 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
The establishment of static digital humans and the integration with spinal models
Feb 11, 2025Adolescent idiopathic scoliosis (AIS), a prevalent spinal deformity, significantly affects individuals' health and quality of life. Conventional imaging techniques, such as X - rays, computed tomography (CT), and magnetic resonance imaging (MRI), offer static views of the spine. However, they are restricted in capturing the dynamic changes of the spine and its interactions with overall body motion. Therefore, developing new techniques to address these limitations has become extremely important. Dynamic digital human modeling represents a major breakthrough in digital medicine. It enables a three - dimensional (3D) view of the spine as it changes during daily activities, assisting clinicians in detecting deformities that might be missed in static imaging. Although dynamic modeling holds great potential, constructing an accurate static digital human model is a crucial initial step for high - precision simulations. In this study, our focus is on constructing an accurate static digital human model integrating the spine, which is vital for subsequent dynamic digital human research on AIS. First, we generate human point - cloud data by combining the 3D Gaussian method with the Skinned Multi - Person Linear (SMPL) model from the patient's multi - view images. Then, we fit a standard skeletal model to the generated human model. Next, we align the real spine model reconstructed from CT images with the standard skeletal model. We validated the resulting personalized spine model using X - ray data from six AIS patients, with Cobb angles (used to measure the severity of scoliosis) as evaluation metrics. The results indicate that the model's error was within 1 degree of the actual measurements. This study presents an important method for constructing digital humans.
Diffusion Autoencoders are Scalable Image Tokenizers
Jan 30, 2025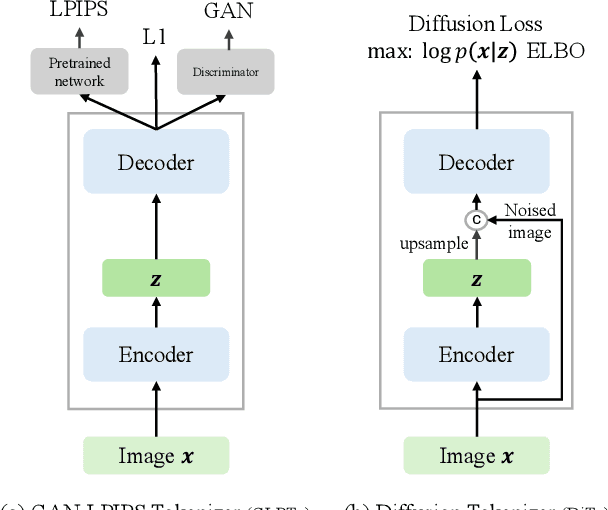



Tokenizing images into compact visual representations is a key step in learning efficient and high-quality image generative models. We present a simple diffusion tokenizer (DiTo) that learns compact visual representations for image generation models. Our key insight is that a single learning objective, diffusion L2 loss, can be used for training scalable image tokenizers. Since diffusion is already widely used for image generation, our insight greatly simplifies training such tokenizers. In contrast, current state-of-the-art tokenizers rely on an empirically found combination of heuristics and losses, thus requiring a complex training recipe that relies on non-trivially balancing different losses and pretrained supervised models. We show design decisions, along with theoretical grounding, that enable us to scale DiTo for learning competitive image representations. Our results show that DiTo is a simpler, scalable, and self-supervised alternative to the current state-of-the-art image tokenizer which is supervised. DiTo achieves competitive or better quality than state-of-the-art in image reconstruction and downstream image generation tasks.
Consistent Flow Distillation for Text-to-3D Generation
Jan 09, 2025

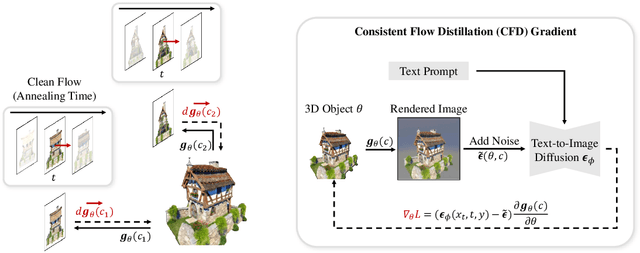

Score Distillation Sampling (SDS) has made significant strides in distilling image-generative models for 3D generation. However, its maximum-likelihood-seeking behavior often leads to degraded visual quality and diversity, limiting its effectiveness in 3D applications. In this work, we propose Consistent Flow Distillation (CFD), which addresses these limitations. We begin by leveraging the gradient of the diffusion ODE or SDE sampling process to guide the 3D generation. From the gradient-based sampling perspective, we find that the consistency of 2D image flows across different viewpoints is important for high-quality 3D generation. To achieve this, we introduce multi-view consistent Gaussian noise on the 3D object, which can be rendered from various viewpoints to compute the flow gradient. Our experiments demonstrate that CFD, through consistent flows, significantly outperforms previous methods in text-to-3D generation.
Image Neural Field Diffusion Models
Jun 11, 2024



Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
Visual Reinforcement Learning with Self-Supervised 3D Representations
Oct 13, 2022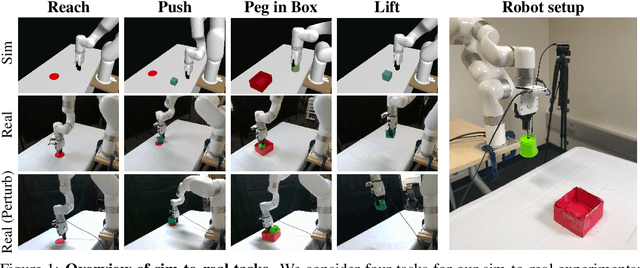

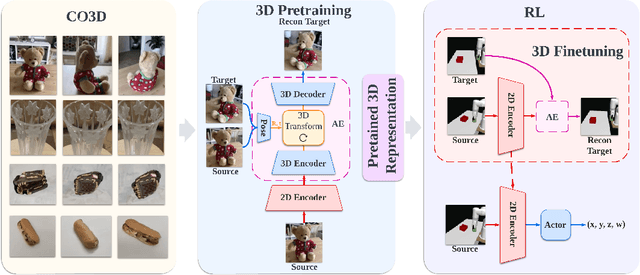

A prominent approach to visual Reinforcement Learning (RL) is to learn an internal state representation using self-supervised methods, which has the potential benefit of improved sample-efficiency and generalization through additional learning signal and inductive biases. However, while the real world is inherently 3D, prior efforts have largely been focused on leveraging 2D computer vision techniques as auxiliary self-supervision. In this work, we present a unified framework for self-supervised learning of 3D representations for motor control. Our proposed framework consists of two phases: a pretraining phase where a deep voxel-based 3D autoencoder is pretrained on a large object-centric dataset, and a finetuning phase where the representation is jointly finetuned together with RL on in-domain data. We empirically show that our method enjoys improved sample efficiency in simulated manipulation tasks compared to 2D representation learning methods. Additionally, our learned policies transfer zero-shot to a real robot setup with only approximate geometric correspondence, and successfully solve motor control tasks that involve grasping and lifting from a single, uncalibrated RGB camera. Code and videos are available at https://yanjieze.com/3d4rl/ .
Transformers as Meta-Learners for Implicit Neural Representations
Aug 05, 2022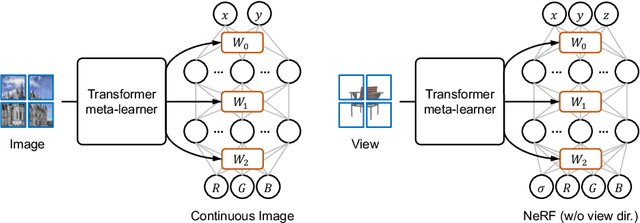

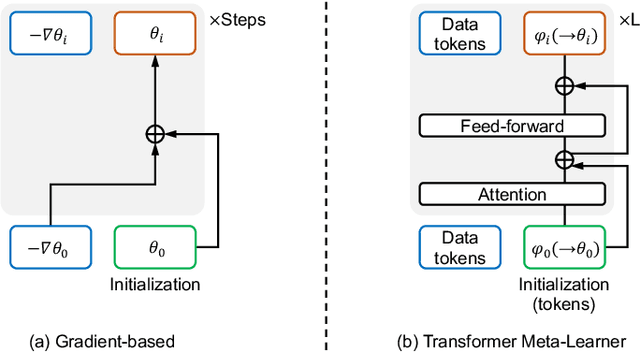

Implicit Neural Representations (INRs) have emerged and shown their benefits over discrete representations in recent years. However, fitting an INR to the given observations usually requires optimization with gradient descent from scratch, which is inefficient and does not generalize well with sparse observations. To address this problem, most of the prior works train a hypernetwork that generates a single vector to modulate the INR weights, where the single vector becomes an information bottleneck that limits the reconstruction precision of the output INR. Recent work shows that the whole set of weights in INR can be precisely inferred without the single-vector bottleneck by gradient-based meta-learning. Motivated by a generalized formulation of gradient-based meta-learning, we propose a formulation that uses Transformers as hypernetworks for INRs, where it can directly build the whole set of INR weights with Transformers specialized as set-to-set mapping. We demonstrate the effectiveness of our method for building INRs in different tasks and domains, including 2D image regression and view synthesis for 3D objects. Our work draws connections between the Transformer hypernetworks and gradient-based meta-learning algorithms and we provide further analysis for understanding the generated INRs.
Learning Implicit Feature Alignment Function for Semantic Segmentation
Jun 17, 2022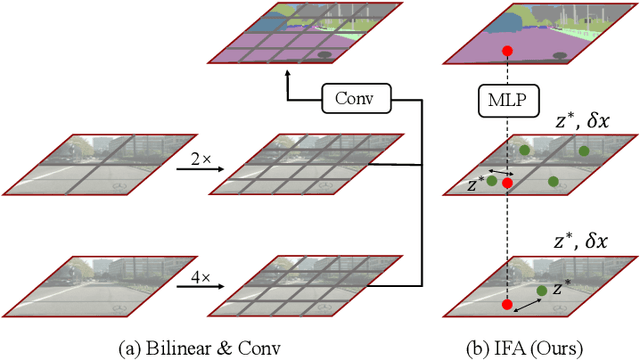
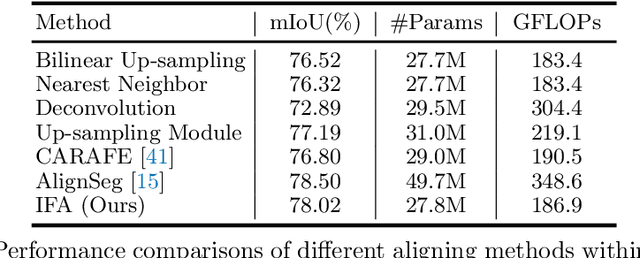
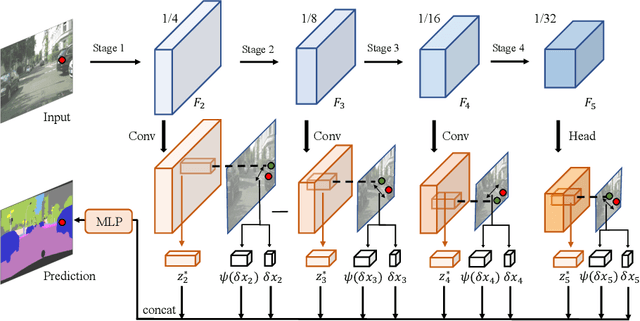
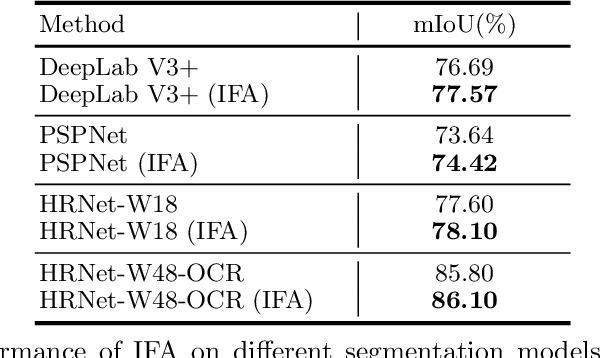
Integrating high-level context information with low-level details is of central importance in semantic segmentation. Towards this end, most existing segmentation models apply bilinear up-sampling and convolutions to feature maps of different scales, and then align them at the same resolution. However, bilinear up-sampling blurs the precise information learned in these feature maps and convolutions incur extra computation costs. To address these issues, we propose the Implicit Feature Alignment function (IFA). Our method is inspired by the rapidly expanding topic of implicit neural representations, where coordinate-based neural networks are used to designate fields of signals. In IFA, feature vectors are viewed as representing a 2D field of information. Given a query coordinate, nearby feature vectors with their relative coordinates are taken from the multi-level feature maps and then fed into an MLP to generate the corresponding output. As such, IFA implicitly aligns the feature maps at different levels and is capable of producing segmentation maps in arbitrary resolutions. We demonstrate the efficacy of IFA on multiple datasets, including Cityscapes, PASCAL Context, and ADE20K. Our method can be combined with improvement on various architectures, and it achieves state-of-the-art computation-accuracy trade-off on common benchmarks. Code will be made available at https://github.com/hzhupku/IFA.
VideoINR: Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution
Jun 09, 2022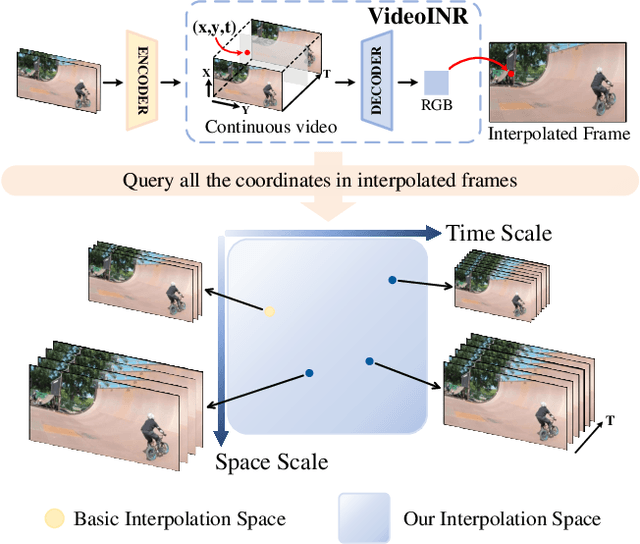
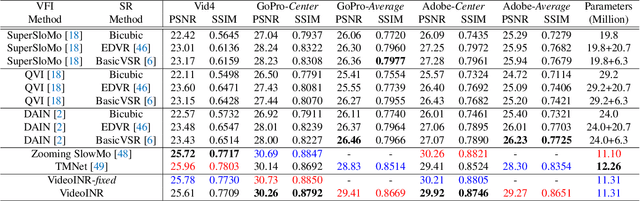
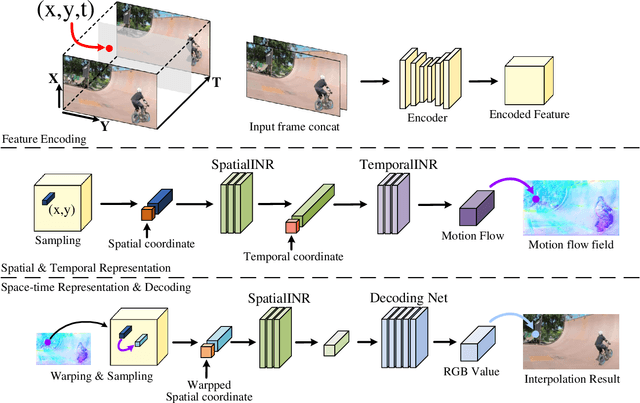
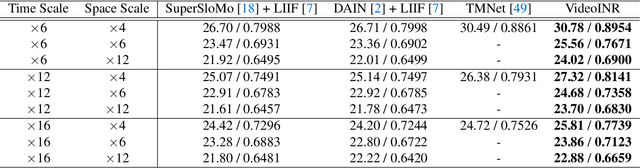
Videos typically record the streaming and continuous visual data as discrete consecutive frames. Since the storage cost is expensive for videos of high fidelity, most of them are stored in a relatively low resolution and frame rate. Recent works of Space-Time Video Super-Resolution (STVSR) are developed to incorporate temporal interpolation and spatial super-resolution in a unified framework. However, most of them only support a fixed up-sampling scale, which limits their flexibility and applications. In this work, instead of following the discrete representations, we propose Video Implicit Neural Representation (VideoINR), and we show its applications for STVSR. The learned implicit neural representation can be decoded to videos of arbitrary spatial resolution and frame rate. We show that VideoINR achieves competitive performances with state-of-the-art STVSR methods on common up-sampling scales and significantly outperforms prior works on continuous and out-of-training-distribution scales. Our project page is at http://zeyuan-chen.com/VideoINR/ .
Learning Continuous Image Representation with Local Implicit Image Function
Dec 16, 2020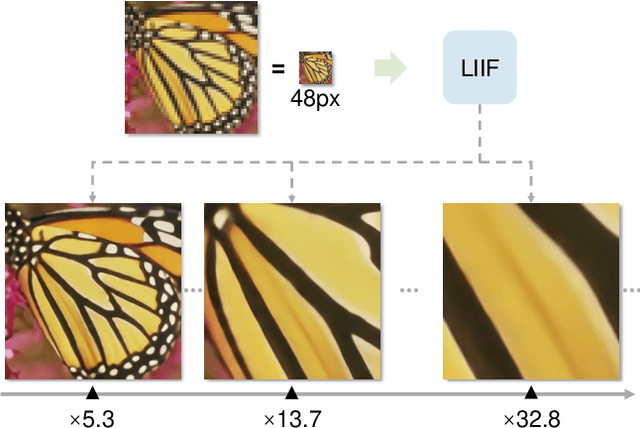
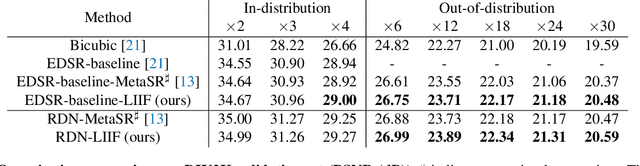
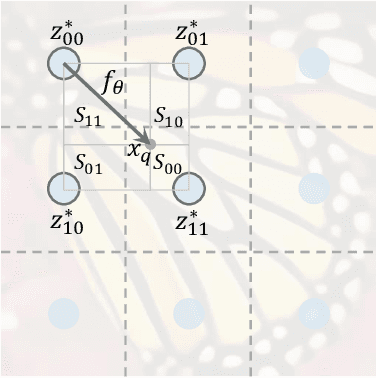
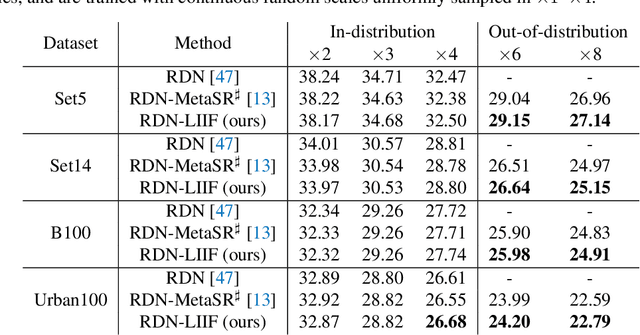
How to represent an image? While the visual world is presented in a continuous manner, machines store and see the images in a discrete way with 2D arrays of pixels. In this paper, we seek to learn a continuous representation for images. Inspired by the recent progress in 3D reconstruction with implicit function, we propose Local Implicit Image Function (LIIF), which takes an image coordinate and the 2D deep features around the coordinate as inputs, predicts the RGB value at a given coordinate as an output. Since the coordinates are continuous, LIIF can be presented in an arbitrary resolution. To generate the continuous representation for pixel-based images, we train an encoder and LIIF representation via a self-supervised task with super-resolution. The learned continuous representation can be presented in arbitrary resolution even extrapolate to $\times 30$ higher resolution, where the training tasks are not provided. We further show that LIIF representation builds a bridge between discrete and continuous representation in 2D, it naturally supports the learning tasks with size-varied image ground-truths and significantly outperforms the method with resizing the ground-truths. Our project page with code is at https://yinboc.github.io/liif/ .