 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Attribute-Object Compositions
May 24, 2021

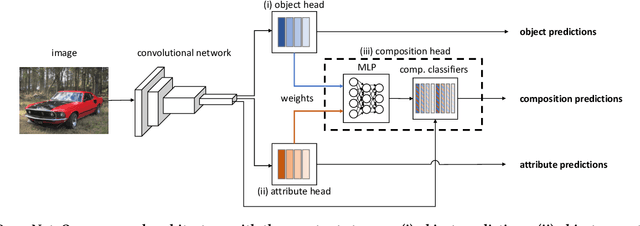
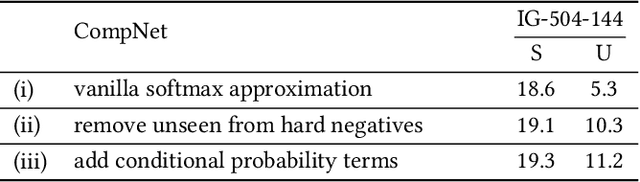
We study the problem of learning how to predict attribute-object compositions from images, and its generalization to unseen compositions missing from the training data. To the best of our knowledge, this is a first large-scale study of this problem, involving hundreds of thousands of compositions. We train our framework with images from Instagram using hashtags as noisy weak supervision. We make careful design choices for data collection and modeling, in order to handle noisy annotations and unseen compositions. Finally, extensive evaluations show that learning to compose classifiers outperforms late fusion of individual attribute and object predictions, especially in the case of unseen attribute-object pairs.
Connecting What to Say With Where to Look by Modeling Human Attention Traces
May 12, 2021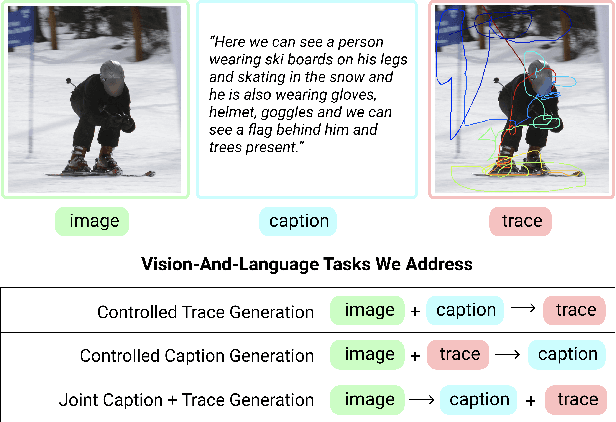

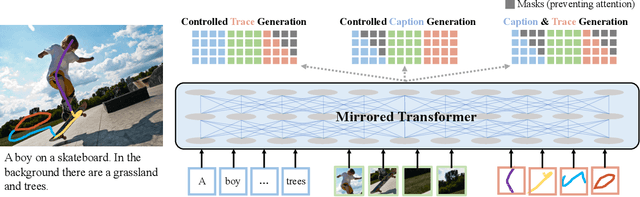
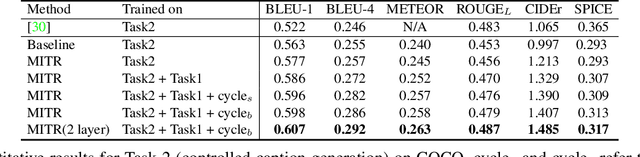
We introduce a unified framework to jointly model images, text, and human attention traces. Our work is built on top of the recent Localized Narratives annotation framework [30], where each word of a given caption is paired with a mouse trace segment. We propose two novel tasks: (1) predict a trace given an image and caption (i.e., visual grounding), and (2) predict a caption and a trace given only an image. Learning the grounding of each word is challenging, due to noise in the human-provided traces and the presence of words that cannot be meaningfully visually grounded. We present a novel model architecture that is jointly trained on dual tasks (controlled trace generation and controlled caption generation). To evaluate the quality of the generated traces, we propose a local bipartite matching (LBM) distance metric which allows the comparison of two traces of different lengths. Extensive experiments show our model is robust to the imperfect training data and outperforms the baselines by a clear margin. Moreover, we demonstrate that our model pre-trained on the proposed tasks can be also beneficial to the downstream task of COCO's guided image captioning. Our code and project page are publicly available.
Discovering Underground Maps from Fashion
Dec 04, 2020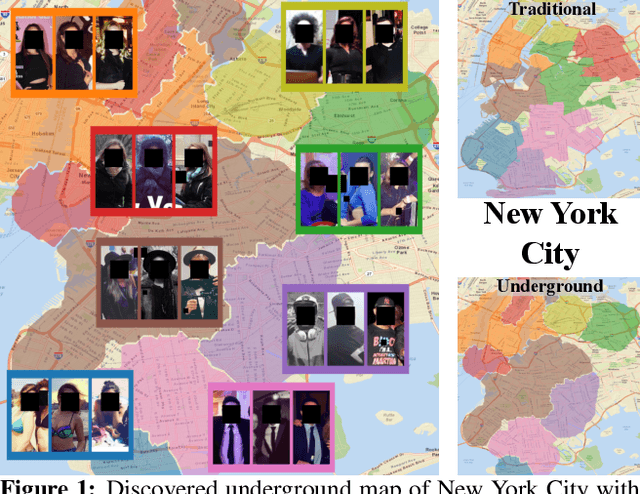
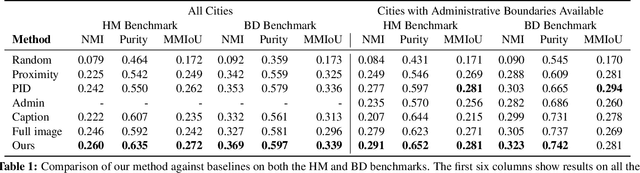
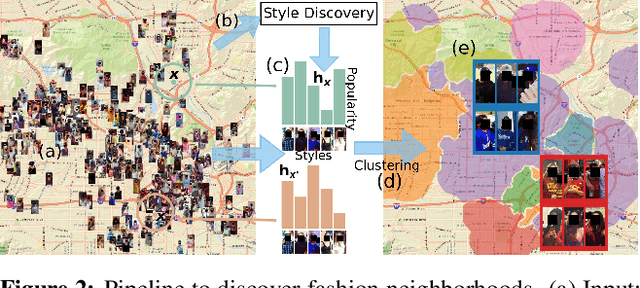
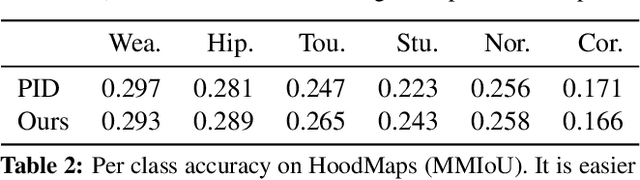
The fashion sense -- meaning the clothing styles people wear -- in a geographical region can reveal information about that region. For example, it can reflect the kind of activities people do there, or the type of crowds that frequently visit the region (e.g., tourist hot spot, student neighborhood, business center). We propose a method to automatically create underground neighborhood maps of cities by analyzing how people dress. Using publicly available images from across a city, our method finds neighborhoods with a similar fashion sense and segments the map without supervision. For 37 cities worldwide, we show promising results in creating good underground maps, as evaluated using experiments with human judges and underground map benchmarks derived from non-image data. Our approach further allows detecting distinct neighborhoods (what is the most unique region of LA?) and answering analogy questions between cities (what is the "Downtown LA" of Bogota?).
Attention-Based Query Expansion Learning
Jul 15, 2020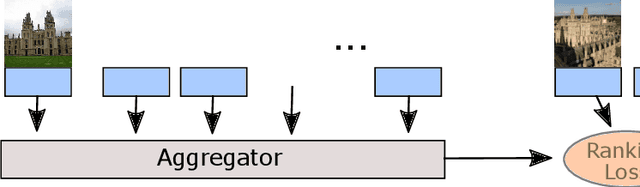

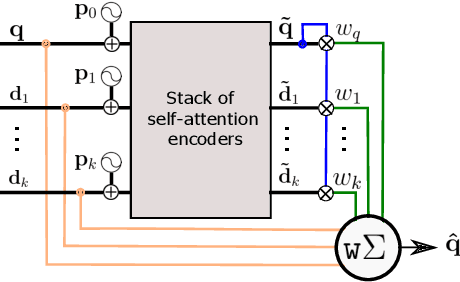
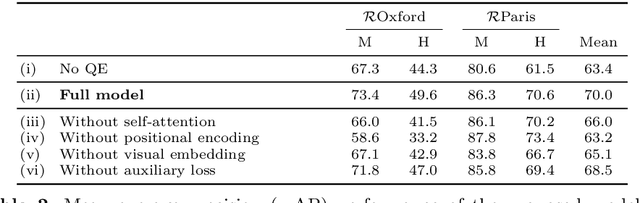
Query expansion is a technique widely used in image search consisting in combining highly ranked images from an original query into an expanded query that is then reissued, generally leading to increased recall and precision. An important aspect of query expansion is choosing an appropriate way to combine the images into a new query. Interestingly, despite the undeniable empirical success of query expansion, ad-hoc methods with different caveats have dominated the landscape, and not a lot of research has been done on learning how to do query expansion. In this paper we propose a more principled framework to query expansion, where one trains, in a discriminative manner, a model that learns how images should be aggregated to form the expanded query. Within this framework, we propose a model that leverages a self-attention mechanism to effectively learn how to transfer information between the different images before aggregating them. Our approach obtains higher accuracy than existing approaches on standard benchmarks. More importantly, our approach is the only one that consistently shows high accuracy under different regimes, overcoming caveats of existing methods.
Detailed Garment Recovery from a Single-View Image
Sep 12, 2016



Most recent garment capturing techniques rely on acquiring multiple views of clothing, which may not always be readily available, especially in the case of pre-existing photographs from the web. As an alternative, we pro- pose a method that is able to compute a rich and realistic 3D model of a human body and its outfits from a single photograph with little human in- teraction. Our algorithm is not only able to capture the global shape and geometry of the clothing, it can also extract small but important details of cloth, such as occluded wrinkles and folds. Unlike previous methods using full 3D information (i.e. depth, multi-view images, or sampled 3D geom- etry), our approach achieves detailed garment recovery from a single-view image by using statistical, geometric, and physical priors and a combina- tion of parameter estimation, semantic parsing, shape recovery, and physics- based cloth simulation. We demonstrate the effectiveness of our algorithm by re-purposing the reconstructed garments for virtual try-on and garment transfer applications, as well as cloth animation for digital characters.