 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspective Fields for Single Image Camera Calibration
Dec 06, 2022



Geometric camera calibration is often required for applications that understand the perspective of the image. We propose perspective fields as a representation that models the local perspective properties of an image. Perspective Fields contain per-pixel information about the camera view, parameterized as an up vector and a latitude value. This representation has a number of advantages as it makes minimal assumptions about the camera model and is invariant or equivariant to common image editing operations like cropping, warping, and rotation. It is also more interpretable and aligned with human perception. We train a neural network to predict Perspective Fields and the predicted Perspective Fields can be converted to calibration parameters easily. We demonstrate the robustness of our approach under various scenarios compared with camera calibration-based methods and show example applications in image compositing.
One Shot 3D Photography
Sep 01, 2020
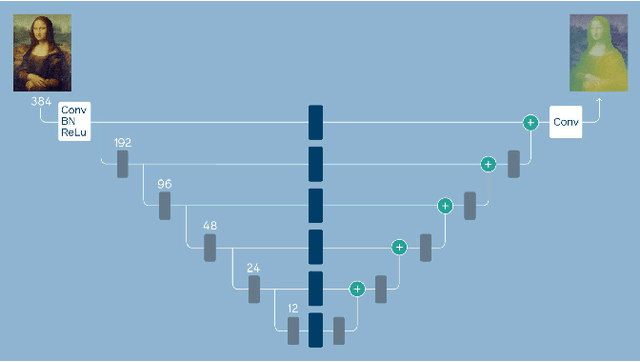

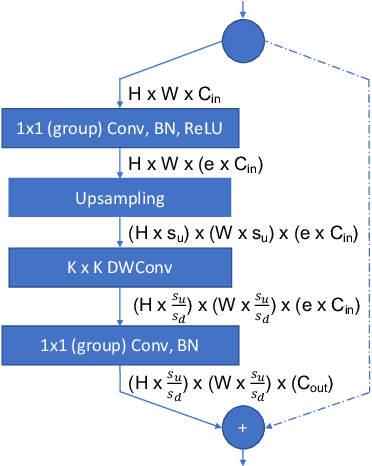
3D photography is a new medium that allows viewers to more fully experience a captured moment. In this work, we refer to a 3D photo as one that displays parallax induced by moving the viewpoint (as opposed to a stereo pair with a fixed viewpoint). 3D photos are static in time, like traditional photos, but are displayed with interactive parallax on mobile or desktop screens, as well as on Virtual Reality devices, where viewing it also includes stereo. We present an end-to-end system for creating and viewing 3D photos, and the algorithmic and design choices therein. Our 3D photos are captured in a single shot and processed directly on a mobile device. The method starts by estimating depth from the 2D input image using a new monocular depth estimation network that is optimized for mobile devices. It performs competitively to the state-of-the-art, but has lower latency and peak memory consumption and uses an order of magnitude fewer parameters. The resulting depth is lifted to a layered depth image, and new geometry is synthesized in parallax regions. We synthesize color texture and structures in the parallax regions as well, using an inpainting network, also optimized for mobile devices, on the LDI directly. Finally, we convert the result into a mesh-based representation that can be efficiently transmitted and rendered even on low-end devices and over poor network connections. Altogether, the processing takes just a few seconds on a mobile device, and the result can be instantly viewed and shared. We perform extensive quantitative evaluation to validate our system and compare its new components against the current state-of-the-art.
* Project page: https://facebookresearch.github.io/one_shot_3d_photography/ Code: https://github.com/facebookresearch/one_shot_3d_photography
Consistent Video Depth Estimation
Apr 30, 2020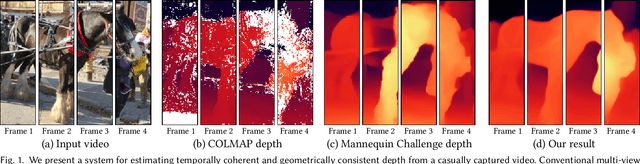
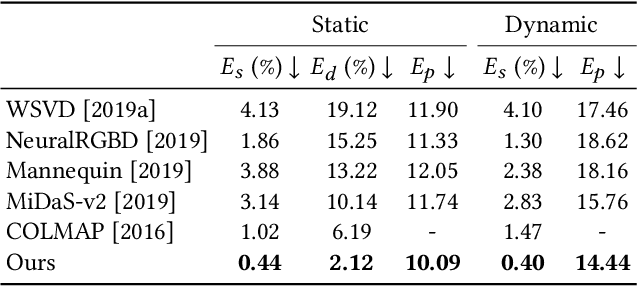
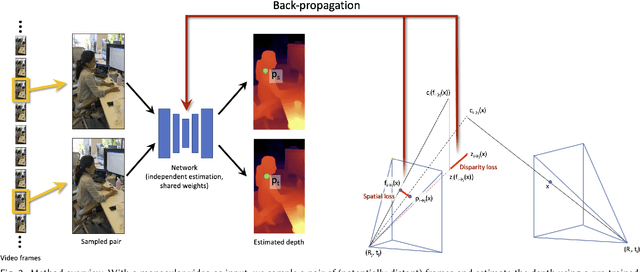
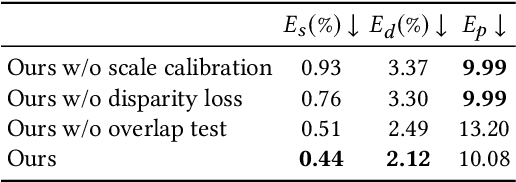
We present an algorithm for reconstructing dense, geometrically consistent depth for all pixels in a monocular video. We leverage a conventional structure-from-motion reconstruction to establish geometric constraints on pixels in the video. Unlike the ad-hoc priors in classical reconstruction, we use a learning-based prior, i.e., a convolutional neural network trained for single-image depth estimation. At test time, we fine-tune this network to satisfy the geometric constraints of a particular input video, while retaining its ability to synthesize plausible depth details in parts of the video that are less constrained. We show through quantitative validation that our method achieves higher accuracy and a higher degree of geometric consistency than previous monocular reconstruction methods. Visually, our results appear more stable. Our algorithm is able to handle challenging hand-held captured input videos with a moderate degree of dynamic motion. The improved quality of the reconstruction enables several applications, such as scene reconstruction and advanced video-based visual effects.
GeoStyle: Discovering Fashion Trends and Events
Aug 29, 2019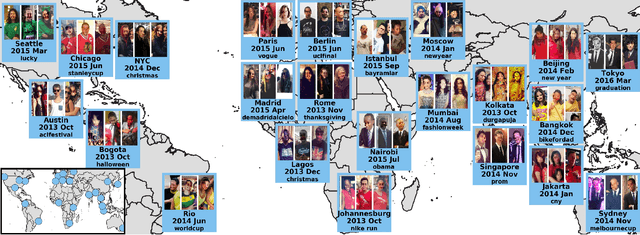

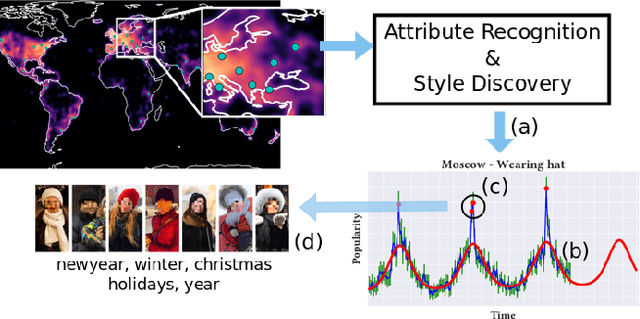
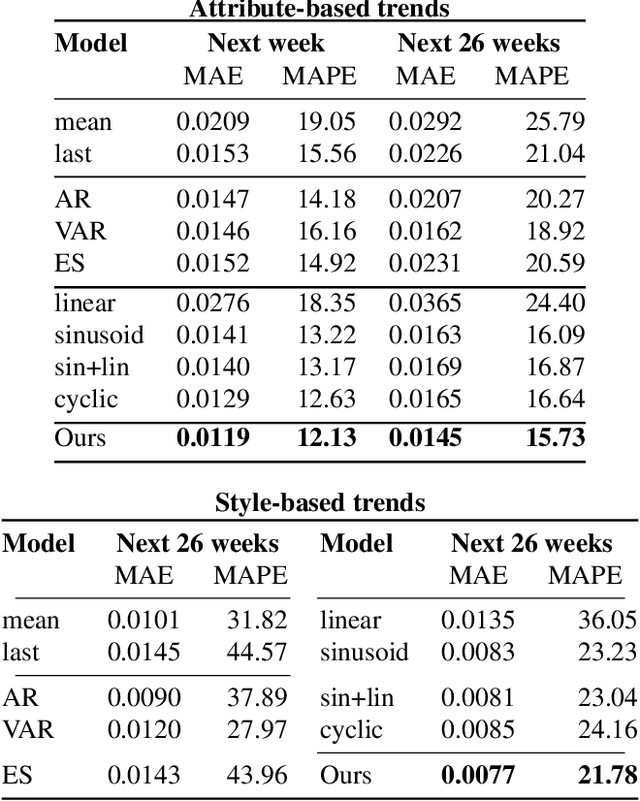
Understanding fashion styles and trends is of great potential interest to retailers and consumers alike. The photos people upload to social media are a historical and public data source of how people dress across the world and at different times. While we now have tools to automatically recognize the clothing and style attributes of what people are wearing in these photographs, we lack the ability to analyze spatial and temporal trends in these attributes or make predictions about the future. In this paper, we address this need by providing an automatic framework that analyzes large corpora of street imagery to (a) discover and forecast long-term trends of various fashion attributes as well as automatically discovered styles, and (b) identify spatio-temporally localized events that affect what people wear. We show that our framework makes long term trend forecasts that are >20% more accurate than the prior art, and identifies hundreds of socially meaningful events that impact fashion across the globe.
Synthetic Defocus and Look-Ahead Autofocus for Casual Videography
May 21, 2019


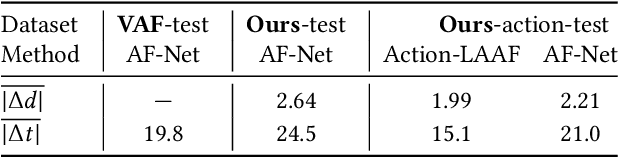
In cinema, large camera lenses create beautiful shallow depth of field (DOF), but make focusing difficult and expensive. Accurate cinema focus usually relies on a script and a person to control focus in realtime. Casual videographers often crave cinematic focus, but fail to achieve it. We either sacrifice shallow DOF, as in smartphone videos; or we struggle to deliver accurate focus, as in videos from larger cameras. This paper is about a new approach in the pursuit of cinematic focus for casual videography. We present a system that synthetically renders refocusable video from a deep DOF video shot with a smartphone, and analyzes future video frames to deliver context-aware autofocus for the current frame. To create refocusable video, we extend recent machine learning methods designed for still photography, contributing a new dataset for machine training, a rendering model better suited to cinema focus, and a filtering solution for temporal coherence. To choose focus accurately for each frame, we demonstrate autofocus that looks at upcoming video frames and applies AI-assist modules such as motion, face, audio and saliency detection. We also show that autofocus benefits from machine learning and a large-scale video dataset with focus annotation, where we use our RVR-LAAF GUI to create this sizable dataset efficiently. We deliver, for example, a shallow DOF video where the autofocus transitions onto each person before she begins to speak. This is impossible for conventional camera autofocus because it would require seeing into the future.
DeepMVS: Learning Multi-view Stereopsis
Apr 02, 2018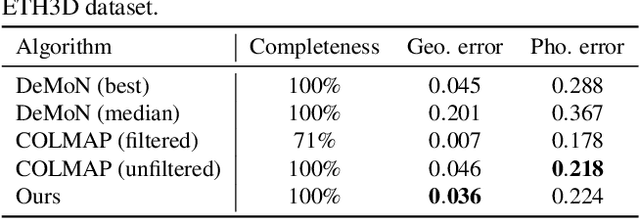
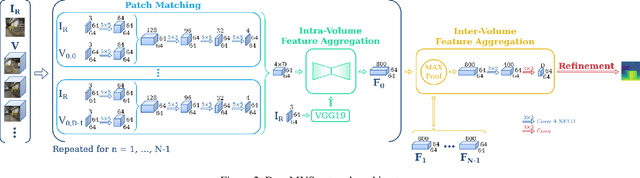


We present DeepMVS, a deep convolutional neural network (ConvNet) for multi-view stereo reconstruction. Taking an arbitrary number of posed images as input, we first produce a set of plane-sweep volumes and use the proposed DeepMVS network to predict high-quality disparity maps. The key contributions that enable these results are (1) supervised pretraining on a photorealistic synthetic dataset, (2) an effective method for aggregating information across a set of unordered images, and (3) integrating multi-layer feature activations from the pre-trained VGG-19 network. We validate the efficacy of DeepMVS using the ETH3D Benchmark. Our results show that DeepMVS compares favorably against state-of-the-art conventional MVS algorithms and other ConvNet based methods, particularly for near-textureless regions and thin structures.
Deep Burst Denoising
Dec 15, 2017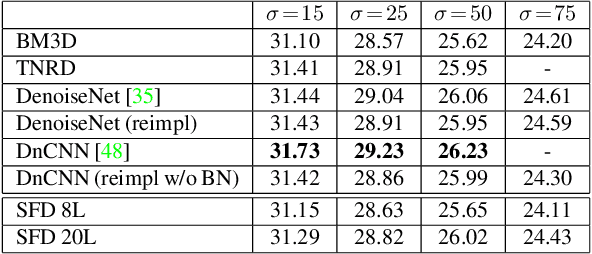
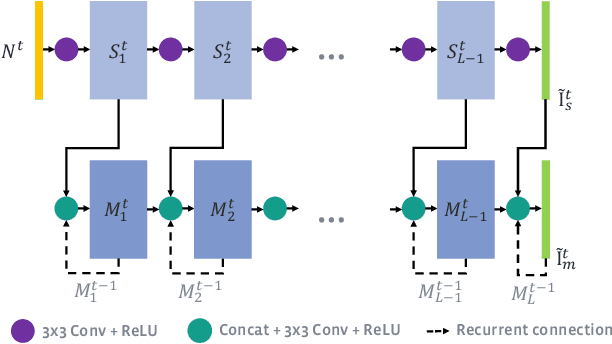

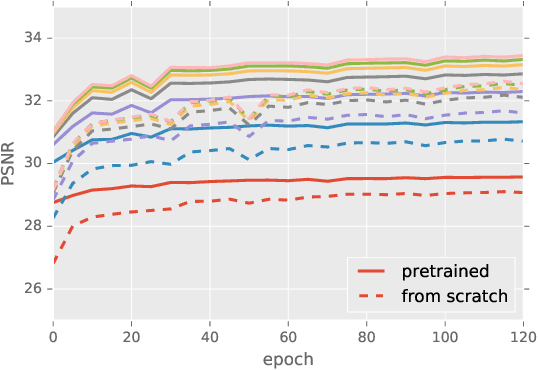
Noise is an inherent issue of low-light image capture, one which is exacerbated on mobile devices due to their narrow apertures and small sensors. One strategy for mitigating noise in a low-light situation is to increase the shutter time of the camera, thus allowing each photosite to integrate more light and decrease noise variance. However, there are two downsides of long exposures: (a) bright regions can exceed the sensor range, and (b) camera and scene motion will result in blurred images. Another way of gathering more light is to capture multiple short (thus noisy) frames in a "burst" and intelligently integrate the content, thus avoiding the above downsides. In this paper, we use the burst-capture strategy and implement the intelligent integration via a recurrent fully convolutional deep neural net (CNN). We build our novel, multiframe architecture to be a simple addition to any single frame denoising model, and design to handle an arbitrary number of noisy input frames. We show that it achieves state of the art denoising results on our burst dataset, improving on the best published multi-frame techniques, such as VBM4D and FlexISP. Finally, we explore other applications of image enhancement by integrating content from multiple frames and demonstrate that our DNN architecture generalizes well to image super-resolution.
StreetStyle: Exploring world-wide clothing styles from millions of photos
Jun 06, 2017Each day billions of photographs are uploaded to photo-sharing services and social media platforms. These images are packed with information about how people live around the world. In this paper we exploit this rich trove of data to understand fashion and style trends worldwide. We present a framework for visual discovery at scale, analyzing clothing and fashion across millions of images of people around the world and spanning several years. We introduce a large-scale dataset of photos of people annotated with clothing attributes, and use this dataset to train attribute classifiers via deep learning. We also present a method for discovering visually consistent style clusters that capture useful visual correlations in this massive dataset. Using these tools, we analyze millions of photos to derive visual insight, producing a first-of-its-kind analysis of global and per-city fashion choices and spatio-temporal trends.
All Weather Perception: Joint Data Association, Tracking, and Classification for Autonomous Ground Vehicles
May 07, 2016
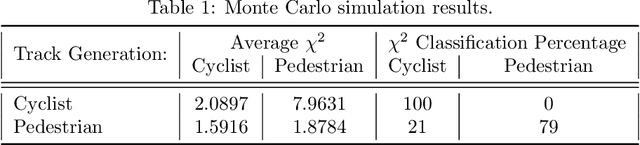
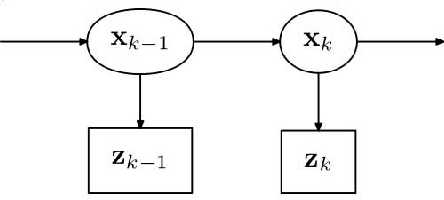

A novel probabilistic perception algorithm is presented as a real-time joint solution to data association, object tracking, and object classification for an autonomous ground vehicle in all-weather conditions. The presented algorithm extends a Rao-Blackwellized Particle Filter originally built with a particle filter for data association and a Kalman filter for multi-object tracking (Miller et al. 2011a) to now also include multiple model tracking for classification. Additionally a state-of-the-art vision detection algorithm that includes heading information for autonomous ground vehicle (AGV) applications was implemented. Cornell's AGV from the DARPA Urban Challenge was upgraded and used to experimentally examine if and how state-of-the-art vision algorithms can complement or replace lidar and radar sensors. Sensor and algorithm performance in adverse weather and lighting conditions is tested. Experimental evaluation demonstrates robust all-weather data association, tracking, and classification where camera, lidar, and radar sensors complement each other inside the joint probabilistic perception algorithm.