 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGME: Retrieval Augmented Video Generation for Enhanced Motion Realism
Apr 09, 2025



Video generation is experiencing rapid growth, driven by advances in diffusion models and the development of better and larger datasets. However, producing high-quality videos remains challenging due to the high-dimensional data and the complexity of the task. Recent efforts have primarily focused on enhancing visual quality and addressing temporal inconsistencies, such as flickering. Despite progress in these areas, the generated videos often fall short in terms of motion complexity and physical plausibility, with many outputs either appearing static or exhibiting unrealistic motion. In this work, we propose a framework to improve the realism of motion in generated videos, exploring a complementary direction to much of the existing literature. Specifically, we advocate for the incorporation of a retrieval mechanism during the generation phase. The retrieved videos act as grounding signals, providing the model with demonstrations of how the objects move. Our pipeline is designed to apply to any text-to-video diffusion model, conditioning a pretrained model on the retrieved samples with minimal fine-tuning. We demonstrate the superiority of our approach through established metrics, recently proposed benchmarks, and qualitative results, and we highlight additional applications of the framework.
Safe Vision-Language Models via Unsafe Weights Manipulation
Mar 14, 2025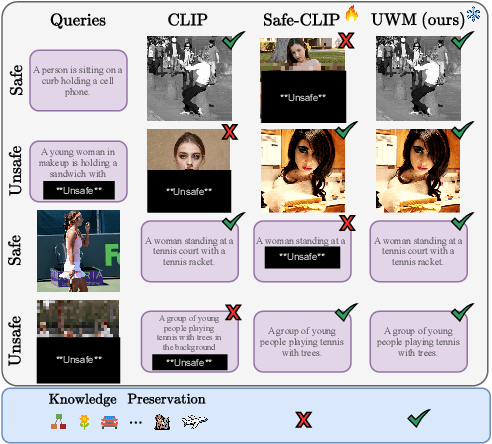



Vision-language models (VLMs) often inherit the biases and unsafe associations present within their large-scale training dataset. While recent approaches mitigate unsafe behaviors, their evaluation focuses on how safe the model is on unsafe inputs, ignoring potential shortcomings on safe ones. In this paper, we first revise safety evaluation by introducing SafeGround, a new set of metrics that evaluate safety at different levels of granularity. With this metric, we uncover a surprising issue of training-based methods: they make the model less safe on safe inputs. From this finding, we take a different direction and explore whether it is possible to make a model safer without training, introducing Unsafe Weights Manipulation (UWM). UWM uses a calibration set of safe and unsafe instances to compare activations between safe and unsafe content, identifying the most important parameters for processing the latter. Their values are then manipulated via negation. Experiments show that UWM achieves the best tradeoff between safety and knowledge preservation, consistently improving VLMs on unsafe queries while outperforming even training-based state-of-the-art methods on safe ones.
GradBias: Unveiling Word Influence on Bias in Text-to-Image Generative Models
Aug 29, 2024



Recent progress in Text-to-Image (T2I) generative models has enabled high-quality image generation. As performance and accessibility increase, these models are gaining significant attraction and popularity: ensuring their fairness and safety is a priority to prevent the dissemination and perpetuation of biases. However, existing studies in bias detection focus on closed sets of predefined biases (e.g., gender, ethnicity). In this paper, we propose a general framework to identify, quantify, and explain biases in an open set setting, i.e. without requiring a predefined set. This pipeline leverages a Large Language Model (LLM) to propose biases starting from a set of captions. Next, these captions are used by the target generative model for generating a set of images. Finally, Vision Question Answering (VQA) is leveraged for bias evaluation. We show two variations of this framework: OpenBias and GradBias. OpenBias detects and quantifies biases, while GradBias determines the contribution of individual prompt words on biases. OpenBias effectively detects both well-known and novel biases related to people, objects, and animals and highly aligns with existing closed-set bias detection methods and human judgment. GradBias shows that neutral words can significantly influence biases and it outperforms several baselines, including state-of-the-art foundation models. Code available here: https://github.com/Moreno98/GradBias.
UVMap-ID: A Controllable and Personalized UV Map Generative Model
Apr 22, 2024



Recently, diffusion models have made significant strides in synthesizing realistic 2D human images based on provided text prompts. Building upon this, researchers have extended 2D text-to-image diffusion models into the 3D domain for generating human textures (UV Maps). However, some important problems about UV Map Generative models are still not solved, i.e., how to generate personalized texture maps for any given face image, and how to define and evaluate the quality of these generated texture maps. To solve the above problems, we introduce a novel method, UVMap-ID, which is a controllable and personalized UV Map generative model. Unlike traditional large-scale training methods in 2D, we propose to fine-tune a pre-trained text-to-image diffusion model which is integrated with a face fusion module for achieving ID-driven customized generation. To support the finetuning strategy, we introduce a small-scale attribute-balanced training dataset, including high-quality textures with labeled text and Face ID. Additionally, we introduce some metrics to evaluate the multiple aspects of the textures. Finally, both quantitative and qualitative analyses demonstrate the effectiveness of our method in controllable and personalized UV Map generation. Code is publicly available via https://github.com/twowwj/UVMap-ID.
OpenBias: Open-set Bias Detection in Text-to-Image Generative Models
Apr 11, 2024



Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
VASE: Object-Centric Appearance and Shape Manipulation of Real Videos
Jan 04, 2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object's appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities. Further details, code and examples are available on our project page: https://helia95.github.io/vase-website/
Smooth Diffusion: Crafting Smooth Latent Spaces in Diffusion Models
Dec 07, 2023



Recently, diffusion models have made remarkable progress in text-to-image (T2I) generation, synthesizing images with high fidelity and diverse contents. Despite this advancement, latent space smoothness within diffusion models remains largely unexplored. Smooth latent spaces ensure that a perturbation on an input latent corresponds to a steady change in the output image. This property proves beneficial in downstream tasks, including image interpolation, inversion, and editing. In this work, we expose the non-smoothness of diffusion latent spaces by observing noticeable visual fluctuations resulting from minor latent variations. To tackle this issue, we propose Smooth Diffusion, a new category of diffusion models that can be simultaneously high-performing and smooth. Specifically, we introduce Step-wise Variation Regularization to enforce the proportion between the variations of an arbitrary input latent and that of the output image is a constant at any diffusion training step. In addition, we devise an interpolation standard deviation (ISTD) metric to effectively assess the latent space smoothness of a diffusion model. Extensive quantitative and qualitative experiments demonstrate that Smooth Diffusion stands out as a more desirable solution not only in T2I generation but also across various downstream tasks. Smooth Diffusion is implemented as a plug-and-play Smooth-LoRA to work with various community models. Code is available at https://github.com/SHI-Labs/Smooth-Diffusion.
Interactive Neural Painting
Jul 31, 2023



In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
Reference-based Painterly Inpainting via Diffusion: Crossing the Wild Reference Domain Gap
Jul 20, 2023
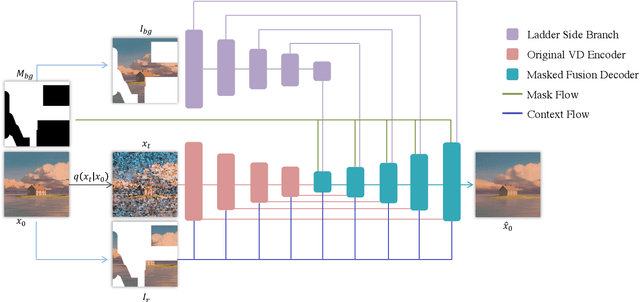


Have you ever imagined how it would look if we placed new objects into paintings? For example, what would it look like if we placed a basketball into Claude Monet's ``Water Lilies, Evening Effect''? We propose Reference-based Painterly Inpainting, a novel task that crosses the wild reference domain gap and implants novel objects into artworks. Although previous works have examined reference-based inpainting, they are not designed for large domain discrepancies between the target and the reference, such as inpainting an artistic image using a photorealistic reference. This paper proposes a novel diffusion framework, dubbed RefPaint, to ``inpaint more wildly'' by taking such references with large domain gaps. Built with an image-conditioned diffusion model, we introduce a ladder-side branch and a masked fusion mechanism to work with the inpainting mask. By decomposing the CLIP image embeddings at inference time, one can manipulate the strength of semantic and style information with ease. Experiments demonstrate that our proposed RefPaint framework produces significantly better results than existing methods. Our method enables creative painterly image inpainting with reference objects that would otherwise be difficult to achieve. Project page: https://vita-group.github.io/RefPaint/
Prompt-Free Diffusion: Taking "Text" out of Text-to-Image Diffusion Models
May 25, 2023



Text-to-image (T2I) research has grown explosively in the past year, owing to the large-scale pre-trained diffusion models and many emerging personalization and editing approaches. Yet, one pain point persists: the text prompt engineering, and searching high-quality text prompts for customized results is more art than science. Moreover, as commonly argued: "an image is worth a thousand words" - the attempt to describe a desired image with texts often ends up being ambiguous and cannot comprehensively cover delicate visual details, hence necessitating more additional controls from the visual domain. In this paper, we take a bold step forward: taking "Text" out of a pre-trained T2I diffusion model, to reduce the burdensome prompt engineering efforts for users. Our proposed framework, Prompt-Free Diffusion, relies on only visual inputs to generate new images: it takes a reference image as "context", an optional image structural conditioning, and an initial noise, with absolutely no text prompt. The core architecture behind the scene is Semantic Context Encoder (SeeCoder), substituting the commonly used CLIP-based or LLM-based text encoder. The reusability of SeeCoder also makes it a convenient drop-in component: one can also pre-train a SeeCoder in one T2I model and reuse it for another. Through extensive experiments, Prompt-Free Diffusion is experimentally found to (i) outperform prior exemplar-based image synthesis approaches; (ii) perform on par with state-of-the-art T2I models using prompts following the best practice; and (iii) be naturally extensible to other downstream applications such as anime figure generation and virtual try-on, with promising quality. Our code and models are open-sourced at https://github.com/SHI-Labs/Prompt-Free-Diffusion.