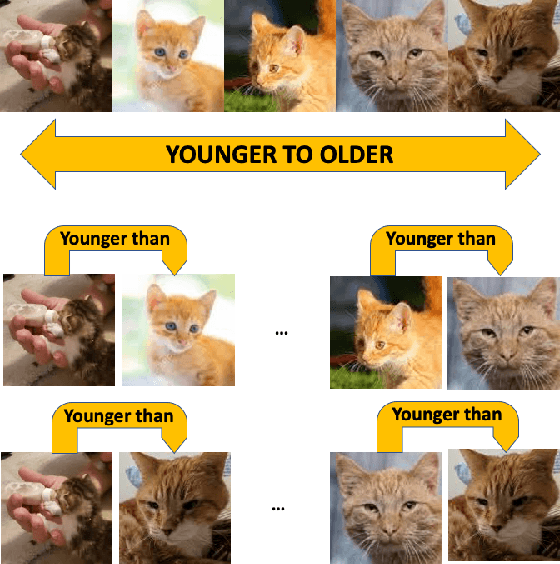


Customer satisfaction is an important factor in creating and maintaining long-term relationships with customers. Near real-time identification of potentially dissatisfied customers following phone calls can provide organizations the opportunity to take meaningful interventions and to foster ongoing customer satisfaction and loyalty. This work describes a fully operational system we have developed at a large US company for predicting customer satisfaction following incoming phone calls. The system takes as an input speech-to-text transcriptions of calls and predicts call satisfaction reported by customers on post-call surveys (scale from 1 to 10). Because of its ordinal, subjective, and often highly-skewed nature, predicting survey scores is not a trivial task and presents several modeling challenges. We introduce a graph neural network (GNN) approach that takes into account the comparative nature of the problem by considering the relative scores among batches, instead of only pairs of calls when training. This approach produces more accurate predictions than previous approaches including standard regression and classification models that directly fit the survey scores with call data. Our proposed approach can be easily generalized to other customer satisfaction prediction problems.
Physarum Powered Differentiable Linear Programming Layers and Applications
Apr 30, 2020

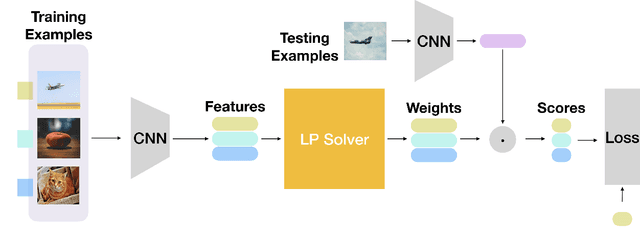
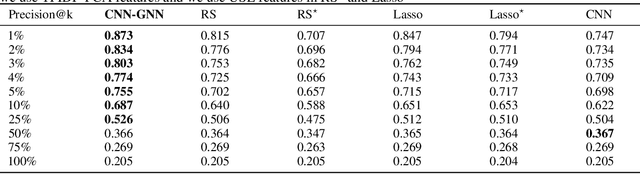
Consider a learning algorithm, which involves an internal call to an optimization routine such as a generalized eigenvalue problem, a cone programming problem or even sorting. Integrating such a method as layers within a trainable deep network in a numerically stable way is not simple -- for instance, only recently, strategies have emerged for eigendecomposition and differentiable sorting. We propose an efficient and differentiable solver for general linear programming problems which can be used in a plug and play manner within deep neural networks as a layer. Our development is inspired by a fascinating but not widely used link between dynamics of slime mold (physarum) and mathematical optimization schemes such as steepest descent. We describe our development and demonstrate the use of our solver in a video object segmentation task and meta-learning for few-shot learning. We review the relevant known results and provide a technical analysis describing its applicability for our use cases. Our solver performs comparably with a customized projected gradient descent method on the first task and outperforms the very recently proposed differentiable CVXPY solver on the second task. Experiments show that our solver converges quickly without the need for a feasible initial point. Interestingly, our scheme is easy to implement and can easily serve as layers whenever a learning procedure needs a fast approximate solution to a LP, within a larger network.
Fooling Computer Vision into Inferring the Wrong Body Mass Index
May 16, 2019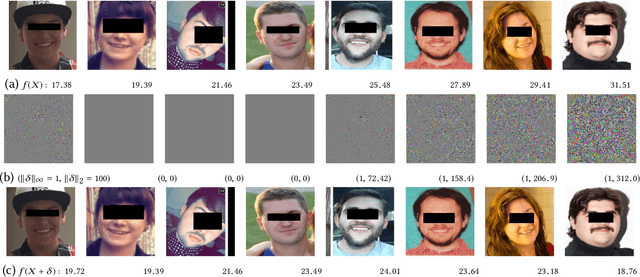
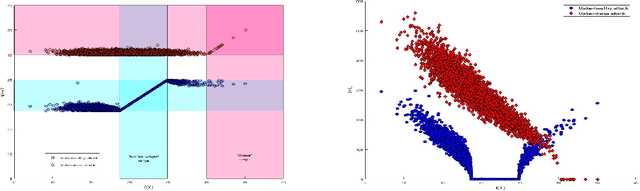
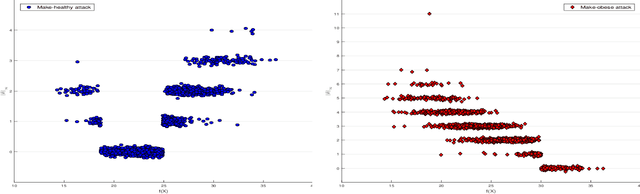
Recently it's been shown that neural networks can use images of human faces to accurately predict Body Mass Index (BMI), a widely used health indicator. In this paper we demonstrate that a neural network performing BMI inference is indeed vulnerable to test-time adversarial attacks. This extends test-time adversarial attacks from classification tasks to regression. The application we highlight is BMI inference in the insurance industry, where such adversarial attacks imply a danger of insurance fraud.