 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
Spherical Linear Interpolation and Text-Anchoring for Zero-shot Composed Image Retrieval
May 01, 2024Composed Image Retrieval (CIR) is a complex task that retrieves images using a query, which is configured with an image and a caption that describes desired modifications to that image. Supervised CIR approaches have shown strong performance, but their reliance on expensive manually-annotated datasets restricts their scalability and broader applicability. To address these issues, previous studies have proposed pseudo-word token-based Zero-Shot CIR (ZS-CIR) methods, which utilize a projection module to map images to word tokens. However, we conjecture that this approach has a downside: the projection module distorts the original image representation and confines the resulting composed embeddings to the text-side. In order to resolve this, we introduce a novel ZS-CIR method that uses Spherical Linear Interpolation (Slerp) to directly merge image and text representations by identifying an intermediate embedding of both. Furthermore, we introduce Text-Anchored-Tuning (TAT), a method that fine-tunes the image encoder while keeping the text encoder fixed. TAT closes the modality gap between images and text, making the Slerp process much more effective. Notably, the TAT method is not only efficient in terms of the scale of the training dataset and training time, but it also serves as an excellent initial checkpoint for training supervised CIR models, thereby highlighting its wider potential. The integration of the Slerp-based ZS-CIR with a TAT-tuned model enables our approach to deliver state-of-the-art retrieval performance across CIR benchmarks.
Visual Delta Generator with Large Multi-modal Models for Semi-supervised Composed Image Retrieval
Apr 23, 2024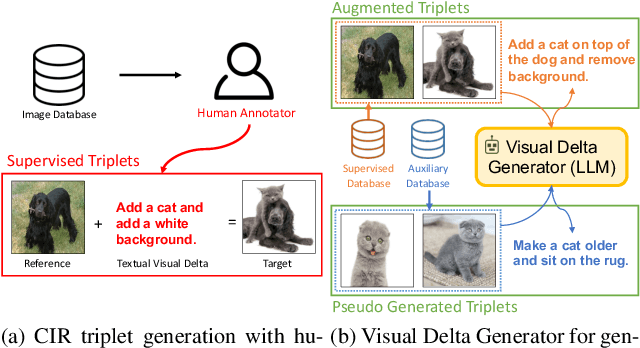
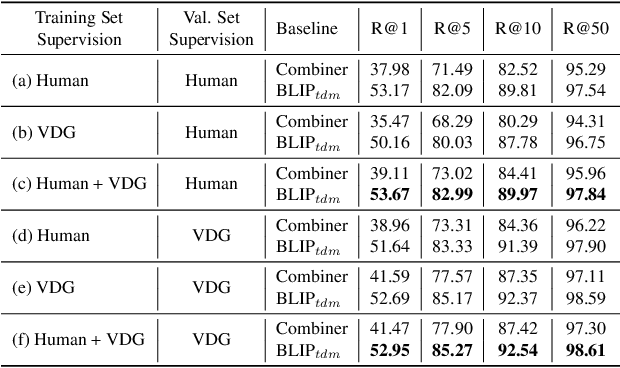
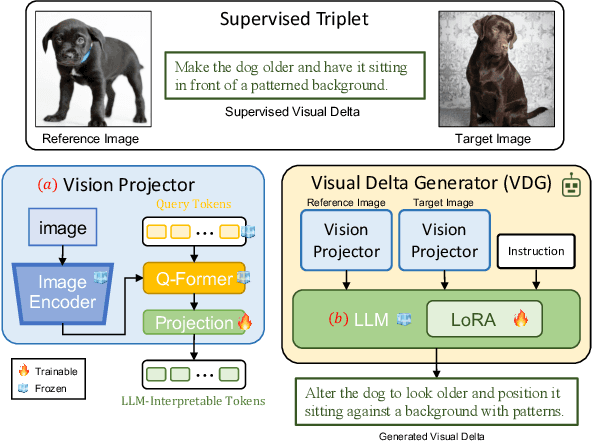
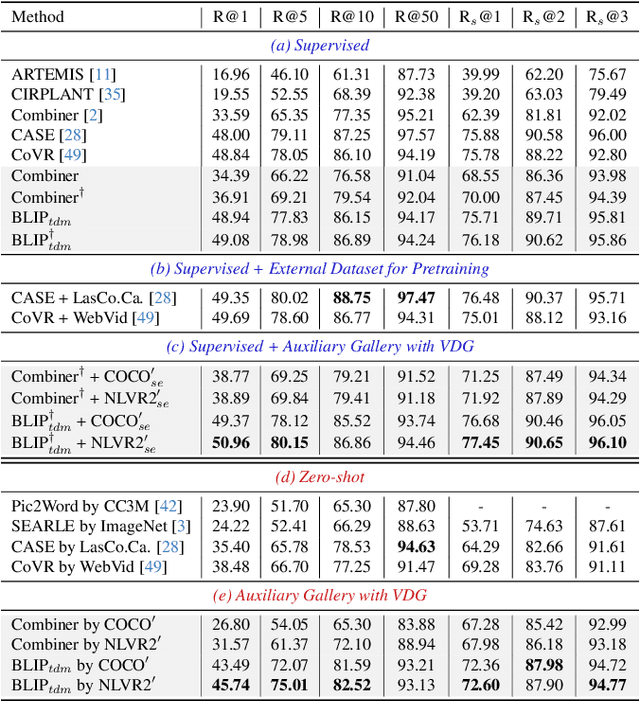
Composed Image Retrieval (CIR) is a task that retrieves images similar to a query, based on a provided textual modification. Current techniques rely on supervised learning for CIR models using labeled triplets of the reference image, text, target image. These specific triplets are not as commonly available as simple image-text pairs, limiting the widespread use of CIR and its scalability. On the other hand, zero-shot CIR can be relatively easily trained with image-caption pairs without considering the image-to-image relation, but this approach tends to yield lower accuracy. We propose a new semi-supervised CIR approach where we search for a reference and its related target images in auxiliary data and learn our large language model-based Visual Delta Generator (VDG) to generate text describing the visual difference (i.e., visual delta) between the two. VDG, equipped with fluent language knowledge and being model agnostic, can generate pseudo triplets to boost the performance of CIR models. Our approach significantly improves the existing supervised learning approaches and achieves state-of-the-art results on the CIR benchmarks.
A recommender for the management of chronic pain in patients undergoing spinal cord stimulation
Sep 06, 2023



Spinal cord stimulation (SCS) is a therapeutic approach used for the management of chronic pain. It involves the delivery of electrical impulses to the spinal cord via an implanted device, which when given suitable stimulus parameters can mask or block pain signals. Selection of optimal stimulation parameters usually happens in the clinic under the care of a provider whereas at-home SCS optimization is managed by the patient. In this paper, we propose a recommender system for the management of pain in chronic pain patients undergoing SCS. In particular, we use a contextual multi-armed bandit (CMAB) approach to develop a system that recommends SCS settings to patients with the aim of improving their condition. These recommendations, sent directly to patients though a digital health ecosystem, combined with a patient monitoring system closes the therapeutic loop around a chronic pain patient over their entire patient journey. We evaluated the system in a cohort of SCS-implanted ENVISION study subjects (Clinicaltrials.gov ID: NCT03240588) using a combination of quality of life metrics and Patient States (PS), a novel measure of holistic outcomes. SCS recommendations provided statistically significant improvement in clinical outcomes (pain and/or QoL) in 85\% of all subjects (N=21). Among subjects in moderate PS (N=7) prior to receiving recommendations, 100\% showed statistically significant improvements and 5/7 had improved PS dwell time. This analysis suggests SCS patients may benefit from SCS recommendations, resulting in additional clinical improvement on top of benefits already received from SCS therapy.
Open-Vocabulary Instance Segmentation via Robust Cross-Modal Pseudo-Labeling
Nov 24, 2021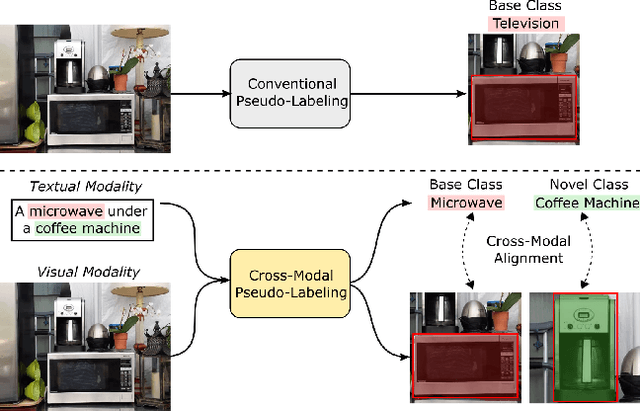
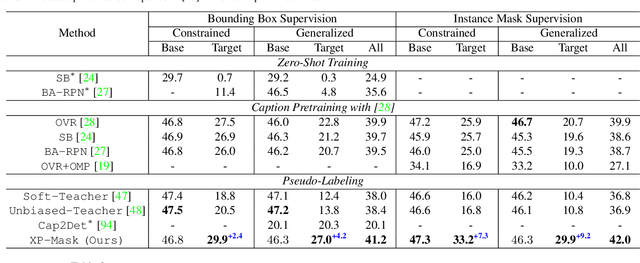
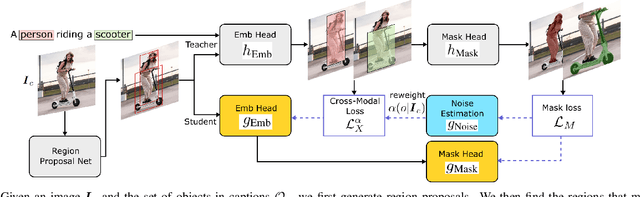
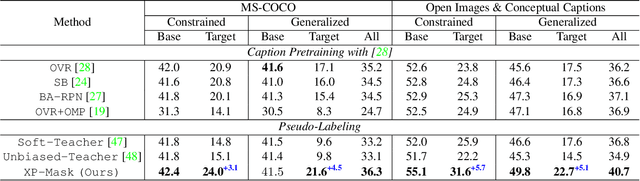
Open-vocabulary instance segmentation aims at segmenting novel classes without mask annotations. It is an important step toward reducing laborious human supervision. Most existing works first pretrain a model on captioned images covering many novel classes and then finetune it on limited base classes with mask annotations. However, the high-level textual information learned from caption pretraining alone cannot effectively encode the details required for pixel-wise segmentation. To address this, we propose a cross-modal pseudo-labeling framework, which generates training pseudo masks by aligning word semantics in captions with visual features of object masks in images. Thus, our framework is capable of labeling novel classes in captions via their word semantics to self-train a student model. To account for noises in pseudo masks, we design a robust student model that selectively distills mask knowledge by estimating the mask noise levels, hence mitigating the adverse impact of noisy pseudo masks. By extensive experiments, we show the effectiveness of our framework, where we significantly improve mAP score by 4.5% on MS-COCO and 5.1% on the large-scale Open Images & Conceptual Captions datasets compared to the state-of-the-art.
Compositional Fine-Grained Low-Shot Learning
May 21, 2021

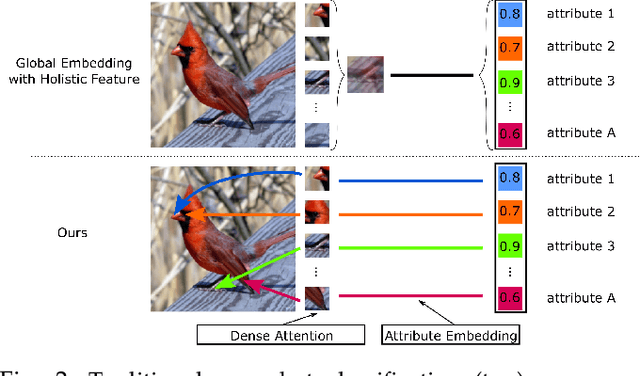

We develop a novel compositional generative model for zero- and few-shot learning to recognize fine-grained classes with a few or no training samples. Our key observation is that generating holistic features for fine-grained classes fails to capture small attribute differences between classes. Therefore, we propose a feature composition framework that learns to extract attribute features from training samples and combines them to construct fine-grained features for rare and unseen classes. Feature composition allows us to not only selectively compose features of every class from only relevant training samples, but also obtain diversity among composed features via changing samples used for the composition. In addition, instead of building holistic features for classes, we use our attribute features to form dense representations capable of capturing fine-grained attribute details of classes. We propose a training scheme that uses a discriminative model to construct features that are subsequently used to train the model itself. Therefore, we directly train the discriminative model on the composed features without learning a separate generative model. We conduct experiments on four popular datasets of DeepFashion, AWA2, CUB, and SUN, showing the effectiveness of our method.