 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Predictability as a Fast Reliability Indicator for Time Series Forecasting Model Selection
Nov 12, 2025Practitioners deploying time series forecasting models face a dilemma: exhaustively validating dozens of models is computationally prohibitive, yet choosing the wrong model risks poor performance. We show that spectral predictability~$Ω$ -- a simple signal processing metric -- systematically stratifies model family performance, enabling fast model selection. We conduct controlled experiments in four different domains, then further expand our analysis to 51 models and 28 datasets from the GIFT-Eval benchmark. We find that large time series foundation models (TSFMs) systematically outperform lightweight task-trained baselines when $Ω$ is high, while their advantage vanishes as $Ω$ drops. Computing $Ω$ takes seconds per dataset, enabling practitioners to quickly assess whether their data suits TSFM approaches or whether simpler, cheaper models suffice. We demonstrate that $Ω$ stratifies model performance predictably, offering a practical first-pass filter that reduces validation costs while highlighting the need for models that excel on genuinely difficult (low-$Ω$) problems rather than merely optimizing easy ones.
Motion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Layered Diffusion Model for One-Shot High Resolution Text-to-Image Synthesis
Jul 08, 2024
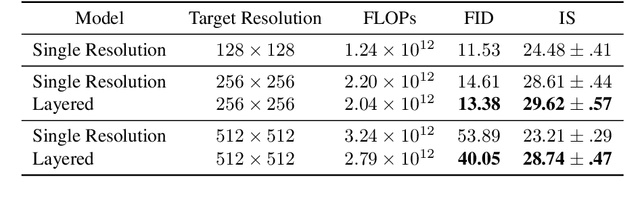


We present a one-shot text-to-image diffusion model that can generate high-resolution images from natural language descriptions. Our model employs a layered U-Net architecture that simultaneously synthesizes images at multiple resolution scales. We show that this method outperforms the baseline of synthesizing images only at the target resolution, while reducing the computational cost per step. We demonstrate that higher resolution synthesis can be achieved by layering convolutions at additional resolution scales, in contrast to other methods which require additional models for super-resolution synthesis.
An insertable glucose sensor using a compact and cost-effective phosphorescence lifetime imager and machine learning
Jun 12, 2024Optical continuous glucose monitoring (CGM) systems are emerging for personalized glucose management owing to their lower cost and prolonged durability compared to conventional electrochemical CGMs. Here, we report a computational CGM system, which integrates a biocompatible phosphorescence-based insertable biosensor and a custom-designed phosphorescence lifetime imager (PLI). This compact and cost-effective PLI is designed to capture phosphorescence lifetime images of an insertable sensor through the skin, where the lifetime of the emitted phosphorescence signal is modulated by the local concentration of glucose. Because this phosphorescence signal has a very long lifetime compared to tissue autofluorescence or excitation leakage processes, it completely bypasses these noise sources by measuring the sensor emission over several tens of microseconds after the excitation light is turned off. The lifetime images acquired through the skin are processed by neural network-based models for misalignment-tolerant inference of glucose levels, accurately revealing normal, low (hypoglycemia) and high (hyperglycemia) concentration ranges. Using a 1-mm thick skin phantom mimicking the optical properties of human skin, we performed in vitro testing of the PLI using glucose-spiked samples, yielding 88.8% inference accuracy, also showing resilience to random and unknown misalignments within a lateral distance of ~4.7 mm with respect to the position of the insertable sensor underneath the skin phantom. Furthermore, the PLI accurately identified larger lateral misalignments beyond 5 mm, prompting user intervention for re-alignment. The misalignment-resilient glucose concentration inference capability of this compact and cost-effective phosphorescence lifetime imager makes it an appealing wearable diagnostics tool for real-time tracking of glucose and other biomarkers.
Image Neural Field Diffusion Models
Jun 11, 2024



Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024



We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
VecFusion: Vector Font Generation with Diffusion
Dec 16, 2023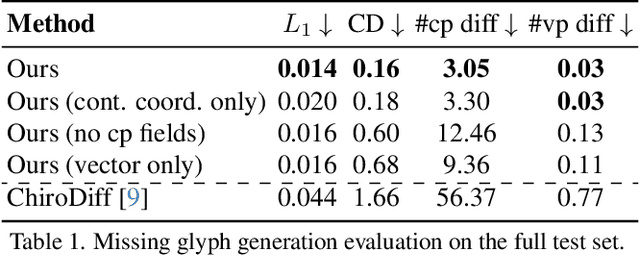

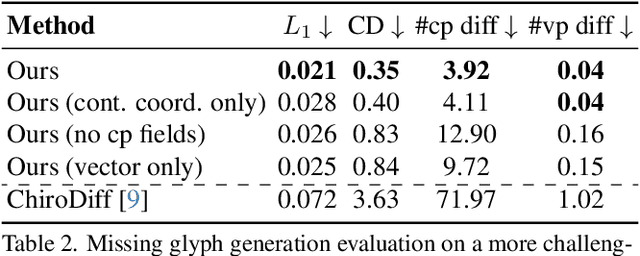

We present VecFusion, a new neural architecture that can generate vector fonts with varying topological structures and precise control point positions. Our approach is a cascaded diffusion model which consists of a raster diffusion model followed by a vector diffusion model. The raster model generates low-resolution, rasterized fonts with auxiliary control point information, capturing the global style and shape of the font, while the vector model synthesizes vector fonts conditioned on the low-resolution raster fonts from the first stage. To synthesize long and complex curves, our vector diffusion model uses a transformer architecture and a novel vector representation that enables the modeling of diverse vector geometry and the precise prediction of control points. Our experiments show that, in contrast to previous generative models for vector graphics, our new cascaded vector diffusion model generates higher quality vector fonts, with complex structures and diverse styles.