 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Meta-Baseline for Few-Shot Learning
Paper and Code
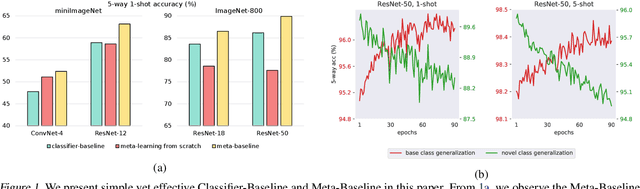
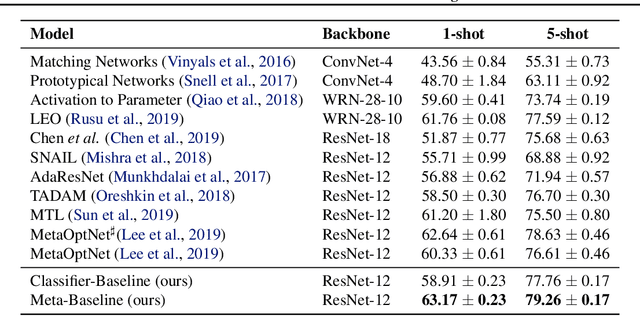
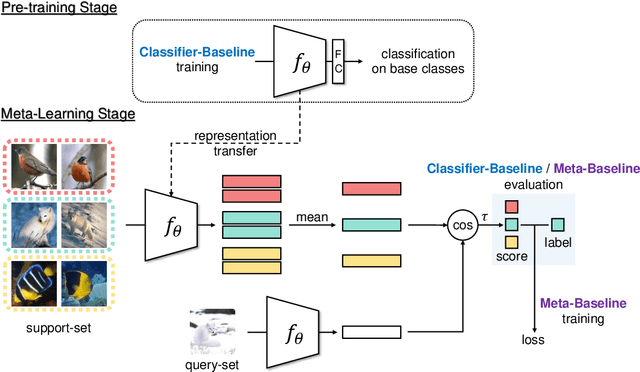
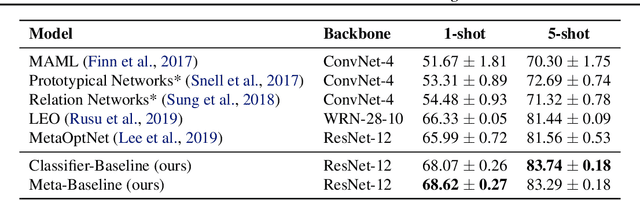
Meta-learning has become a popular framework for few-shot learning in recent years, with the goal of learning a model from collections of few-shot classification tasks. While more and more novel meta-learning models are being proposed, our research has uncovered simple baselines that have been overlooked. We present a Meta-Baseline method, by pre-training a classifier on all base classes and meta-learning on a nearest-centroid based few-shot classification algorithm, it outperforms recent state-of-the-art methods by a large margin. Why does this simple method work so well? In the meta-learning stage, we observe that a model generalizing better on unseen tasks from base classes can have a decreasing performance on tasks from novel classes, indicating a potential objective discrepancy. We find both pre-training and inheriting a good few-shot classification metric from the pre-trained classifier are important for Meta-Baseline, which potentially helps the model better utilize the pre-trained representations with stronger transferability. Furthermore, we investigate when we need meta-learning in this Meta-Baseline. Our work sets up a new solid benchmark for this field and sheds light on further understanding the phenomenons in the meta-learning framework for few-shot learning.