 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM Agents for Earth Observation
Apr 16, 2025Earth Observation (EO) provides critical planetary data for environmental monitoring, disaster management, climate science, and other scientific domains. Here we ask: Are AI systems ready for reliable Earth Observation? We introduce \datasetnamenospace, a benchmark of 140 yes/no questions from NASA Earth Observatory articles across 13 topics and 17 satellite sensors. Using Google Earth Engine API as a tool, LLM agents can only achieve an accuracy of 33% because the code fails to run over 58% of the time. We improve the failure rate for open models by fine-tuning synthetic data, allowing much smaller models (Llama-3.1-8B) to achieve comparable accuracy to much larger ones (e.g., DeepSeek-R1). Taken together, our findings identify significant challenges to be solved before AI agents can automate earth observation, and suggest paths forward. The project page is available at https://iandrover.github.io/UnivEarth.
AllClear: A Comprehensive Dataset and Benchmark for Cloud Removal in Satellite Imagery
Oct 31, 2024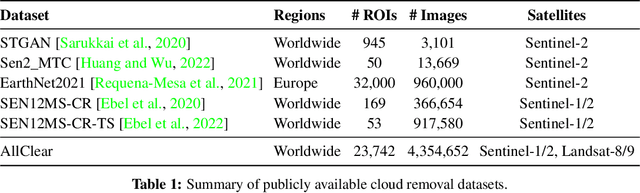
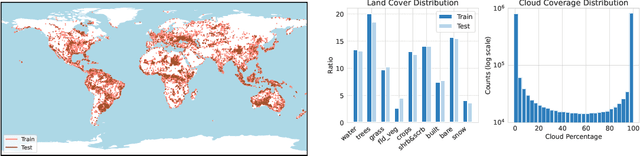
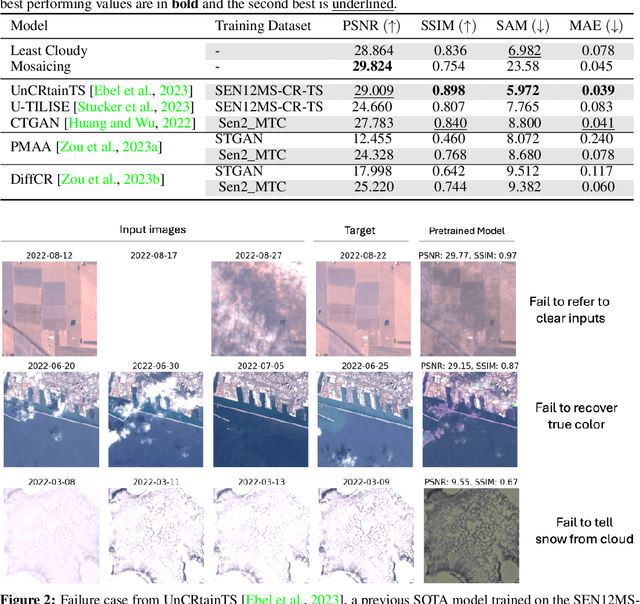
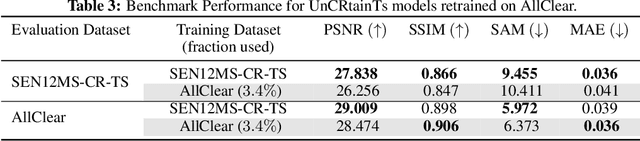
Clouds in satellite imagery pose a significant challenge for downstream applications. A major challenge in current cloud removal research is the absence of a comprehensive benchmark and a sufficiently large and diverse training dataset. To address this problem, we introduce the largest public dataset -- $\textit{AllClear}$ for cloud removal, featuring 23,742 globally distributed regions of interest (ROIs) with diverse land-use patterns, comprising 4 million images in total. Each ROI includes complete temporal captures from the year 2022, with (1) multi-spectral optical imagery from Sentinel-2 and Landsat 8/9, (2) synthetic aperture radar (SAR) imagery from Sentinel-1, and (3) auxiliary remote sensing products such as cloud masks and land cover maps. We validate the effectiveness of our dataset by benchmarking performance, demonstrating the scaling law -- the PSNR rises from $28.47$ to $33.87$ with $30\times$ more data, and conducting ablation studies on the temporal length and the importance of individual modalities. This dataset aims to provide comprehensive coverage of the Earth's surface and promote better cloud removal results.
Scale-Aware Recognition in Satellite Images under Resource Constraint
Oct 31, 2024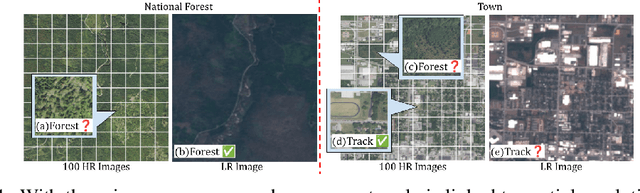



Recognition of features in satellite imagery (forests, swimming pools, etc.) depends strongly on the spatial scale of the concept and therefore the resolution of the images. This poses two challenges: Which resolution is best suited for recognizing a given concept, and where and when should the costlier higher-resolution (HR) imagery be acquired? We present a novel scheme to address these challenges by introducing three components: (1) A technique to distill knowledge from models trained on HR imagery to recognition models that operate on imagery of lower resolution (LR), (2) a sampling strategy for HR imagery based on model disagreement, and (3) an LLM-based approach for inferring concept "scale". With these components we present a system to efficiently perform scale-aware recognition in satellite imagery, improving accuracy over single-scale inference while following budget constraints. Our novel approach offers up to a 26.3% improvement over entirely HR baselines, using 76.3% fewer HR images.
How Video Meetings Change Your Expression
Jun 03, 2024



Do our facial expressions change when we speak over video calls? Given two unpaired sets of videos of people, we seek to automatically find spatio-temporal patterns that are distinctive of each set. Existing methods use discriminative approaches and perform post-hoc explainability analysis. Such methods are insufficient as they are unable to provide insights beyond obvious dataset biases, and the explanations are useful only if humans themselves are good at the task. Instead, we tackle the problem through the lens of generative domain translation: our method generates a detailed report of learned, input-dependent spatio-temporal features and the extent to which they vary between the domains. We demonstrate that our method can discover behavioral differences between conversing face-to-face (F2F) and on video-calls (VCs). We also show the applicability of our method on discovering differences in presidential communication styles. Additionally, we are able to predict temporal change-points in videos that decouple expressions in an unsupervised way, and increase the interpretability and usefulness of our model. Finally, our method, being generative, can be used to transform a video call to appear as if it were recorded in a F2F setting. Experiments and visualizations show our approach is able to discover a range of behaviors, taking a step towards deeper understanding of human behaviors.
Evolving Interpretable Visual Classifiers with Large Language Models
Apr 15, 2024
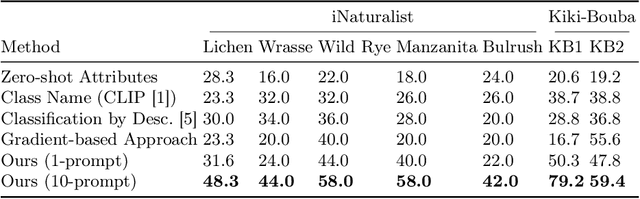


Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
Dec 12, 2023We introduce a method to train vision-language models for remote-sensing images without using any textual annotations. Our key insight is to use co-located internet imagery taken on the ground as an intermediary for connecting remote-sensing images and language. Specifically, we train an image encoder for remote sensing images to align with the image encoder of CLIP using a large amount of paired internet and satellite images. Our unsupervised approach enables the training of a first-of-its-kind large-scale vision language model (VLM) for remote sensing images at two different resolutions. We show that these VLMs enable zero-shot, open-vocabulary image classification, retrieval, segmentation and visual question answering for satellite images. On each of these tasks, our VLM trained without textual annotations outperforms existing VLMs trained with supervision, with gains of up to 20% for classification and 80% for segmentation.
Field-Guide-Inspired Zero-Shot Learning
Aug 24, 2021
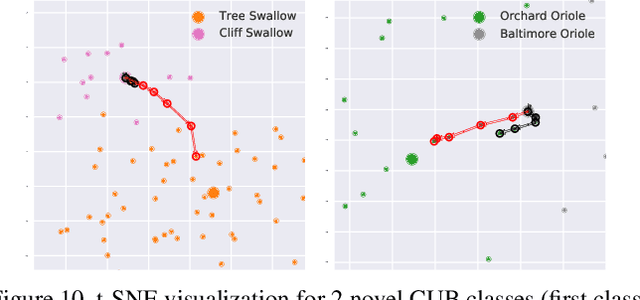
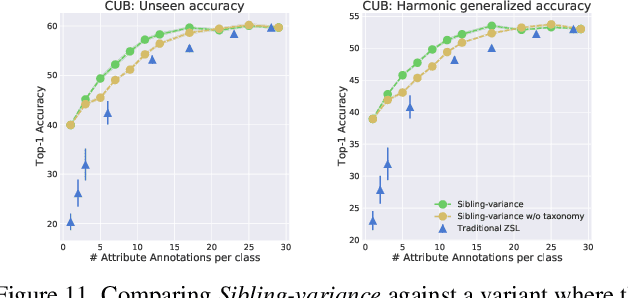
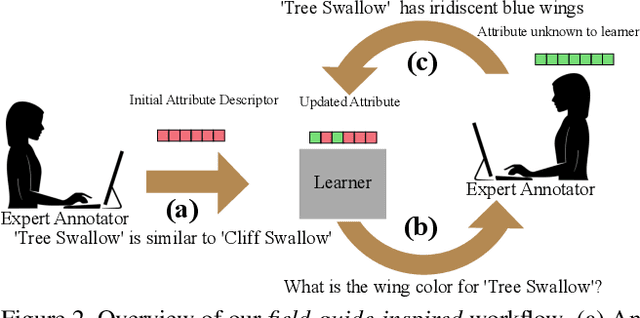
Modern recognition systems require large amounts of supervision to achieve accuracy. Adapting to new domains requires significant data from experts, which is onerous and can become too expensive. Zero-shot learning requires an annotated set of attributes for a novel category. Annotating the full set of attributes for a novel category proves to be a tedious and expensive task in deployment. This is especially the case when the recognition domain is an expert domain. We introduce a new field-guide-inspired approach to zero-shot annotation where the learner model interactively asks for the most useful attributes that define a class. We evaluate our method on classification benchmarks with attribute annotations like CUB, SUN, and AWA2 and show that our model achieves the performance of a model with full annotations at the cost of a significantly fewer number of annotations. Since the time of experts is precious, decreasing annotation cost can be very valuable for real-world deployment.
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering
Mar 30, 2021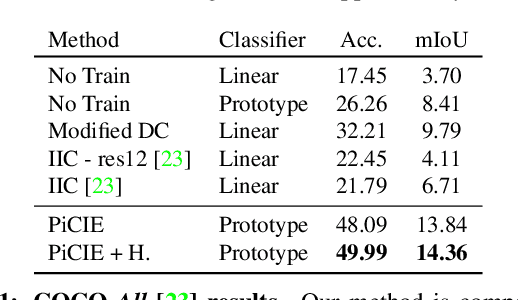
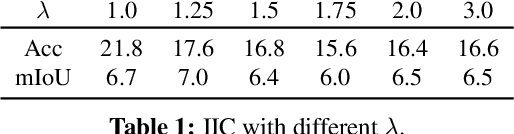
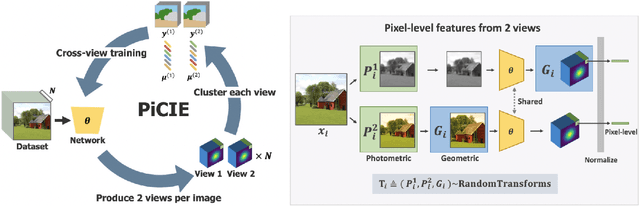
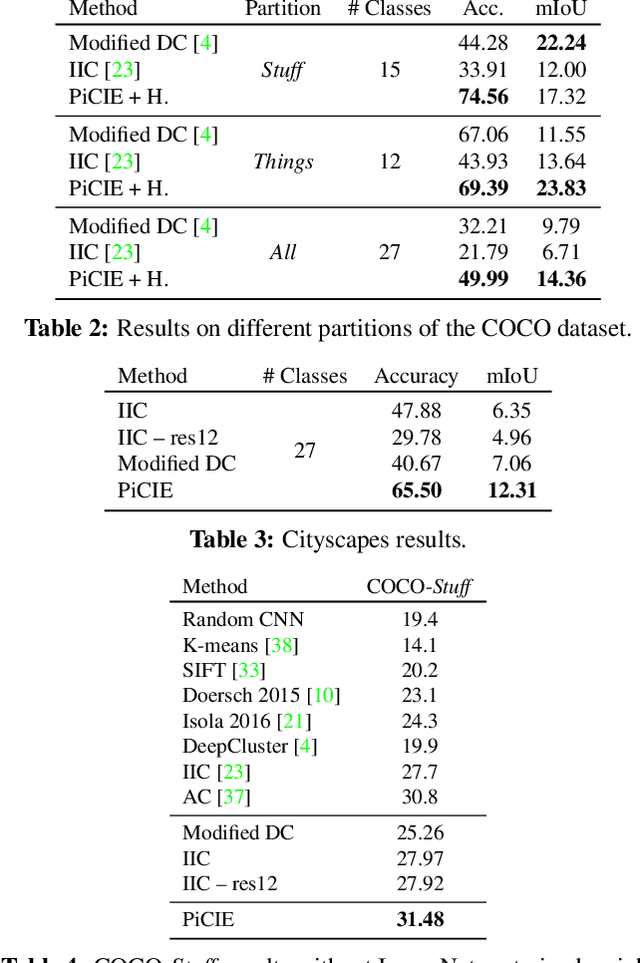
We present a new framework for semantic segmentation without annotations via clustering. Off-the-shelf clustering methods are limited to curated, single-label, and object-centric images yet real-world data are dominantly uncurated, multi-label, and scene-centric. We extend clustering from images to pixels and assign separate cluster membership to different instances within each image. However, solely relying on pixel-wise feature similarity fails to learn high-level semantic concepts and overfits to low-level visual cues. We propose a method to incorporate geometric consistency as an inductive bias to learn invariance and equivariance for photometric and geometric variations. With our novel learning objective, our framework can learn high-level semantic concepts. Our method, PiCIE (Pixel-level feature Clustering using Invariance and Equivariance), is the first method capable of segmenting both things and stuff categories without any hyperparameter tuning or task-specific pre-processing. Our method largely outperforms existing baselines on COCO and Cityscapes with +17.5 Acc. and +4.5 mIoU. We show that PiCIE gives a better initialization for standard supervised training. The code is available at https://github.com/janghyuncho/PiCIE.
Discovering Underground Maps from Fashion
Dec 04, 2020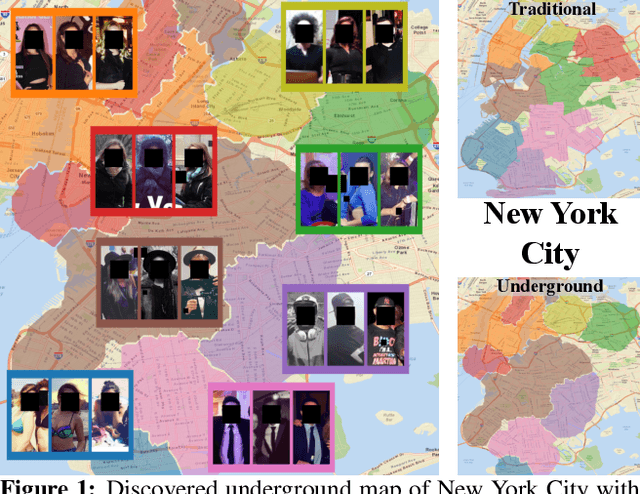
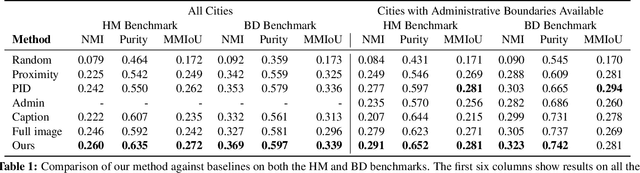
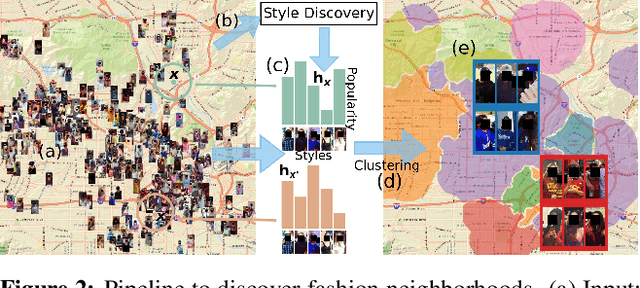
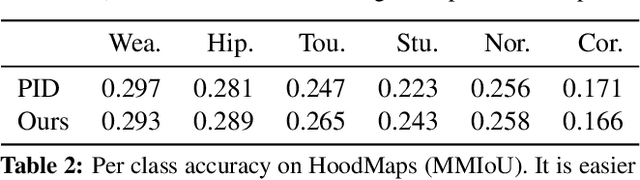
The fashion sense -- meaning the clothing styles people wear -- in a geographical region can reveal information about that region. For example, it can reflect the kind of activities people do there, or the type of crowds that frequently visit the region (e.g., tourist hot spot, student neighborhood, business center). We propose a method to automatically create underground neighborhood maps of cities by analyzing how people dress. Using publicly available images from across a city, our method finds neighborhoods with a similar fashion sense and segments the map without supervision. For 37 cities worldwide, we show promising results in creating good underground maps, as evaluated using experiments with human judges and underground map benchmarks derived from non-image data. Our approach further allows detecting distinct neighborhoods (what is the most unique region of LA?) and answering analogy questions between cities (what is the "Downtown LA" of Bogota?).
GeoStyle: Discovering Fashion Trends and Events
Aug 29, 2019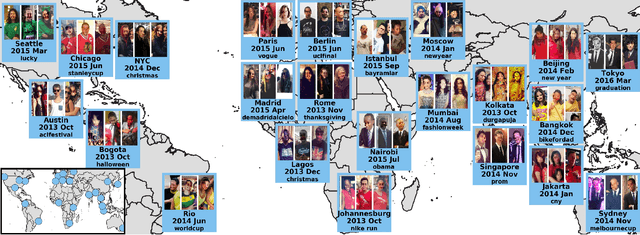

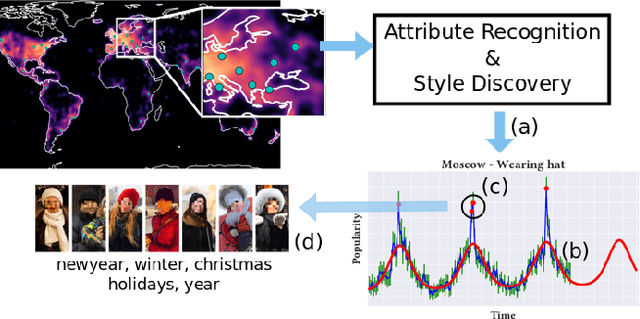
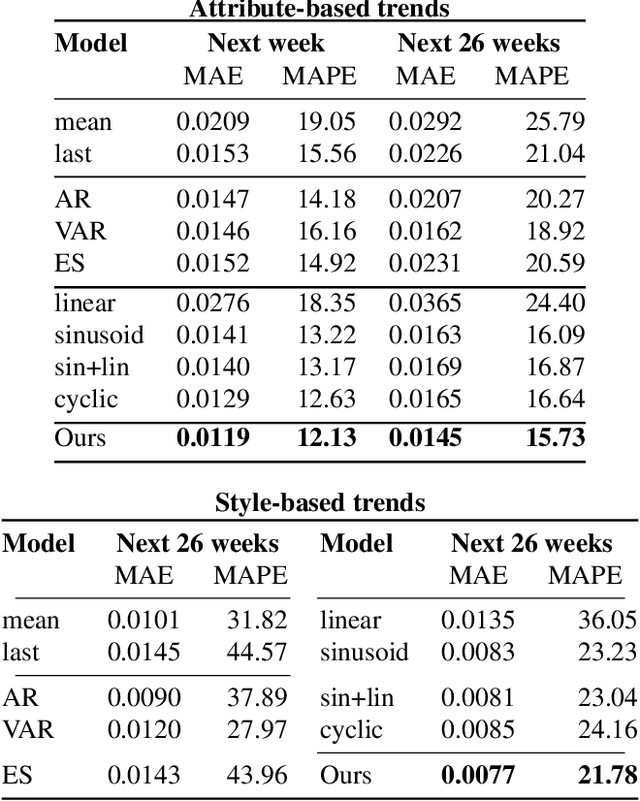
Understanding fashion styles and trends is of great potential interest to retailers and consumers alike. The photos people upload to social media are a historical and public data source of how people dress across the world and at different times. While we now have tools to automatically recognize the clothing and style attributes of what people are wearing in these photographs, we lack the ability to analyze spatial and temporal trends in these attributes or make predictions about the future. In this paper, we address this need by providing an automatic framework that analyzes large corpora of street imagery to (a) discover and forecast long-term trends of various fashion attributes as well as automatically discovered styles, and (b) identify spatio-temporally localized events that affect what people wear. We show that our framework makes long term trend forecasts that are >20% more accurate than the prior art, and identifies hundreds of socially meaningful events that impact fashion across the globe.