 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity 3D Facial Avatar Synthesis with Controllable Fine-Grained Expressions
Mar 16, 2026Facial expression editing methods can be mainly categorized into two types based on their architectures: 2D-based and 3D-based methods. The former lacks 3D face modeling capabilities, making it difficult to edit 3D factors effectively. The latter has demonstrated superior performance in generating high-quality and view-consistent renderings using single-view 2D face images. Although these methods have successfully used animatable models to control facial expressions, they still have limitations in achieving precise control over fine-grained expressions. To address this issue, in this paper, we propose a novel approach by simultaneously refining both the latent code of a pretrained 3D-Aware GAN model for texture editing and the expression code of the driven 3DMM model for mesh editing. Specifically, we introduce a Dual Mappers module, comprising Texture Mapper and Emotion Mapper, to learn the transformations of the given latent code for textures and the expression code for meshes, respectively. To optimize the Dual Mappers, we propose a Text-Guided Optimization method, leveraging a CLIP-based objective function with expression text prompts as targets, while integrating a SubSpace Projection mechanism to project the text embedding to the expression subspace such that we can have more precise control over fine-grained expressions. Extensive experiments and comparative analyses demonstrate the effectiveness and superiority of our proposed method.
Persistent Nonnegative Matrix Factorization via Multi-Scale Graph Regularization
Feb 26, 2026Matrix factorization techniques, especially Nonnegative Matrix Factorization (NMF), have been widely used for dimensionality reduction and interpretable data representation. However, existing NMF-based methods are inherently single-scale and fail to capture the evolution of connectivity structures across resolutions. In this work, we propose persistent nonnegative matrix factorization (pNMF), a scale-parameterized family of NMF problems, that produces a sequence of persistence-aligned embeddings rather than a single one. By leveraging persistent homology, we identify a canonical minimal sufficient scale set at which the underlying connectivity undergoes qualitative changes. These canonical scales induce a sequence of graph Laplacians, leading to a coupled NMF formulation with scale-wise geometric regularization and explicit cross-scale consistency constraint. We analyze the structural properties of the embeddings along the scale parameter and establish bounds on their increments between consecutive scales. The resulting model defines a nontrivial solution path across scales, rather than a single factorization, which poses new computational challenges. We develop a sequential alternating optimization algorithm with guaranteed convergence. Numerical experiments on synthetic and single-cell RNA sequencing datasets demonstrate the effectiveness of the proposed approach in multi-scale low-rank embeddings.
Angle-distance decomposition based on deep learning for active sonar detection
Jul 28, 2025



Underwater target detection using active sonar constitutes a critical research area in marine sciences and engineering. However, traditional signal processing methods face significant challenges in complex underwater environments due to noise, reverberation, and interference. To address these issues, this paper presents a deep learning-based active sonar target detection method that decomposes the detection process into separate angle and distance estimation tasks. Active sonar target detection employs deep learning models to predict target distance and angle, with the final target position determined by integrating these estimates. Limited underwater acoustic data hinders effective model training, but transfer learning and simulation offer practical solutions to this challenge. Experimental results verify that the method achieves effective and robust performance under challenging conditions.
Stable-Hair v2: Real-World Hair Transfer via Multiple-View Diffusion Model
Jul 10, 2025



While diffusion-based methods have shown impressive capabilities in capturing diverse and complex hairstyles, their ability to generate consistent and high-quality multi-view outputs -- crucial for real-world applications such as digital humans and virtual avatars -- remains underexplored. In this paper, we propose Stable-Hair v2, a novel diffusion-based multi-view hair transfer framework. To the best of our knowledge, this is the first work to leverage multi-view diffusion models for robust, high-fidelity, and view-consistent hair transfer across multiple perspectives. We introduce a comprehensive multi-view training data generation pipeline comprising a diffusion-based Bald Converter, a data-augment inpainting model, and a face-finetuned multi-view diffusion model to generate high-quality triplet data, including bald images, reference hairstyles, and view-aligned source-bald pairs. Our multi-view hair transfer model integrates polar-azimuth embeddings for pose conditioning and temporal attention layers to ensure smooth transitions between views. To optimize this model, we design a novel multi-stage training strategy consisting of pose-controllable latent IdentityNet training, hair extractor training, and temporal attention training. Extensive experiments demonstrate that our method accurately transfers detailed and realistic hairstyles to source subjects while achieving seamless and consistent results across views, significantly outperforming existing methods and establishing a new benchmark in multi-view hair transfer. Code is publicly available at https://github.com/sunkymepro/StableHairV2.
UVMap-ID: A Controllable and Personalized UV Map Generative Model
Apr 22, 2024



Recently, diffusion models have made significant strides in synthesizing realistic 2D human images based on provided text prompts. Building upon this, researchers have extended 2D text-to-image diffusion models into the 3D domain for generating human textures (UV Maps). However, some important problems about UV Map Generative models are still not solved, i.e., how to generate personalized texture maps for any given face image, and how to define and evaluate the quality of these generated texture maps. To solve the above problems, we introduce a novel method, UVMap-ID, which is a controllable and personalized UV Map generative model. Unlike traditional large-scale training methods in 2D, we propose to fine-tune a pre-trained text-to-image diffusion model which is integrated with a face fusion module for achieving ID-driven customized generation. To support the finetuning strategy, we introduce a small-scale attribute-balanced training dataset, including high-quality textures with labeled text and Face ID. Additionally, we introduce some metrics to evaluate the multiple aspects of the textures. Finally, both quantitative and qualitative analyses demonstrate the effectiveness of our method in controllable and personalized UV Map generation. Code is publicly available via https://github.com/twowwj/UVMap-ID.
Householder Projector for Unsupervised Latent Semantics Discovery
Jul 16, 2023



Generative Adversarial Networks (GANs), especially the recent style-based generators (StyleGANs), have versatile semantics in the structured latent space. Latent semantics discovery methods emerge to move around the latent code such that only one factor varies during the traversal. Recently, an unsupervised method proposed a promising direction to directly use the eigenvectors of the projection matrix that maps latent codes to features as the interpretable directions. However, one overlooked fact is that the projection matrix is non-orthogonal and the number of eigenvectors is too large. The non-orthogonality would entangle semantic attributes in the top few eigenvectors, and the large dimensionality might result in meaningless variations among the directions even if the matrix is orthogonal. To avoid these issues, we propose Householder Projector, a flexible and general low-rank orthogonal matrix representation based on Householder transformations, to parameterize the projection matrix. The orthogonality guarantees that the eigenvectors correspond to disentangled interpretable semantics, while the low-rank property encourages that each identified direction has meaningful variations. We integrate our projector into pre-trained StyleGAN2/StyleGAN3 and evaluate the models on several benchmarks. Within only $1\%$ of the original training steps for fine-tuning, our projector helps StyleGANs to discover more disentangled and precise semantic attributes without sacrificing image fidelity.
Training and Tuning Generative Neural Radiance Fields for Attribute-Conditional 3D-Aware Face Generation
Aug 26, 2022

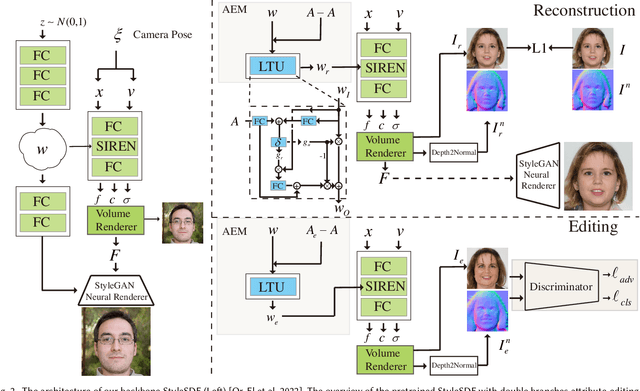

3D-aware GANs based on generative neural radiance fields (GNeRF) have achieved impressive high-quality image generation, while preserving strong 3D consistency. The most notable achievements are made in the face generation domain. However, most of these models focus on improving view consistency but neglect a disentanglement aspect, thus these models cannot provide high-quality semantic/attribute control over generation. To this end, we introduce a conditional GNeRF model that uses specific attribute labels as input in order to improve the controllabilities and disentangling abilities of 3D-aware generative models. We utilize the pre-trained 3D-aware model as the basis and integrate a dual-branches attribute-editing module (DAEM), that utilize attribute labels to provide control over generation. Moreover, we propose a TRIOT (TRaining as Init, and Optimizing for Tuning) method to optimize the latent vector to improve the precision of the attribute-editing further. Extensive experiments on the widely used FFHQ show that our model yields high-quality editing with better view consistency while preserving the non-target regions. The code is available at https://github.com/zhangqianhui/TT-GNeRF.
Unsupervised High-Resolution Portrait Gaze Correction and Animation
Jul 01, 2022



This paper proposes a gaze correction and animation method for high-resolution, unconstrained portrait images, which can be trained without the gaze angle and the head pose annotations. Common gaze-correction methods usually require annotating training data with precise gaze, and head pose information. Solving this problem using an unsupervised method remains an open problem, especially for high-resolution face images in the wild, which are not easy to annotate with gaze and head pose labels. To address this issue, we first create two new portrait datasets: CelebGaze and high-resolution CelebHQGaze. Second, we formulate the gaze correction task as an image inpainting problem, addressed using a Gaze Correction Module (GCM) and a Gaze Animation Module (GAM). Moreover, we propose an unsupervised training strategy, i.e., Synthesis-As-Training, to learn the correlation between the eye region features and the gaze angle. As a result, we can use the learned latent space for gaze animation with semantic interpolation in this space. Moreover, to alleviate both the memory and the computational costs in the training and the inference stage, we propose a Coarse-to-Fine Module (CFM) integrated with GCM and GAM. Extensive experiments validate the effectiveness of our method for both the gaze correction and the gaze animation tasks in both low and high-resolution face datasets in the wild and demonstrate the superiority of our method with respect to the state of the arts. Code is available at https://github.com/zhangqianhui/GazeAnimationV2
3D-Aware Semantic-Guided Generative Model for Human Synthesis
Dec 02, 2021
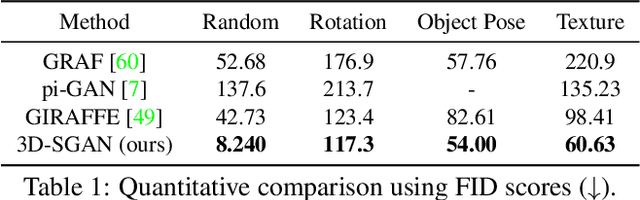
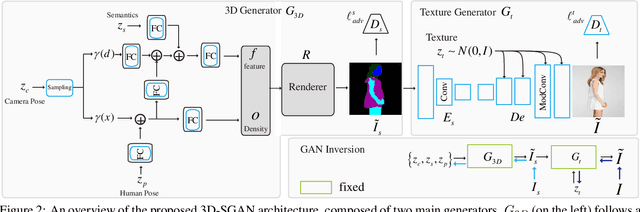
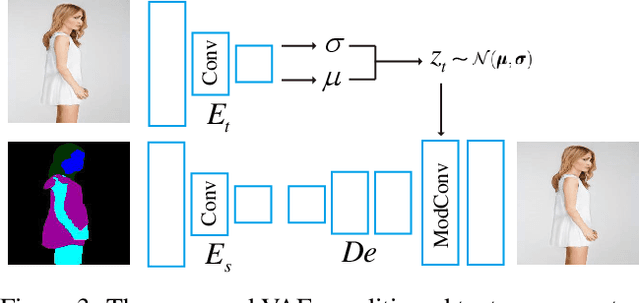
Generative Neural Radiance Field (GNeRF) models, which extract implicit 3D representations from 2D images, have recently been shown to produce realistic images representing rigid objects, such as human faces or cars. However, they usually struggle to generate high-quality images representing non-rigid objects, such as the human body, which is of a great interest for many computer graphics applications. This paper proposes a 3D-aware Semantic-Guided Generative Model (3D-SGAN) for human image synthesis, which integrates a GNeRF and a texture generator. The former learns an implicit 3D representation of the human body and outputs a set of 2D semantic segmentation masks. The latter transforms these semantic masks into a real image, adding a realistic texture to the human appearance. Without requiring additional 3D information, our model can learn 3D human representations with a photo-realistic controllable generation. Our experiments on the DeepFashion dataset show that 3D-SGAN significantly outperforms the most recent baselines.
Controllable Person Image Synthesis with Spatially-Adaptive Warped Normalization
Jun 03, 2021
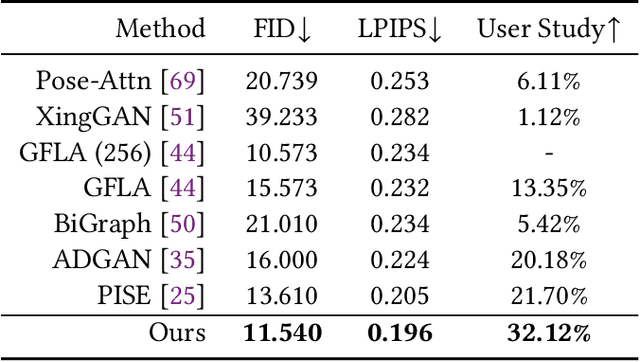

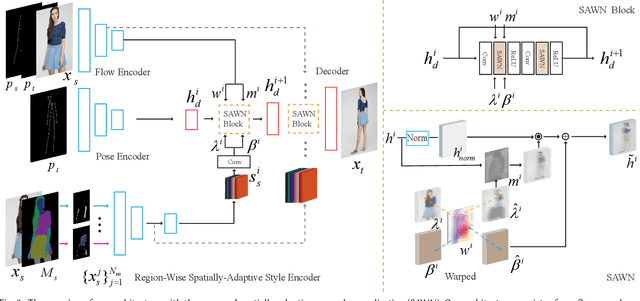
Controllable person image generation aims to produce realistic human images with desirable attributes (e.g., the given pose, cloth textures or hair style). However, the large spatial misalignment between the source and target images makes the standard architectures for image-to-image translation not suitable for this task. Most of the state-of-the-art architectures avoid the alignment step during the generation, which causes many artifacts, especially for person images with complex textures. To solve this problem, we introduce a novel Spatially-Adaptive Warped Normalization (SAWN), which integrates a learned flow-field to warp modulation parameters. This allows us to align person spatial-adaptive styles with pose features efficiently. Moreover, we propose a novel self-training part replacement strategy to refine the pretrained model for the texture-transfer task, significantly improving the quality of the generated cloth and the preservation ability of irrelevant regions. Our experimental results on the widely used DeepFashion dataset demonstrate a significant improvement of the proposed method over the state-of-the-art methods on both pose-transfer and texture-transfer tasks. The source code is available at https://github.com/zhangqianhui/Sawn.